- Линейная регрессия. Разбор математики и реализации на python
- Решаем задачу численного прогнозирования с помощью линейной регрессии на Python
- Постановка задачи и исходный датасет
- Линейная регрессия с одной независимой переменной
- Линейная регрессия в библиотеках statsmodel и seaborn
- Линейная регрессия с несколькими переменными в Scikit-learn
- Метрики качества для оценки работоспособности модели
Линейная регрессия. Разбор математики и реализации на python
Тема линейной регресии рассмотрена множество раз в различных источниках, но, как говорится, «нет такой избитой темы, которую нельзя ударить еще раз». В данной статье рассмотрим указанную тему, используя как математические выкладки, так и код python, пытаясь соблюсти баланс на грани простоты и должном уровне для понимания математических основ.
Линейная регрессия представляется из себя регриссионную модель зависимости одной (объясняемой, зависимой) переменной от другой или нескольких других переменных (фактров, регрессоров, независимых переменных) с линейной функцией зависимости. Рассмотрим модель линейной регрессии, при которой зависимая переменная зависит лишь от одного фактора, тогда функция, описывающуя зависимость y от x будет иметь следующий вид:
и задача сводится к нахождению весовых коэффициентов w0 и w1, таких что такая прямая максимально «хорошо» будет описывать исходные данные. Для этого зададим функцию ошибки, минимизация которой обеспечит подбор весов w0 и w1, используя метод наименьших квадратов:
или подставив уравнение модели
Минимизируем функцию ошибки MSE найдя частные производные по w0 и w1
И приравняв их к нулю получим систему уравнений, решение которой обеспечит минимизацию функции потерь MSE.
Раскроем сумму и с учетом того, что -2/n не может равняться нулю, приравняем к нулю вторые множители
Выразим w0 из первого уравнения
Подставив во второе уравнение решим относительно w1
И выразив w1 последнего уравнения получим
Задача решена, однако представленный способ слабо распространим на большое количество фичей, уже при появлении второго признака вывод становится достаточно громоздким, не говоря уже о большем количестве признаков.
Справиться с этой задачей нам поможет матричный способ представления функции потерь и ее минимизация путем дифференцирования и нахождения экстремума в матричном виде.
Предположим, что дана следующая таблица с данными
Для вычисления интерсепта (коэффициента w0) необходимо к таблице добавить столбец слева с фактором f0 все значения которого равны 1 (единичный вектор-столбец). И тогда столбцы f0-f3 (по количеству столбцов не ограничены, можно считать fn) можно выделить в матрицу X, целевую переменную в матрицу-столбец y, а искомые коэффициенты можно представить в виде вектора w.
можно представить в следующем виде
Представим в виде скалярного произведения < >и вычислим производную используя дифференциал
приведем формулу к следующему виду
Поскольку дифференциал разницы равен разнице дифференциалов, дифференциал константы (y) равен нулю и константу (в данном случае матрицу X) можно вынести за знак дифференциала, получим
Используя свойство скалярного произведения перенесем матрицу X справа налево незабыв транспонировать ее
Собственно, то что слева и есть дифференциал, найдем экстремум приравняв его к нулю и решив по параметрам w
раскроем скобки и перенесем значения без w вправо
Домножим слева обе стороны равенства на обратную матрицу произведения транспонированной матрицы X на X для выражения вектора w, тогда получим
Аналитическое решение получено, переходим к реализации на python.
#импорт необходимых библиотек import numpy as np from sklearn.linear_model import LinearRegression #зададим начальные условия f0 = np.array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) f1 = np.array([1.1, 2.1, 3.1, 4.4, 5.2, 6.4, 7.1, 8.2, 9.4, 10.5]) f2 = np.array([1.4, 2.3, 3.4, 4.1, 5.5, 6.2, 7.3, 8.4, 9.2, 10.1]) f3 = np.array([1.2, 2.2, 3.4, 4.2, 5.3, 6.2, 7.3, 8.4, 9.2, 10.3]) y = np.array([[1.2], [2.2], [3.3], [4.3], [5.2], [6.3], [7.2], [8.3], [9.3], [10.2]]) w = np.array([np.nan, np.nan, np.nan, np.nan]) X = np.array([f0, f1, f2, f3]).T #рассчитаем коэффициенты используя выведенную формулу coef_matrix = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), y) print(f'Коэффициенты рассчитанные по формуле ') #Коэффициенты рассчитанные по формуле [0.05994939 0.42839296 0.09249473 0.46642055] #проверим расчет используя библиотеку sklearn model = LinearRegression().fit(X, y) coef_sklearn = model.coef_.T coef_sklearn[0] = model.intercept_ print(f'Коэффициенты рассчитанные с использованием библиотеки sklearn ') #Коэффициенты полученные с рассчитанные библиотеки sklearn [0.05994939 0.42839296 0.09249473 0.46642055]Надеюсь эта статья помогла заглянуть под капот одного из базовых методов машинного обучения — линейной регрессии и станет первой ступенью в этот увлекательный мир: математика машинного обучения.
Решаем задачу численного прогнозирования с помощью линейной регрессии на Python
Задача регрессии возникает, когда требуется предсказать цену, температура, пульс, время, давление или другое численный показатель. Это пример контролируемого (supervised) машинного обучения, когда на основе истории предыдущих данных мы получаем предсказание. В этой статье обсудим, как можно спрогнозировать будущее, решая задачу линейной регрессии на Python.
Постановка задачи и исходный датасет
Продолжим работу с датасетом нью-йоркских апартаментов (отелей), доступных для проживания на некоторое время. Для дальнейшего анализа возьмем район Бруклин:
import pandas as pd data = pd.read_csv('../AB_NYC_2019.csv') data = data[data['neighbourhood_group'] == 'Brooklyn'] На этом наборе данных будем прогнозировать цены, по которым можно арендовать отдельные аппартаменты.
Линейная регрессия с одной независимой переменной
Графически линейная регрессия с одной независимой выглядит как прямая. Она решает задачу регрессии нахождением прямой, которая наилучшим образом соответствует точкам наблюдений. Следующий рисунок иллюстрирует вышесказанное:
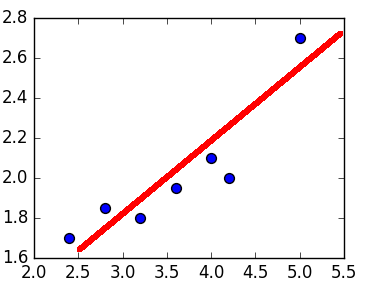
Модель линейной регрессии может быть задана следующим образом:
Следовательно, для решения задачи регрессии требуется найти коэффициенты (коэффициент наклона) и (точка пересечения линии с осью ординат). Не вдаваясь в подробности, их можно выразить так:
![\[ a=\frac<\sum(x-\bar<x></noscript></p><p>)(y-\bar)><\sum(x-\bar<x>)^2> \]» width=»164″ height=»43″/></p><p><img decoding=](https://python-school.ru/wp-content/ql-cache/quicklatex.com-ce7eea517462090da3e4aa2d9f5be9f5_l3.png)
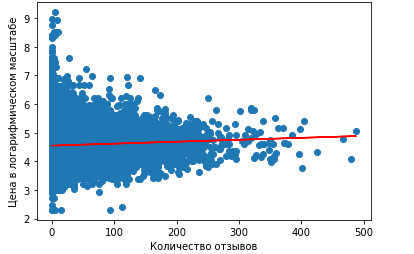
Как можно заметить, линейная регрессия с одной независимой переменной показывает неудачные результаты, так как является практически параллельной оси абсцисс. Поэтому предсказание будет одним и тем же, примерно равным 4.6. При переводе обратно в нормальный масштаб равняется $100.
Линейная регрессия в библиотеках statsmodel и seaborn
Чтобы получить линейную регрессию, Data Scientist, который работает с Python, может воспользоваться готовыми библиотеками, а не писать собственное решение. Например, отлично подойдет библиотека Statsmodel, о которой мы уже говорили здесь. Она позволит получить линейную регрессию очень быстро:
import statsmodels.formula.api as smf model = smf.ols('price ~ number_of_reviews', data=data) res = model.fit() res.summary() Метод summary выдает резюме после вычислений линейной регрессии по методу наименьших квадратов. Но нас интересуют коэффициенты и , которые в данном случае равны:

Как видим, intercept — это , number_of reviews , — это , что соответствуют прошлым вычислениям.
Помимо Statsmodel, можно воспользоваться библиотекой Seaborn, которая также часто применяется в задачах Machine Learning и других методах Data Science. Она имеет функцию regplot , которая сразу построит соответствующую прямую:
import seaborn as sns sns.regplot(x, y)
Линейная регрессия с несколькими переменными в Scikit-learn
В действительности ML-модели редко обучаются только на одном признаке, что подтверждают построенные графики. Поэтому уравнение для линейной регрессии можно обобщить до переменных (признаков):
![\[ y = ax_1 + ax_2 \dots + \dots + ax_n \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-a76fa97ac86f43f49f95dac412a3cbb6_l3.png)
где задача сводится к нахождению коэффициентов. Не вдаваясь в подробности их нахождения, отметим, что Python-библиотека Scikit-learn предоставляет для этого уже готовый интерфейс.
Рассмотрим пример в Python. Выберем в качестве независимых переменных признаки: number_of_reviews , reviews_per_month , calculated_host_listings_count . Атрибут reviews_per_month имеет Nan-значения, поэтому в дальнейшем заполним их нулями. К тому же, мы отфильтровали те данные, которые имеют нулевую цену:
d = data[data.price > 0] d['reviews_per_month'].fillna(0, inplace=True) x = d.loc[:, ('reviews_per_month', 'calculated_host_listings_count', 'number_of_reviews')] y = d.loc[:, 'price'] Здесь используется метод loc , который, согласно документации, быстрее и производительнее явного вызова столбцов [1]. Нам также требуется разбить полученные данные на тренировочную и тестовую выборки, чтобы на одних данных обучить модель, а на других – проверить ее корректность. В Scikit-learn имеется функция train_test_split , возвращающая две пары массивов — тренировочного и тестового:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
Данная функция принимает в качестве аргумента также test_size , который определяет долю, отведенную на тестовую выборку.
Теперь к самому главному — обучению модели линейной регрессии. В Scikit-learn есть класс LinearRegression , который выполнит за нас работу в Python:
from sklearn.linear_model import LinearRegression model = LinearRegression().fit(x_train, y_train)
В метод fit мы посылаем те данные, на которых ML-модель обучается. Попробуем получить предсказания на основе тестовой выборки:
y_pred = model.predict(x_test)
А как узнать, что такая модель лучшая из всех доступных? Нужно воспользоваться метриками качества.
Метрики качества для оценки работоспособности модели
Чтобы оценить работоспособность модели, применяют специальные метрики. Для задачи регрессии применяют среднеквадратическую (MSE) и абсолютную ошибки (MAE). Среднеквадратическая ошибка находится как:
![\[ MSE = \frac<1></noscript>\sum(y-y_)^2 \]» width=»201″ height=»36″/></p><p>Абсолютная опускает возведение в квадрат:</p><p><img decoding=](https://python-school.ru/wp-content/ql-cache/quicklatex.com-da5ba05efb6b7b54d19b0c69bf78689c_l3.png)