How to Visualize a Decision Tree from a Random Forest in Python using Scikit-Learn
Here’s the complete code: just copy and paste into a Jupyter Notebook or Python script, replace with your data and run:
Explanation of code
- Create a model train and extract: we could use a single decision tree, but since I often employ the random forest for modeling it’s used in this example. (The trees will be slightly different from one another!).
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=10)# Train
model.fit(iris.data, iris.target)
# Extract single tree
estimator = model.estimators_[5]
2. Export Tree as .dot File: This makes use of the export_graphviz function in Scikit-Learn. There are many parameters here that control the look and information displayed. Take a look at the documentation for specifics.
from sklearn.tree import export_graphviz# Export as dot file
export_graphviz(estimator_limited,
out_file='tree.dot',
feature_names = iris.feature_names,
class_names = iris.target_names,
rounded = True, proportion = False,
precision = 2, filled = True)
3. Convert dot to png using a system command: running system commands in Python can be handy for carrying out simple tasks. This requires installation of graphviz which includes the dot utility. For the complete options for conversion, take a look at the documentation.
# Convert to png
from subprocess import call
call(['dot', '-Tpng', 'tree.dot', '-o', 'tree.png', '-Gdpi=600']) 4. Visualize: the best visualizations appear in the Jupyter Notebook. (Equivalently you can use matplotlib to show images).
# Display in jupyter notebook
from IPython.display import Image
Image(filename = 'tree.png') Considerations
With a random forest, every tree will be built differently. I use these images to display the reasoning behind a decision tree (and subsequently a random forest) rather than for specific details.
It’s helpful to limit maximum depth in your trees when you have a lot of features. Otherwise, you end up with massive trees, which look impressive, but cannot be interpreted at all! Here’s a full example with 50 features.
Conclusions
Machine learning still suffers from a black box problem, and one image is not going to solve the issue! Nonetheless, looking at an individual decision tree shows us this model (and a random forest) is not an unexplainable method, but a sequence of logical questions and answers — much as we would form when making predictions. Feel free to use and adapt this code for your data.
As always, I welcome feedback, constructive criticism, and hearing about your data science projects. I can be reached on Twitter @koehrsen_will
How to visualize a single Decision Tree from the Random Forest in Scikit-Learn (Python)?
The Random Forest is an esemble of Decision Trees. A single Decision Tree can be easily visualized in several different ways. In this post I will show you, how to visualize a Decision Tree from the Random Forest.
First let’s train Random Forest model on Boston data set (it is house price regression task available in scikit-learn ).
# Load packages import pandas as pd from sklearn.datasets import load_boston from sklearn.ensemble import RandomForestRegressor from sklearn import tree from dtreeviz.trees import dtreeviz # will be used for tree visualization from matplotlib import pyplot as plt plt.rcParams.update('figure.figsize': (12.0, 8.0)>) plt.rcParams.update('font.size': 14>) Load the data and train the Random Forest.
boston = load_boston() X = pd.DataFrame(boston.data, columns=boston.feature_names) y = boston.target Let’s set the number of trees in the forest to 100 (it is a default of n_estiamtors ):
rf = RandomForestRegressor(n_estimators=100) rf.fit(X, y) RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mse', max_depth=None, max_features='auto', max_leaf_nodes=None, max_samples=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False) Decision Trees are stored in a list in the estimators_ attribute in the rf model. We can check the length of the list, which should be equal to n_estiamtors value.
We can plot a first Decision Tree from the Random Forest (with index 0 in the list):
plt.figure(figsize=(20,20)) _ = tree.plot_tree(rf.estimators_[0], feature_names=X.columns, filled=True) 
Do you understand anything? The tree is too large to visualize it in one figure and make it readable.
Let’s check the depth of the first tree from the Random Forest:
rf.estimators_[0].tree_.max_depth >>> 16 Our first tree has max_depth=16 . Other trees have similar depth. To make visualization readable it will be good to limit the depth of the tree. In MLJAR’s open-source AutoML package mljar-supervised the Decision Tree’s depth is set to be in range from 1 to 4. Let’s train the Random Forest again with max_depth=3 .
rf = RandomForestRegressor(n_estimators=100, max_depth=3) rf.fit(X, y) RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mse', max_depth=3, max_features='auto', max_leaf_nodes=None, max_samples=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False) The plot of first Decision Tree:
_ = tree.plot_tree(rf.estimators_[0], feature_names=X.columns, filled=True) 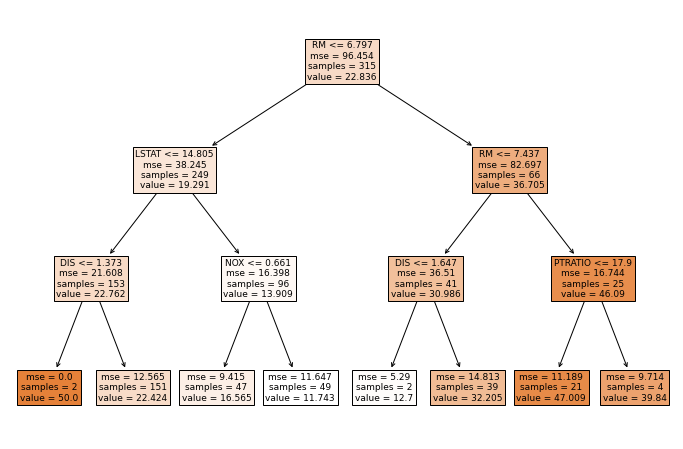
We can use dtreeviz package to visualize the first Decision Tree:
viz = dtreeviz(rf.estimators_[0], X, y, feature_names=X.columns, target_name="Target") viz Summary
I show you how to visualize the single Decision Tree from the Random Forest. Trees can be accessed by integer index from estimators_ list. Sometimes when the tree is too deep, it is worth to limit the depth of the tree with max_depth hyper-parameter. What is interesting, limiting the depth of the trees in the Random Forest will make the final model much smaller in terms of used RAM memory and disk space needed to save the model. It will also change the performance of the default Random Forest (with full trees), it will help or not, depending on the data set.