How HashTable Works Internally in Java?
Hashtable is a kind of Hash map but is synchronized. Hash map is non–synchronized, permits one null key & multiple null values, not-thread safe i.e. cannot share between many threads without proper synchronization, the key/values pairs are stored in Hashtable. The Hash table does not allow null value/key. When using this you specify an object that is used as a key & the value that you want to associate with the key. It is an array of an index. Each index is known as a bucket/slot. It restrains values based on keys & the place of bucket recognized by calling the Hash code () method. The Hash table of Java holds a class that has unique elements.
Working of Hashtable
Hash table intrinsically contains a slot/bucket in which the storage of key and value pair. It uses the key’s hash code to discover which bucket the key/value of a set should map. To find an item in a list you do the first approach i.e. linear search this involves checking each item, it will take more time. Suppose you have retrieved a value and its index number of an array, then you will look up a value very quickly. In fact, a time will be taken less if you know the index number is independent of the size & position of the array. But how do you know which element of the array contains the value you are looking for. The answer is by calculating the value itself the index number is somewhat related to data.
Let’s proliferate the array, take a name and find its ASCII code, for example, we will take a name say Mia find ASCII code for each letter & add the ASCII code and divide the combined ASCII number with the size of an element in this it is 5, we will take a reminder of the element that is 4 and there we will put the name Mia i.e. in 4th Slot/ Bucket.
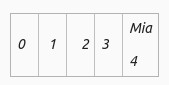
i 105
a 97
Sum = 279
Modulus = 279 % 5 = 4
And now we can add more names to the Bucket as shown below:
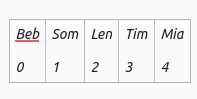
Mia ⇾ M (77) + i(105) + a(97) = 279 % 5 = 4
Tim ⇾ T (84) + i(105) + m(77) = 298 % 5 = 3
Leo ⇾ L(76) + e(101) + n(110) = 287 % 5 = 2
Som ⇾ S(83) + o(111) + m(77) = 271 % 5 = 1
Beb ⇾ B(66) + e(101) + b(98) = 265 % 5 0
Index number = sum of ASCII codes % Size of array
Let’s retrieve an item say Ada we perform the same calculation,
Find ASCII for Ada = (65+100+97) = 262
262 % 11 = 9
MyData = Array (9)

This is a fast array lookup. Rather than storing individual items or data hash tables are used to store the key-value pairs. For example, Ada would be the key for which want to calculate the Index and DOB of the corresponding value, for this reason, a hash table of key-value pair is sometimes referred to as a hash map in fact if an object-oriented approach is taken each person in an instance of a class and the key would be of many properties, by populating an array with objects you will effectively store much-related data you like for each bucket

A hashing algorithm also is known as a Hash function. The hash function is a function that generates a table when given a key. This is a function to obtain a bucket location from the Key’s hash code. It every time returns a digit for an object. Calculation applied to a key to transforming it into an address.
For numeric keys, divide the key by the number of available addresses, n, and take the remainder
For alphanumeric keys, divide the sum of ASCII codes in a key by the number of available addresses, and take the remainder.
- Folding method divides key into equal parts then adds the parts together
- Phone No. 018767242947 becomes 01+87+67+24+29+47= 255
- Depending on the size of a table, may then divide by some constant and take the remainder.
- There are lots of Hash functions some appropriate to another depending on nature.
Collisions in a Hashtable
So far you have seen, there are a lot of a hash table with data that is very conveniently causing any problem say that is unrealistic sometimes if you apply a hash function in two different cases it generates the same index number for both but both items can’t go in the same place this is called Collision. Two identical objects every time have the same digits while two unequal objects might not always have dissimilar digits. Putting an object to the hash table, there is a possibility that dissimilar objects might have an equal hash code called Collision. For rectifying this array of lists is used by a hash table. The set mapped to array index/single bucket and is kept in an index & index reference is stored in array index.
Let’s load up the array again this time with a different set of data. As shown below if Mia is occupying position 4 and Leo to position 2 and if the other names too have the same entry at position 2 then automatically the next bucket will be filled with that entry for avoiding collision as shown below.
Find Rae 280 Mod 11 = 5
myData = Array(5)

As the reminder for an ASCII code of Rae is 5 but is put in slot 8 because due to collision the 2 items figure out to be in the same slot but for avoiding this the Rae is shifted to other slot and as the other slot is again occupied so it is shifted to the 8th position.
Resolving a collision by putting the item somewhere else then its calculated address is called OPEN ADDRESSING because every location is open to an item. This can use a variety of techniques to decide where to place an item this particular addressing technique is called LINEAR PROBING if the calculated address is occupied then the linear search is used to find the next available bucket if the linear probing comes to an end and still cannot find a position it might cycle around the beginning of array & continue searching from there. The more items there are in a hash table the more chances of a collision. One way to deal with this is making the hash table bigger for the total amount of data you are expecting perhaps such that happen 70% of the table is occupied the ratio between the no of items stored and the size of an array is known as Load Factor
Load Factor = Total number of items stored / Size of the array
Another way to do with collisions is known as chains sometimes referred to as CLOSED ADDRESSING. In this, the one slot can form a chain by adding the various item into one bucket.
The objective of a Hash Function
- Minimize collisions
- Uniform distribution of hash values
- Easy to calculate
- Resolve any collisions
Methods like hashCode () & equal () to find exact element match
equal(): Object class define equal() as a given language of Java. In which objects indicate whether few objects pass as an argument that is “equal to” the present instance. The different or two objects can be similar only if they are put on an equal memory address.
public boolean equals (Object obj) // This method checks if some other Object // passed to it as an argument is equal to // the Object on which it is invoked.
Should follow the below principles:
- Reflexive: For a single object say a, a.equal(a) return true.
- Symmetric: For two different objects, a.equal(y) return true if and only if y.equal(a) returns true.
- Transitive: For multiple objects a, b, c if a.equal(b) returns true & b.equals(c) returns true then a.equals(c) should return true.
- If the object properties are modified means used in equal() method implementation this will result in different and multiple of a.equal(b) will return equal outcome.
- Object class equal() will return true only when two references will mark similar objects.
Note: For any non-null reference value a, a.equals(null) should return false.
hashCode(): In this object gives back an integer depiction of an object’s memory address. By using this method a random integer will get returned that is unique for a particular instance. This will return integer hash code data or value of that object.
public int hashCode() // This method returns the hash code value // for the object on which this method is invoked.
Class Hashtable
This class implements a hash table, which maps keys to values. Any non- null object can be used as a key or as a value.
To successfully store and retrieve objects from a hashtable, the objects used as keys must implement the hashCode method and the equals method.
An instance of Hashtable has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. Note that the hash table is open: in the case of a «hash collision», a single bucket stores multiple entries, which must be searched sequentially. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. The initial capacity and load factor parameters are merely hints to the implementation. The exact details as to when and whether the rehash method is invoked are implementation-dependent.
Generally, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the time cost to look up an entry (which is reflected in most Hashtable operations, including get and put ).
The initial capacity controls a tradeoff between wasted space and the need for rehash operations, which are time-consuming. No rehash operations will ever occur if the initial capacity is greater than the maximum number of entries the Hashtable will contain divided by its load factor. However, setting the initial capacity too high can waste space.
If many entries are to be made into a Hashtable , creating it with a sufficiently large capacity may allow the entries to be inserted more efficiently than letting it perform automatic rehashing as needed to grow the table.
This example creates a hashtable of numbers. It uses the names of the numbers as keys:
Hashtable numbers = new Hashtable(); numbers.put("one", 1); numbers.put("two", 2); numbers.put("three", 3); To retrieve a number, use the following code:
Or to implement a multi-value map, Map> , supporting multiple values per key:
map.computeIfAbsent(key, k -> new HashSet()).add(v); The mapping function should not modify this map during computation.
This method will, on a best-effort basis, throw a ConcurrentModificationException if the mapping function modified this map during computation.
computeIfPresent
If the value for the specified key is present and non-null, attempts to compute a new mapping given the key and its current mapped value. If the remapping function returns null , the mapping is removed. If the remapping function itself throws an (unchecked) exception, the exception is rethrown, and the current mapping is left unchanged. The remapping function should not modify this map during computation. This method will, on a best-effort basis, throw a ConcurrentModificationException if the remapping function modified this map during computation.
compute
Attempts to compute a mapping for the specified key and its current mapped value (or null if there is no current mapping). For example, to either create or append a String msg to a value mapping:
map.compute(key, (k, v) -> (v == null) ? msg : v.concat(msg)) (Method merge() is often simpler to use for such purposes.) If the remapping function returns null , the mapping is removed (or remains absent if initially absent). If the remapping function itself throws an (unchecked) exception, the exception is rethrown, and the current mapping is left unchanged. The remapping function should not modify this map during computation. This method will, on a best-effort basis, throw a ConcurrentModificationException if the remapping function modified this map during computation.
merge
If the specified key is not already associated with a value or is associated with null, associates it with the given non-null value. Otherwise, replaces the associated value with the results of the given remapping function, or removes if the result is null . This method may be of use when combining multiple mapped values for a key. For example, to either create or append a String msg to a value mapping:
map.merge(key, msg, String::concat) If the remapping function returns null , the mapping is removed. If the remapping function itself throws an (unchecked) exception, the exception is rethrown, and the current mapping is left unchanged. The remapping function should not modify this map during computation. This method will, on a best-effort basis, throw a ConcurrentModificationException if the remapping function modified this map during computation.
Report a bug or suggest an enhancement
For further API reference and developer documentation see the Java SE Documentation, which contains more detailed, developer-targeted descriptions with conceptual overviews, definitions of terms, workarounds, and working code examples. Other versions.
Java is a trademark or registered trademark of Oracle and/or its affiliates in the US and other countries.
Copyright © 1993, 2023, Oracle and/or its affiliates, 500 Oracle Parkway, Redwood Shores, CA 94065 USA.
All rights reserved. Use is subject to license terms and the documentation redistribution policy.