- YOLO Object Detection with OpenCV and Python
- What is YOLO exactly?
- OpenCV dnn module
- Let’s get started ..
- Summary
- Object Detection from Webcams with YOLO using Python
- Installing the Required Libraries
- Detect and Display Objects in Live Webcam Streams
- Step 1: Creating an Object of the Object Detection Class
- Step 2: Set and Load the YOLO Model
- Step 3: Capture Webcam Stream and Create Frames for Displaying Detected objects
- Save Detected Objects from Webcam Streams in a Video File
- Step 1: Creating Object of the VideoObjectDetection Class
- Step 2: Setting and Loading the YOLO Model
- Step 3: Detecting Objects from Camera and Saving to Video File
YOLO Object Detection with OpenCV and Python
If you have been keeping up with the advancements in the area of object detection, you might have got used to hearing this word ‘YOLO’. It has kind of become a buzzword.
What is YOLO exactly?
YOLO (You Only Look Once) is a method / way to do object detection. It is the algorithm /strategy behind how the code is going to detect objects in the image.
The official implementation of this idea is available through DarkNet (neural net implementation from the ground up in C from the author). It is available on github for people to use.
Earlier detection frameworks, looked at different parts of the image multiple times at different scales and repurposed image classification technique to detect objects. This approach is slow and inefficient.
YOLO takes entirely different approach. It looks at the entire image only once and goes through the network once and detects objects. Hence the name. It is very fast. That’s the reason it has got so popular.
There are other popular object detection frameworks like Faster R-CNN and SSD that are also widely used.
In this post, we are going to look at how to use a pre-trained YOLO model with OpenCV and start detecting objects right away.
OpenCV dnn module
DNN (Deep Neural Network) module was initially part of opencv_contrib repo. It has been moved to the master branch of opencv repo last year, giving users the ability to run inference on pre-trained deep learning models within OpenCV itself.
(One thing to note here is, dnn module is not meant be used for training. It’s just for running inference on images/videos.)
Initially only Caffe and Torch models were supported. Over the period support for different frameworks/libraries like TensorFlow is being added.
Support for YOLO/DarkNet has been added recently. We are going to use the OpenCV dnn module with a pre-trained YOLO model for detecting common objects.
Let’s get started ..
Enough of talking. Let’s start writing code. (in Python obviously)
Finally we look at the detections that are left and draw bounding boxes around them and display the output image.
Summary
In this post, we looked at how to use OpenCV dnn module with pre-trained YOLO model to do object detection. We have only scratched the surface. There is lot more to object detection.
We can also train a model to detect objects of our own interest that are not covered in the pre-trained one. I will be covering more on object detection in the future including other frameworks like Faster R-CNN and SSD. Be sure to subscribe to my blog to get notified when new posts are published.
That’s all for now. Thanks for reading. I hope this post was useful to get started with object detection. Feel free to share your thoughts in the comments or you can reach out to me on twitter @ponnusamy_arun.
Object Detection from Webcams with YOLO using Python
In a couple recent tutorials, we explained how to detect objects from images, and how to detect objects from videos with the YOLO algorithm using the Python imagei library.
In this article, we’ll build on the concepts explained in those tutorials, and we’ll explain how you can detect objects from live feeds, like cameras and webcams using the same YOLO algorithm. Just like last time, we’ll be using the YOLO implementation from Python’s imageai library for object detection.
Installing the Required Libraries
We’ll need to first install the following libraries required to execute scripts in this tutorial.
- The imageai library that implements the YOLO algorithm
- The openCV library which the imageai library uses behind the scenes to create bounding boxes
- The Pillow library that we’ll use to display images
- The NumPy library is used to store data from each frame of our webcame into an array
! pip install imageAI ! pip install opencv-python ! pip install Pillow ! pip install numpyDetect and Display Objects in Live Webcam Streams
In this section, we’ll show you how you can detect objects from live webcam streams and simultaneously display the detected objects.
To do so, you need to perform the following steps. These steps are very similar to the steps we used when detecting objects from images.
Step 1: Creating an Object of the Object Detection Class
The following script imports the ObjectDetection class
from imageai.Detection import ObjectDetectionThe script below creates an object of the object detection class.
obj_detect = ObjectDetection()Step 2: Set and Load the YOLO Model
The next step is to set the model type for object detection. Since we’ll be using the YOLO algorithm, you need to call the setModelTypeAsYOLOv3() method as shown in the script below:
obj_detect.setModelTypeAsYOLOv3()The next step is to load the actual Yolo model. The Yolo model the imageai library uses for object detection is available at the following Github Link. Download the yolo.h5 model from the above link.
To load the model, first you need to call the setModelPath() method from your ObjectDetection class object and pass it the path where you downloaded the yolo.h5 model. Next, you need to call the loadModel() method to actually load the model. Look at the following script for reference:
obj_detect.setModelPath(r"C:/Datasets/yolo.h5") obj_detect.loadModel()Step 3: Capture Webcam Stream and Create Frames for Displaying Detected objects
The next step is to capture your webcam stream. To do so, execute the script below:
import cv2 cam_feed = cv2.VideoCapture(0)The VideoCapture() method from the OpenCV library is used to capture live feeds from cameras attached to your computer. You need to pass the id for the camera to the VideoCapture() method. Passing 0 as the id value captures the live feed from your default webcam. The VideoCapture() method returns an object which contains frames detected from your live feed.
Next, you need to define height and width for the frame that will display the detected objects from your live feed. Execute the following script to do so, recognizing you can change the integer values near the end to match your desired dimensions:
cam_feed.set(cv2.CAP_PROP_FRAME_WIDTH, 650) cam_feed.set(cv2.CAP_PROP_FRAME_HEIGHT, 750)You are now ready to detect objects from your live webcam stream. We’re going to show what appears to be a complicated script below so let me explain it first. The script executes a while loop. Inside the while loop, the read() method from the object returned by the VideoCapture() reads the next frame captured by the webcam.
The captured frame is then passed to the input_image attribute of the detectObjectsFromImage() method of the ObjectDetection class. The value for the input_type attribute is set to “array” since the frames captured using the read() method are numpy arrays. Similarly, the output_type attribute is also set to “array” since the detectObjectsFromImage() method returns frames containing our detected objects, which are also essentially numpy arrays.
The frame returned by the detectObjectsFromImage() method is then passed to the imshow() method of the OpenCV module which displays the current frame containing our detected objects. This is what shows each frame of your video on your screen in real-time. The process continues until you press the “q” or “ESC” key on your keyboard.
while True: ret, img = cam_feed.read() annotated_image, preds = obj_detect.detectObjectsFromImage(input_image=img, input_type="array", output_type="array", display_percentage_probability=False, display_object_name=True) cv2.imshow("", annotated_image) if (cv2.waitKey(1) & 0xFF == ord("q")) or (cv2.waitKey(1)==27): break cam_feed.release() cv2.destroyAllWindows()Once you execute the script above, a window will appear displaying the live video feed from your webcam, along with the objects detected in each frame. Here’s a screenshot of output for your reference.
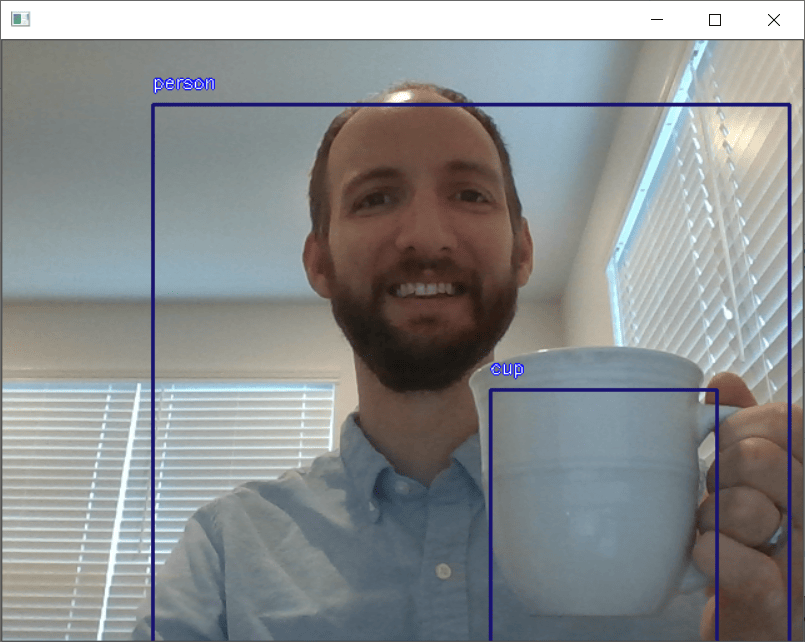
You can see from the output that a person and a cup were successfully detected.
Get Our Python Developer Kit for Free
I put together a Python Developer Kit with over 100 pre-built Python scripts covering data structures, Pandas, NumPy, Seaborn, machine learning, file processing, web scraping and a whole lot more — and I want you to have it for free. Enter your email address below and I’ll send a copy your way.
Save Detected Objects from Webcam Streams in a Video File
In addition to detecting and displaying objects from live feeds, like webcams, in window frames, you can also save objects detected from live feeds to a video file.
This process is very similar to the steps we took when applying YOLO to videos in our tutorial explaining how to detect objects from videos. The only major difference is that instead of passing the path of the input video file to the input_file_path attribute of the detectObjectsFromVideo() method explained in that tutorial, you need to pass the object that captures live camera feed to the camera_input field.
Let’s briefly revisit those steps here.
Step 1: Creating Object of the VideoObjectDetection Class
The first step is to import the VideoObjectDetection class, like this:
from imageai.Detection import VideoObjectDetectionThe script below creates an object of the VideoObjectDetection class:
vid_obj_detect = VideoObjectDetection()Step 2: Setting and Loading the YOLO Model
Next, you have to set the model type for object detection from videos, just like you did in the last section.
vid_obj_detect.setModelTypeAsYOLOv3()The following script sets the path to the YOLO model and loads the model.
vid_obj_detect.setModelPath(r"C:/Datasets/yolo.h5") vid_obj_detect.loadModel()Step 3: Detecting Objects from Camera and Saving to Video File
Here you can see that the only change from the script we used to detect objects from videos is the presence of the camera_input attribute whose value is equal to the camera object that captures your webcam stream. Also, the detection_timeout attribute is set to 3 which means that the function detectObjectsFromVideo() will terminate after detecting objects for 3 seconds from your input camera stream.
detected_vid_obj = vid_obj_detect.detectObjectsFromVideo( camera_input=cam_feed, output_file_path = r"C:/Datasets/output_video", frames_per_second=15, log_progress=True, return_detected_frame = True, detection_timeout=3 ) print(detected_vid_obj) )Once you run the script above, you will see that a video file named output_video.avi will be stored at the path specified by the “output_file_path” attribute. If you run the video, you’ll see that it contains annotated objects. We set our frames per second to 15, but you can bump it up closer to 30 if you’d like.
Object detection with Python is really a lot of fun and there are so many ways to do it. Tensorflow, pyTorch and OpenCV all allow you to detect objects in images and videos. Whichever method you use, object detection opens up a wide range of real-world applications. For example, with live video object detection, you can detect eagles as they approach wind turbines and slow the rotation of the blades. There are thousands of use cases for live stream object detection. If you want to know more about Python object detection, subscribe using the form below!
Get Our Python Developer Kit for Free
I put together a Python Developer Kit with over 100 pre-built Python scripts covering data structures, Pandas, NumPy, Seaborn, machine learning, file processing, web scraping and a whole lot more — and I want you to have it for free. Enter your email address below and I’ll send a copy your way.