- Объясните как работает метод super,а так-же конструкция super().__init__() в python? [закрыт]
- 1 ответ 1
- Необычный Python в обычных библиотеках
- Вызов super() в базовых классах
- Когда использовать миксины?
- Использование относительного импорта
- Когда добавлять код в __init__.py
- Когда использовать экземпляр, класс и статические методы
- Скрытая функция conftest.py
- Поясняющая документация библиотек
Объясните как работает метод super,а так-же конструкция super().__init__() в python? [закрыт]
Хотите улучшить этот вопрос? Переформулируйте вопрос так, чтобы он был сосредоточен только на одной проблеме.
Объясните как работает метод super , а так-же конструкция super().__init__() в python? super часто используется в классах. Желательно объяснить как можно проще и на простых примерах.
Отличный ответ но гуглом я умею пользоваться.Читаю и разбираюсь но на данный момент понять не могу, сюда написал затем,что-бы может у кого нибудь получилось объяснить.
1 ответ 1
super() — это функция, которая обращается к классу, от которого наследуется текущий.
class A: def some_method(self): print('Spam, eggs!!1') class B(A): def some_method(self): print('Hello, World!') x = B() x.some_method() Как Вы можете заметить, мы перегрузили метод родительского класса. Но что, если нам потребуется всего лишь немного дополнить его? Как нам дополнить родительский метод, не копируя его полностью и не изобретая велосипедов? Тут нам и нужен super() :
class A: def some_method(self): print('Spam, eggs!!1') class B(A): def some_method(self): super().some_method() print('Hello, World!') x = B() x.some_method() С помощью super().some_method() мы вызвали родительский метод, а после дополнили свой. Именно для этого чаще всего используется эта функция.
__init__() — это метод инициализации класса, следовательно super().__init__() вызывает метод инициализации из родительского класса. Например, чтобы дополнить его.
Необычный Python в обычных библиотеках

Специалист в Data Science из Amazon буквально прочитал код самых распространённых библиотек Python. В этом материале он делится секретами работы с Python, о которых узнал из этих библиотек. За подробностями приглашаем под кат к старту нашего флагманского курса по Data Science:
Вызов super() в базовых классах
Функция super() в Python позволяет наследовать базовые классы (они же суперклассы или родительские классы) без необходимости явно ссылаться на базовый класс. Обычно метод super() используется в методе __init__ . Множественное наследование практически невозможно без super() , хотя оно может быть удобно при одиночном наследовании.
Одно из интересных применений super() — его вызов в классе базовом классе. Этот приём я заметил в requests.adapters, в BaseAdapter :
class BaseAdapter: """The Base Transport Adapter""" def __init__(self): super().__init__() def send(self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None): Базовый класс ни от чего не наследуется, так зачем же вызывать в нём super() ?
Немного покопавшись, я узнал вот что: в базовом классе ключевое слово super() позволяет реализовать совместное множественное наследование. Без него вызовы __init__ родительских классов — после класса без super — пропускаются. Ниже — пример с базовым классом BaseEstimator и миксином ServingMixin , где DecisionTree унаследует оба класса.
Итак, у нас BaseEstimator , который в своём __init__ не вызывает super() . Для вывода атрибутов у него есть базовый метод __repr__ :
class BaseEstimator: def __init__(self, name, **kwargs): self.name = name def __repr__(self): return f', '.join(f': ' for k, v in vars(self).items()) Затем мы наследуем BaseEstimator через подкласс DecisionTree . Всё работает нормально — при печати экземпляра DecisionTree отображаются атрибуты BaseEstimator и DecisionTree :
class DecisionTree(BaseEstimator): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depth dt = DecisionTree(name='DT', depth=1) print(dt) > name: DT, depth: 1 Теперь пронаследуемся от ServingMixin и создадим экземпляр DecisionTree :
class ServingMixin: def __init__(self, mode, **kwargs): super().__init__(**kwargs) self.mode = mode class DecisionTree(BaseEstimator, ServingMixin): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depth dt = DecisionTree(name='Request Time DT', depth=1, mode='online') print(dt) > name: Request Time DT, depth: 1 dt.mode > AttributeError: 'DecisionTree' object has no attribute 'mode' Заметно, что ServingMixin не наследуется должным образом: атрибут ServingMixin ( mode ) не отображается, когда выводится экземпляр дерева решений, и, если мы пытаемся получить доступ к атрибуту mode , то окажется, что он не существует.
Это связано с тем, что без super() в BaseEstimator класс DecisionTree не вызывает следующий родительский класс в порядке разрешения методов.
Исправить это можно вызовом super() в BaseEstimator , и DecisionTree заработает, как ожидалось:
class BaseEstimator: def __init__(self, name, **kwargs): self.name = name super().__init__(**kwargs) def __repr__(self): return f', '.join(f': ' for k, v in vars(self).items()) class ServingMixin: def __init__(self, mode, **kwargs): super().__init__(**kwargs) self.mode = mode class DecisionTree(BaseEstimator, ServingMixin): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depth dt = DecisionTree(name='Request Time DT', depth=1, mode='online') print(dt) > name: Request Time DT, mode: online, depth: 1 dt.mode > 'online' Именно поэтому мы можем захотеть вызвать super() в базовом классе.
Когда использовать миксины?
Mixin — это класс, предоставляющий реализации методов для повторного использования дочерними классами. Он представляет ограниченную форму множественного наследования и родительский класс, который просто даёт функциональные возможности подклассам, не содержит состояния и не предназначен для создания экземпляров. Scikit-learn широко использует миксины. Это ClassifierMixin , TransformerMixin , OutlierMixin и т. д.
Когда использовать миксины? Они подходят, когда хочется:
- предоставить множество дополнительных функций для класса;
- использовать определённую функцию во множестве разных классов.
from werkzeug import BaseRequest class Request(BaseRequest): pass Если нужно добавить поддержку заголовка accept , перепишем код вот так:
from werkzeug import BaseRequest, AcceptMixin class Request(AcceptMixin, BaseRequest): pass Нужна поддержка пользовательского агента, аутентификации и т. д.? Нет проблем, просто добавьте миксины:
from werkzeug import BaseRequest, AcceptMixin, UserAgentMixin, AuthenticationMixin class Request(AcceptMixin, UserAgentMixin, AuthenticationMixin, BaseRequest): pass Благодаря модуляризации этих функций в виде миксинов (а не добавления в класс) базовый класс не раздувается функциями, которые могут использовать только несколько подклассов. Кроме того, эти миксины теперь могут повторно использоваться другими дочерними классами, которые могут не наследоваться от BaseRequest .
Использование относительного импорта
Относительный импорт гарантирует, что мы ищем текущий пакет (и импортируем из него) перед поиском в остальной части PYTHONPATH . Он работает, если перед импортом поставить . — вот пример из base.py от Sklearn:
from .utils.validation import check_X_y from .utils.validation import check_array Что произойдёт, если base.py не использует относительный импорт? Если у нас есть пакет с именем utils в каталоге нашего скрипта, во время импорта Python будет искать наш пакет utils , а не utils от sklearn, тем самым нарушая работу sklearn. Точка в выражении импорта гарантирует, что base.py в sklearn сначала ищет utils от Sklearn.
Есть ли другая причина не использовать относительный импорт? Пожалуйста, оставьте комментарий ниже.
Когда добавлять код в __init__.py
__init__.py помечает каталоги как каталоги пакетов Python. Обычная практика — оставлять __init__.py пустыми. Тем не менее во многих библиотеках, которые я читал, были непустые, а иногда длинные файлы __init__.py . Это заставило меня задуматься, что и почему можно добавить в __init__.py .
Во-первых, мы можем добавить в __init__.py импорт, когда хотим реорганизовать код, который вырос в несколько модулей, без критических изменений для существующих пользователей. Допустим, у нас есть один модуль ( models.py ), который содержит реализацию для DecisionTree и Bandit . Со временем этот единственный модуль превращается в пакет моделей с модулями для tree и bandit . Чтобы обеспечить согласованность API для существующих пользователей, в __init__.py в пакете моделей мы можем добавить следующее:
from .tree import DecisionTree, RandomForest from .bandit import Bandit, TSBandit Это гарантирует, что существующие пользователи смогут продолжить импорт через from models import DecisionTree , а не from models.tree import DecisionTree . Для них API не меняется, а существующий код не ломается.
Это подводит к ещё одной причине добавить код в __init__.py , а именно — предоставить упрощённый API, чтобы пользователям не приходилось вникать в детали реализации:
app __init__.py model_implementation.py data_implementation.py Вместо того чтобы заставлять пользователей решать, что импортировать из model_implementation и data_implementation , мы можем всё упростить, добавив в __init__.py такой код:
from .model_implementation import SimpleModel from .data_implementation import SimpleDataLoader В нём говорится, что SimpleModel и SimpleDataLoader — единственные части приложения, с которыми должны работать пользователи, и это упрощает использование пакета приложения (например, from app import SimpleModel, SimpleDataLoader ). И, если пользователи знают, что делают, и хотят импортировать напрямую из model_implementation , то это тоже возможно.
Так делается в Pandas, где __init__.py импортируются типы данных, считыватели (reader) и API изменения формы, а ещё так делается в Accelerate от Hugging Face.
Помимо упомянутого выше применения, мы также можем захотеть:
- инициализировать логгер в __init__.py основного пакета, чтобы использовать его в нескольких модулях;
- выполнить проверки совместимости.
Когда использовать экземпляр, класс и статические методы
Краткий обзор методов, которые можно реализовать для класса. Такие методы пригодятся, когда:
- Методам экземпляра нужен экземпляр класса, и доступ к нему они могут получить через self .
- Методам класса не нужен экземпляр. Таким образом, они не могут получить доступ к экземпляру ( self ), но им доступен к класс cls
- Статические методы не имеют доступа к self или cls . Они работают как обычные функции, но относятся к пространству имён классов.
Методы класса используются, когда хочется вызвать его, но не создавать его экземпляр. Обычно это происходит, когда не нужна информация об экземпляре, но нужна информация о классе (т. е. о другом его классе или статических методах). Методы класса можно использовать как конструктор. Преимущество методов класса заключается в том, что класс не нужно хардкодить, также они позволяют подклассам работать с методами.
Статические методы используются, когда нам не нужны аргументы класса или экземпляра, но некий метод связан с классом и удобно, чтобы этот метод находился в пространстве имён класса. Это могут быть специфичные для класса служебные методы. Оформляя метод как статический, мы улучшаем читаемость и понимание кода, сообщаем, что метод не зависит от класса или экземпляра.
Скрытая функция conftest.py
Обычно conftest.py используется для предоставления фикстур для всего каталога. После определения фикстуры в conftest.py , они могут использоваться любым тестом в пакете без необходимости импортировать их. Этот файл также используется для загрузки внешних плагинов и определения хуков, как setup и teardown.
Но, просматривая sklearn, я наткнулся на пустой conftest.py с этим интересным комментарием:
# Даже если этот файл пустой, он полезен тем, что при запуске из корневой папки # ./sklearn добавляется в sys.path с помощью pytest. Смотрите # https://docs.pytest.org/en/latest/explanation/pythonpath.html. # Например, это позволяет создавать расширения на месте и запускать pytest # doc/modules/clustering.rst, а также использовать sklearn из локальной папки, а не только из site-packages. Оказывается, sklearn использовал менее известную функцию conftest.py : его существование в корневом пути гарантирует, что pytest распознает модули без необходимости указывать PYTHONPATH . В фоновом режиме pytest изменяет sys.path , включая все найденные в корневом пути подмодули.
Поясняющая документация библиотек
Помимо чтения кода, мы можем учиться, читая документы, объясняющие библиотеку. Давайте сосредоточимся на принципах проектирования библиотек.
- согласованность: все объекты имеют общий согласованный интерфейс из ограниченного набора методов;
- композицию, когда, где это возможно, объекты реализуются с помощью существующих строительных блоков.
Другой пример — fastai, где используется многоуровневый подход. Фреймворк предоставляет высокоуровневый API, готовые к использованию функции обучения моделей для различных приложений. Высокоуровневый API построен на основе иерархии низкоуровневых API, последние предоставляют компонуемые стандартные блоки. Этот многоуровневый подход позволяет через настройку API-интерфейсов среднего уровня быстро создать прототип перед его кастомизацией.
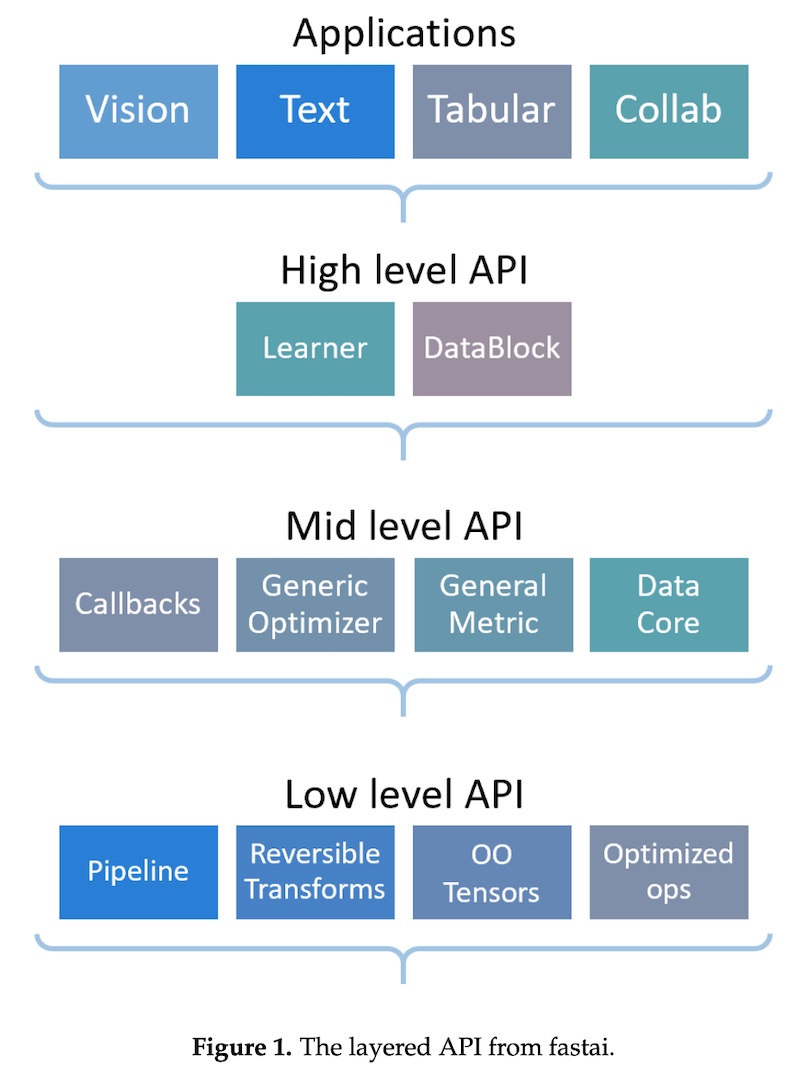
Вот некоторые необычные способы работы с Python, о которых я узнал, читая эти билиотеки:

А мы поможем прокачать ваши навыки или с самого начала освоить профессию, востребованную в любое время: