pandas.DataFrame.to_excel#
DataFrame. to_excel ( excel_writer , sheet_name = ‘Sheet1’ , na_rep = » , float_format = None , columns = None , header = True , index = True , index_label = None , startrow = 0 , startcol = 0 , engine = None , merge_cells = True , inf_rep = ‘inf’ , freeze_panes = None , storage_options = None , engine_kwargs = None ) [source] #
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters : excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default ‘Sheet1’
Name of sheet which will contain DataFrame.
na_rep str, default ‘’
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, ‘openpyxl’ or ‘xlsxwriter’. You can also set this via the options io.excel.xlsx.writer or io.excel.xlsm.writer .
merge_cells bool, default True
Write MultiIndex and Hierarchical Rows as merged cells.
inf_rep str, default ‘inf’
Representation for infinity (there is no native representation for infinity in Excel).
freeze_panes tuple of int (length 2), optional
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
Arbitrary keyword arguments passed to excel engine.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
>>> df1 = pd.DataFrame([['a', 'b'], ['c', 'd']], . index=['row 1', 'row 2'], . columns=['col 1', 'col 2']) >>> df1.to_excel("output.xlsx")
To specify the sheet name:
>>> df1.to_excel("output.xlsx", . sheet_name='Sheet_name_1')
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
>>> df2 = df1.copy() >>> with pd.ExcelWriter('output.xlsx') as writer: . df1.to_excel(writer, sheet_name='Sheet_name_1') . df2.to_excel(writer, sheet_name='Sheet_name_2')
ExcelWriter can also be used to append to an existing Excel file:
>>> with pd.ExcelWriter('output.xlsx', . mode='a') as writer: . df1.to_excel(writer, sheet_name='Sheet_name_3')
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
>>> df1.to_excel('output1.xlsx', engine='xlsxwriter')
Write Excel with Python Pandas
Write Excel with Python Pandas. You can write any data (lists, strings, numbers etc) to Excel, by first converting it into a Pandas DataFrame and then writing the DataFrame to Excel.
To export a Pandas DataFrame as an Excel file (extension: .xlsx, .xls), use the to_excel() method.
installxlwt, openpyxl
to_excel() uses a library called xlwt and openpyxl internally.
- xlwt is used to write .xls files (formats up to Excel2003)
- openpyxl is used to write .xlsx (Excel2007 or later formats).
Both can be installed with pip. (pip3 depending on the environment)
$ pip install xlwt
$ pip install openpyxl
Write Excel
Write DataFrame to Excel file
Importing openpyxl is required if you want to append it to an existing Excel file described at the end.
A dataframe is defined below:
import pandas as pd
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=[‘one’, ‘two’, ‘three’], columns=[‘a’, ‘b’, ‘c’])
print(df)
# a b c
# one 11 21 31
# two 12 22 32
# three 31 32 33
You can specify a path as the first argument of the to_excel() method .
Note: that the data in the original file is deleted when overwriting.
The argument new_sheet_name is the name of the sheet. If omitted, it will be named Sheet1 .
df.to_excel(‘pandas_to_excel.xlsx’, sheet_name=‘new_sheet_name’)
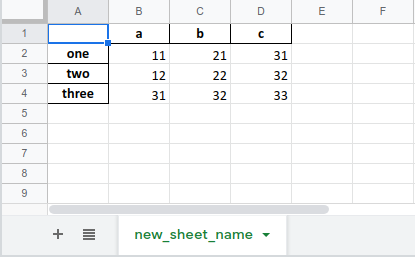
If you do not need to write index (row name), columns (column name), the argument index, columns is False.
df.to_excel(‘pandas_to_excel_no_index_header.xlsx’, index=False, header=False)
Write multiple DataFrames to Excel files
The ExcelWriter object allows you to use multiple pandas. DataFrame objects can be exported to separate sheets.
As an example, pandas. Prepare another DataFrame object.
df2 = df[[‘a’, ‘c’]]
print(df2)
# a c
# one 11 31
# two 12 32
# three 31 33
Then use the ExcelWriter() function like this:
with pd.ExcelWriter(‘pandas_to_excel.xlsx’) as writer:
df.to_excel(writer, sheet_name=‘sheet1’)
df2.to_excel(writer, sheet_name=‘sheet2’)
You don’t need to call writer.save(), writer.close() within the blocks.
Append to an existing Excel file
You can append a DataFrame to an existing Excel file. The code below opens an existing file, then adds two sheets with the data of the dataframes.
Note: Because it is processed using openpyxl, only .xlsx files are included.
path = ‘pandas_to_excel.xlsx’
with pd.ExcelWriter(path) as writer:
writer.book = openpyxl.load_workbook(path)
df.to_excel(writer, sheet_name=‘new_sheet1’)
df2.to_excel(writer, sheet_name=‘new_sheet2’)
Read Excel with Python Pandas
pandas.Series.to_excel#
Series. to_excel ( excel_writer , sheet_name = ‘Sheet1’ , na_rep = » , float_format = None , columns = None , header = True , index = True , index_label = None , startrow = 0 , startcol = 0 , engine = None , merge_cells = True , inf_rep = ‘inf’ , freeze_panes = None , storage_options = None ) [source] #
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default ‘Sheet1’
Name of sheet which will contain DataFrame.
na_rep str, default ‘’
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, ‘openpyxl’ or ‘xlsxwriter’. You can also set this via the options io.excel.xlsx.writer or io.excel.xlsm.writer .
merge_cells bool, default True
Write MultiIndex and Hierarchical Rows as merged cells.
inf_rep str, default ‘inf’
Representation for infinity (there is no native representation for infinity in Excel).
freeze_panes tuple of int (length 2), optional
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
>>> df1 = pd.DataFrame([['a', 'b'], ['c', 'd']], . index=['row 1', 'row 2'], . columns=['col 1', 'col 2']) >>> df1.to_excel("output.xlsx")
To specify the sheet name:
>>> df1.to_excel("output.xlsx", . sheet_name='Sheet_name_1')
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
>>> df2 = df1.copy() >>> with pd.ExcelWriter('output.xlsx') as writer: . df1.to_excel(writer, sheet_name='Sheet_name_1') . df2.to_excel(writer, sheet_name='Sheet_name_2')
ExcelWriter can also be used to append to an existing Excel file:
>>> with pd.ExcelWriter('output.xlsx', . mode='a') as writer: . df.to_excel(writer, sheet_name='Sheet_name_3')
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
>>> df1.to_excel('output1.xlsx', engine='xlsxwriter')