Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Java Text Mining framework
Ulflander/minethat
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Minethat is a new kind of ETL dedicated to text mining.
This project has been discontinued, but feel free to contact me if you wish to use some of the code! To get details about the project, see PIVOT.md
It contains a web server (in Node.js) and some background services (update of data, mining services. in Java).
To get started, run make in your terminal:
Other repositories requirements
In order to have the whole Minethat system running, you should clone in the main directory (this repo) two other repositories: web and corpora.
/conf # Configuration /datasets # Datasets used by java services /java-apps # Java services /logs # All logs for all processes and apps /utils # Libraries
- node web/src/server/aggregator.js
- corpora/corpora -r datasets/corpora
- java-apps/dist/bin/mail_service
- java-apps/dist/bin/extractor_service
- java-apps/dist/bin/miner_service
Use gulp watch while working to refresh files.
- Homepage (/)
- Web application (/app)
- Blog (/blog)
- Developer center (/developers)
- Private documentations (/private)
- Root folder «static» is automatically generated from «src/static»
- How to add new user/pass in users.htpasswd:
- npm install -g htpasswd
- htpasswd -bc users.htpasswd user pass
- Logging: log4j 2
- Testing/code quality:
- jUnit
- findbugs, PMD, checkstyle, cobertura
- NLP: Apache OpenNLP, Stanford POSTagger & NER
- Text extraction: Apache Tika, PDFBox
- HTML parsing: Jsoup
MailInputService and web-server generate some Jobs, save them in MongoDB, get the ID, and submit ID to queue input service that will run the job and process each document in it.
MailInputService > > ExtractorService > MinerService Web-server >These tasks are to be done before first deployment:
- Configure log4j file appenders so it targets log files
- Configure log4j mongodb appender
- Configure tracer file appenders + mongodb appenders
- Configure MongoDB replication (x2)
We believe that text-mining should be simple and accessible.
Here are a few examples of use:
- Email footer
- Blog
- Reddit (r/linguistics/, r/MachineLearning/, r/LanguageTechnology/, r/compsci/, r/statistics/, r/opendata, r/startups)
Just drag a text file (PDF, Word, Markdown. ) and wait for the result. You’re developer? We have some APIs for you.
We use the best-in-class open source solutions in a modular way, letting you select what mining operation you want to run on texts. Once submitted, your text will be streamed accross dozens of processors that will analyse the text and annotate it.
Minethat utilities relies on different tools.
Text mining core services — core of Minethat offer — relies on a Java service. Main reason is the high number of open source and licensed Java APIs dedicated to various text mining tasks. All code lives in java-apps — IntellijIDEA project included.
All APIs are exposed through Node.js servers. Node is particularly efficient in serving stuff at any scale.
- Text annotation
- Sentiment analysis
- Trend discovery
- Documents encryption
- SDKs: Java, Node.js, Python
- 3 APIs (Mail, REST, web) + Chrome Extension
Everybody on the same line
What we are (what do we want?)
- We are minethat, a compagny that aim to allow everyone to better use and understand textual content.
Benefits (what is important to customers about what we do?)
Customers (What are our most successful customer stories?)
Key partners (What makes them successful using our products?)
Competitors (How are we different from our competitors)
By subscribing to Business plans, you automatically benefit the premium support access.
Startup and business owners
| | Basic | Startup | Business | |———————————————————| | Documents/month | 10 | 1000 | Unlimited | | Web app submission | x | x | x | | Email submission | | x | x | | API submission | | x | x | | Premium support | | | x | | Initial training | | | x | | Price | Free | $49/m | $499/m |
What languages do you support?
Right now we fully support english and french languages. We work hard in order to soon provide chinese, japanese, as well as german and spanish.
What are the ways to submit a document?
- manually through our web application (app.minethat.com)
- programatically using our REST API
- or just send us your text by email, we’ll send you back the result in minutes
What is the technical process?
When you submit a document, a Job is automatically created and queued in our stream processing infrastructure. The document will go through different kind of processors, that will split the text into simple analyzable senquences of tokens. Once all processors are done, the job is
Does it implies machine learning?
Definitely yes. We use corpuses based on content from Wikipedia, Google, New York Times, and more. You can also submit your own corpuses for your custom classification process.
What is your Level Of Quality / Availability?
For Enterprise plans, we ensure that our infrastructure has an availabity rate of 99.90%.
Text Mining Framework (Java)
В данной статье я бы хотел рассказать о небольших результатах своей научной деятельности в сфере Text Mining. Этими самыми «результатами» стал небольшой FrameWork, который, пока еще, и до либы то не очень дотягивает, но мы растем =). Данный проект — реализация на практике некоторых, разработанных мною, теоретических положений. Как следствие этого я представляю возможности, которыми он может потенциально обладать в конце внедрения всех идей. Названо сее творение: «Text Mining FrameWork»(TextMF). Давайте в кратце рассмотрим, что именно будет позволять TextMF в своей первой финальной версии и что работает уже сейчас.
Должно быть в финальной версии:
- Статистический анализ текста;
- Поиск всех слов и словоформ каждого слова в тексте;
- Ранжирование слов по весу в тексте;
- Поиск субъектов в тексте, о которых идет речь;
- Связи между субъектами в тексте (прямые и не прямые связи);
- Реферирование текста;
- Определение темы текста;
- Обучение языку;
- Организация взаимодействия с пользователем по средствам общения (чата).
- Статистический анализ текста (пока реализовано очень частично);
- Поиск всех слов и словоформ в тексте;
- Сортировка слов по их весу в данном тексте;
- Поиск персон в тексте;
- Определение темы текста (идет тестирование и юстировка формул).
Дело в том, что цель данного проекта не создать инструмент, используя который можно реализовать какой либо алгоритм обработки текста (как например Python NLTK и схожие), а дать возможность использовать уже готовые алгоритмы. А заодно и апробировть на практике свой собственный алгоритм. Т.е. это не еще один статистический анализатор или набор контейнеров оптимизированных под работу с текстовыми данными. Нет! Это набор эвристик, которые будут работать из коробки, не нуждаясь в дополнительных знаниях.
С какими входными данными работает TextMF: пока только текстовые файлы. Само собой далее планируется поддержка намного больших входных форматов. Так же планируется сделать интеграцию с Веб, дабы можно было-бы спокойно анализировать Веб-странички.
Проект распространяется через репозиторий BitBucket.
Клоните его себе и подключаете к своему проекту =) Все предельно просто. В скором времени будут доступны сборки в виде подключаемого jar.
Обработка текста очень часто занимает много времени, особенно если пытаться открыть целую книгу! Так что в целях «на попробовать» настоятельно рекомендую ограничивать себя несколькими страничными текстами с сайтов. Однако, уж очень маленькие тексты так же могут дать не очень хороший результат, из-за недостаточности информации в них.
Как уже говорилось ранее, основная идея в максимальной простоте использования и сокрытие эвристик и алгоритмов. Так что все банально:
// Открываем и парсим текстовый файл, который лежит по адресу TEXT_FILE_NAME Text text = new Text(TEXT_FILE_NAME); // Получаем список слов отранжированных по весу List words = text.getWords(); // Получаем тему текста List theme = text.getThem(); // Получаем первое слово в списке слов Word word = words.get(0); // Получаем лист всех словоформ List wordForms =word.getWordForms(); // Получаем количество вхождений слова в текст long count = word.getCount(); // Получаем все персоны, которые встречаются в тексте List objects = text.getObjects(); // Смотрим вес слова double weight = text.getWordWeight(word);Повторюсь, получение темы — довольно долгая процедура, так что вызывая данный метод будьте осторожны;) Само собой будет реализован и асинхронный метод получения темы, но позже. Так же ОЧЕНЬ важно отметить, что качество работы методов растет в зависимости от того, какого размера текст подан на вход. Чем больше информации тем, как правило, больше возможности выучить язык. Однако и время открытия файлов существенно возрастает, при увеличении размеров содержимого.
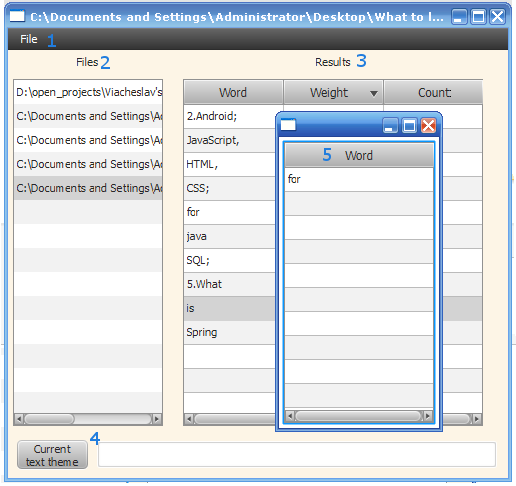
Небольшая UI-программа
Для наглядной демонстрации некоторых функций программы, моим коллегой по имени Андрей, был на скорую руку написан небольшой UI клиент. На текущей стадии он носит просто ознакомительный характер, так как иногда удобнее воспользоваться им. Написан он на Java FX, и пока не распространяется в виде отдельного jar файла. Для того, что бы его «пощупать», нужно его собрать =(.

1) Меню выбора текста для обработки;
2) Список выбранных файлов;
3) Результаты работы:
a) слово встречаемое в тексте;
b) вес слова в тексте;
с) количество повторений в тексте
4) Поле для вывода темы текста;
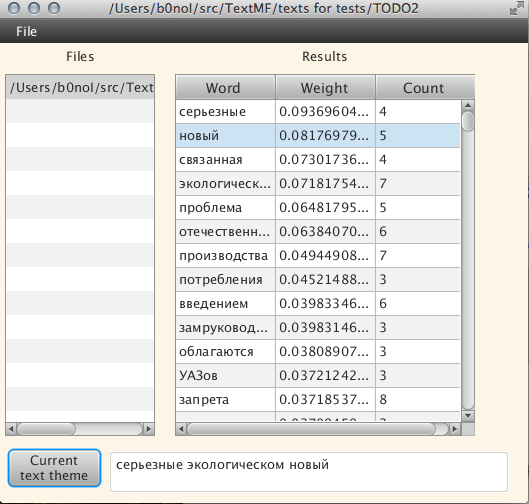
5) Список словоформ.Давайте посмотрим, что мы можем узнать, используя нашу программу для этого текста: Владельцам «Волг» и «Москвичей» дадут еще один год:
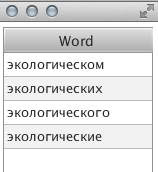
Поиск темы осуществлялся около минуты (долго, согласен). При выборе какого либо отдельного слова, можно посмотреть его словоформы:
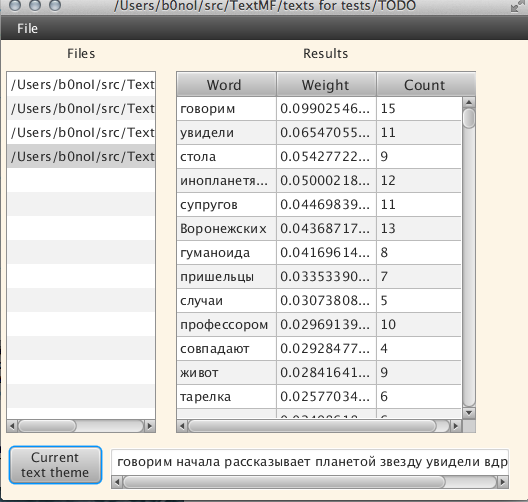
А теперь попробуем еще один текст: «Пришельцы похитили семью украинцев и рассказали о будущем землян!», наверное один из самых «желтых» текстов =):
Текст открывался долго, наверное минуту, тему искал где-то так же. Само собой, под темой текста стоит понимать цепочку слов, которые алгоритм посчитал как тему текста. В дальнейшем алгоритм сможет выдавать вывод в читабильном виде, но это будущее, а сейчас
нам нужна Ваша помощь
По любым предложениям сотрудничества прошу обращаться сюда: Viacheslav@b0noI.com
Из того, что будет в ближайшее время(думаю в пределах месяца-двух) с проектом:
- добавим сборку jar файла;
- проект будет разделен на ядро и UI, т.е. добавится еще один репозиторий;
- начнется реализация долгосрочной памяти;
- анализ связей между персонами;
- появится возможность реферирования текста;
- создание самодостаточного jar с UI.
Сейчас TextMF стал полуфиналистом проекта www.ukrinnovation.com. Так что есть, хоть и маленький, но все же шанс получить инвестиции на развитие.
Знаю, что пока это мечты, но если бы у меня спросили какой функционал я вижу в конце, то я бы ответил: библиотека, используя которую можно написать чат-бота, который пройдет тест Тюринга. Если говорить более реальное, то скорее всего движки для динамического отслеживания информации в интернете. Отслеживание связей и контроль за их изменениями. Ну и, само собой, нечто для создания каких либо локальных поисковых систем.
Сама идея имеет огромный потенциал, тут и спам-фильтры, и поисковые системы, и системы автоматического реферированная, и еще много-много чего того, что можно построить на базе такого framework.
Авторы TextMF:
Ваш покорный слуга Вячеслав В Ковалевский и
разработчик UI Андрей Прищепа (vinglfm@gmail.com)