- Tabula в Python – извлечение табличных данных из PDF
- Что такое Tabula Python?
- Кто использует Tabula?
- Реализация на Python
- Чтение файла PDF
- Обработка нескольких таблиц на одной странице файла PDF
- Преобразование файла PDF напрямую в файл CSV
- Extract Table from PDF using Python
- Method 1:
- Step 1: Import library and define file path
- Step 2: Extract table from PDF file
- Step 3: Write dataframe to CSV file
- Method 2:
- Extract multiple tables from a single page of PDF using Python
- Extract all tables from PDF using Python
- Conclusion
Tabula в Python – извлечение табличных данных из PDF
Как правило, не обязательно, чтобы данные, которые мы используем, были доступны в формате CSV или JSON. Данные могут быть сохранены в виде таблицы в файле PDF. В самом простом случае мы можем скопировать и вставить таблицу в электронную таблицу или текстовый редактор. Но также может случиться так, что в одном PDF-файле можно использовать более одной таблицы с похожей структурой. В таких случаях мы должны копировать и вставлять каждую из этих таблиц отдельно, что делает работу утомительной.
Чтобы избавиться от этой унылой работы, Python предоставляет библиотеку с открытым исходным кодом, также известную как tabula-py, которая позволяет пользователям отдельно извлекать более одной таблицы. В данном уроке мы узнаем о таблицах и их функциях и подробно разберем извлечение табличных данных с помощью Tabula в Python.
Что такое Tabula Python?
Tabula в Python – это базовая оболочка tabula-java, которая позволяет пользователям извлекать таблицу и преобразовывать файл PDF непосредственно в фреймы данных или JSON. Пользователь также может извлекать таблицы из PDF и преобразовывать их в файлы формата TSV, CSV или JSON.
Табула – это инструмент, основанный на приложении с графическим интерфейсом пользователя(GUI); однако tabula-java – это инструмент, основанный на пользовательском интерфейсе командной строки(CUI). tabula-java предоставляет привязки для Ruby, R и NodeJS, но не для Python. Таким образом, разработчики представили концепцию tabula-py, которая обеспечивает привязку Python.
Теперь давайте разберемся, кто использует Tabula и как ее установить.
Кто использует Tabula?
Tabula – это мощный инструмент, который используется новостными организациями всех рангов для обеспечения журналистских расследований. Такими известными информационными агентствами являются The Times of London, ProPublica, Foreign Policy, The New York Times, La Nacion(Аргентина) и St. Paul(MN) Pioneer Press.
Существуют массовые организации, такие как SchoolCuts.org, которые также зависят от Tabula, чтобы преобразовать громоздкие документы в удобные для человека общественные ресурсы.
Помимо вышеперечисленного, есть исследователи из других областей, которые используют Tabula для преобразования своих отчетов в формате PDF в файлы формата Excel, CSV и JSON и используют его для целей анализа и приложений баз данных.
Реализация на Python
После того, как мы немного обсудили Tabula, давайте разберемся с ее реализацией на Python.
Поскольку tabula-py – это библиотека Python с открытым исходным кодом, мы будем использовать установщик pip для установки библиотеки.
После завершения установки мы можем проверить это, просто импортировав библиотеку, как показано ниже:
Если программа выдает ошибку импорта, рекомендуется переустановить пакет.
Библиотека tabula-py предоставляет различные функции, такие как чтение файла PDF, чтение таблицы на определенной странице файла PDF, чтение нескольких таблиц на одной странице файла PDF или преобразование файлов PDF непосредственно в файл CSV.
Чтение файла PDF
Библиотека tabula-py позволяет пользователям читать PDF-файл с помощью функции, известной как read_pdf().
obj = tabula.read_pdf(filename, args[])
filename: Параметр filename – это имя файла pdf, данные которого мы хотели бы прочитать.
Давайте преобразуем следующую таблицу данных pdf в фрейм данных pandas.
Имя файла: Marksheet_table.py
| Имя | Английский | Физика | Химия | Биология | Итог |
|---|---|---|---|---|---|
| А | 86 | 54 | 65 | 83 | 288 |
| B | 56 | 45 | 80 | 55 | 236 |
| C | 34 | 66 | 73 | 90 | 263 |
| D | 77 | 75 | 46 | 34 | 232 |
| E | 74 | 82 | 55 | 77 | 288 |
| F | 69 | 76 | 82 | 46 | 273 |
| G | 53 | 33 | 29 | 45 | 160 |
| H | 70 | 41 | 67 | 23 | 201 |
| I | 80 | 43 | 88 | 28 | 239 |
| J | 90 | 37 | 45 | 71 | 243 |
| K | 98 | 55 | 88 | 81 | 322 |
| L | 90 | 54 | 67 | 37 | 248 |
| M | 87 | 76 | 88 | 54 | 305 |
| N | 86 | 69 | 82 | 66 | 303 |
| О | 67 | 74 | 54 | 65 | 260 |
| P | 75 | 96 | 53 | 67 | 291 |
| Q | 45 | 87 | 80 | 45 | 257 |
| R | 44 | 66 | 49 | 78 | 237 |
| S | 78 | 39 | 78 | 80 | 275 |
| Т | 56 | 54 | 76 | 86 | 273 |
| U | 43 | 90 | 64 | 77 | 274 |
| V | 95 | 88 | 66 | 55 | 304 |
| W | 64 | 67 | 86 | 80 | 297 |
| X | 82 | 56 | 45 | 65 | 248 |
| Y | 79 | 65 | 70 | 54 | 268 |
| Z | 83 | 54 | 40 | 75 | 252 |
Вот пример, приведенный ниже, который демонстрирует, как извлечь данные из PDF.
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 1) # printing the table print(mytable[0])
Name English Physics Chemistry Biology Total 0 A 86 54 65 83 288 1 B 56 45 80 55 236 2 C 34 66 73 90 263 3 D 77 75 46 34 232 4 E 74 82 55 77 288 5 F 69 76 82 46 273 6 G 53 33 29 45 160 7 H 70 41 67 23 201 8 I 80 43 88 28 239 9 J 90 37 45 71 243 10 K 98 55 88 81 322 11 L 90 54 67 37 248 12 M 87 76 88 54 305 13 N 86 69 82 66 303 14 O 67 74 54 65 260 15 P 75 96 53 67 291 16 Q 45 87 80 45 257 17 R 44 66 49 78 237 18 S 78 39 78 80 275 19 T 56 54 77 86 273 20 U 43 90 64 77 274 21 V 95 88 66 55 304 22 W 64 67 86 80 297 23 X 82 56 45 65 248 24 Y 79 65 70 54 268 25 Z 83 54 40 75 252
В приведенном выше примере мы импортировали необходимую библиотеку и определили переменную, в которой хранится адрес файла данных pdf. Затем мы использовали функцию read_pdf(), чтобы прочитать данные из PDF и распечатать их для пользователей. В результате таблица данных была успешно прочитана.
Примечание. Мы использовали параметр pages в функции read_pdf() для чтения данных с указанных страниц.
Давайте рассмотрим другой пример печати таблиц с определенной страницы, скажем, страницы номер 2.
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 2) # printing the table print(mytable[0])
Name Final Scores 0 A 288 1 B 236 2 C 263 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 16 Q 257 17 R 237 18 S 275 19 T 273 20 U 274 21 V 304 22 W 297 23 X 248 24 Y 268 25 Z 252
В приведенном выше примере мы выполнили ту же процедуру, что и ранее. Однако мы присвоили параметру страниц значение 2 и распечатали первую таблицу указанной страницы. В результате таблица нулевого индекса на странице 2 была успешно напечатана.
Теперь давайте разберемся, что происходит, когда на одной странице файла данных PDF находится более одной таблицы.
Обработка нескольких таблиц на одной странице файла PDF
Мы можем обрабатывать более одной таблицы в одной и той же, используя дополнительный параметр, известный как multiple_tables. Параметр multiple_tables принимает логическое значение, для которого функция read_pdf() считывает несколько таблиц как независимые таблицы, если истинно, или считывает несколько таблиц как одну таблицу, если ложь.
Давайте рассмотрим следующий пример, демонстрирующий, как читать несколько таблиц как независимые.
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 2, multiple_tables = True) # printing the table print(mytable[0]) print(mytable[1])
Name Final Scores 0 A 288 1 B 236 2 C 263 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 16 Q 257 17 R 237 18 S 275 19 T 273 20 U 274 21 V 304 22 W 297 23 X 248 24 Y 268 25 Z 252 Name Position 0 K I 1 M II 2 V III 3 N IV 4 W V
В следующем примере мы снова импортировали необходимую библиотеку и определили переменную, в которой хранится адрес файла PDF. Затем мы использовали функцию read_pdf() и включили параметр multiple_tables, установив для него значение True. Затем мы отдельно распечатали несколько таблиц, представленных на странице 2 файла PDF.
Теперь давайте рассмотрим пример, чтобы понять, как читать несколько таблиц как одну.
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 2, multiple_tables = False) # printing the table print(mytable[0])
Name Final Scores 0 A 288 1 B 236 2 C 263 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 16 Q 257 17 R 237 18 S 275 19 T 273 20 U 274 21 V 304 22 W 297 23 X 248 24 Y 268 25 Z 252 26 Name Position 27 K I 28 M II 29 V III 30 N IV 31 W V
В следующем примере мы установили для параметра multiple_tables значение False. В результате таблицы, представленные на странице 2, рассматриваются как одна таблица.
Преобразование файла PDF напрямую в файл CSV
Мы можем преобразовать файл PDF, содержащий табличные данные, непосредственно в файл CSV с помощью метода convert_into() в библиотеке таблиц.
tabula.convert_into("filename.pdf", "newfilename.csv", args[]) Давайте рассмотрим следующий пример, иллюстрирующий преобразование файла PDF в файл CSV.
# importing the library import tabula # address of the file myfile = 'marksheettable.pdf' # using the read_pdf() function tabula.convert_into(myfile, "marksheet.csv") print("The PDF file has been converted successfully.") 'pages' argument isn't specified.Will extract only from page 1 by default. The PDF file has been converted successfully.
В приведенном выше примере мы снова импортировали необходимую библиотеку и определили переменную, содержащую адрес файла PDF. Затем мы использовали метод convert_into() для преобразования файла PDF в файл CSV и распечатали сообщение об успешном завершении.
Более того, мы также можем заметить, что программа вернула заявление о том, что аргумент «страницы» не указан. Таким образом, таблица, представленная на странице 1, будет извлечена по умолчанию.
Extract Table from PDF using Python

In this tutorial we will discuss how to extract table from PDF files using Python.
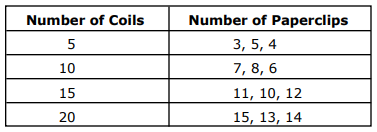
We know that it is on the first page of the PDF file. Now we can extract it to CSV or DataFrame using Python:
Method 1:
Step 1: Import library and define file path
Step 2: Extract table from PDF file
The above code reads the first page of the PDF file, searching for tables, and appends each table as a DataFrame into a list of DataFrames dfs.
Here we expected only a single table, therefore the length of the dfs list should be 1:
You can also validate the result by displaying the contents of the first element in the list:
Number of Coils Number of Paperclips 0 5 3, 5, 4 1 10 7, 8, 6 2 15 11, 10, 12 3 20 15, 13, 14 Step 3: Write dataframe to CSV file
Simply write the DataFrame to CSV in the same directory:
Method 2:
This method will produce the same result, and rather than going step-by-step, the library provides a one-line solution:
Both of the above methods are easy to use when you are sure that there is only one table on a particular page.
In the next section we will explore how to adjust the code when working with multiple tables.
Extract multiple tables from a single page of PDF using Python
We want to extract the tables below:
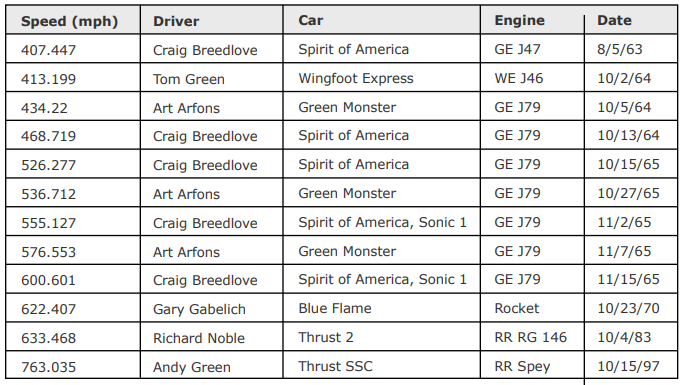
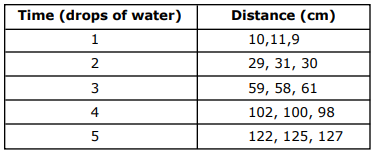
Using Method 1 from the previous section, we can extract each table as a DataFrame and create a list of DataFrames:
Notice that in this case we set pages=’2′, since we are extracting tables from page 2 of the PDF file.
Check that the list contains two DataFrames:
Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
and you should get two CSV files: table_0.csv and table_1.csv.
Note: if you try to use Method 2 described in the previous section, it will extract the 2 tables into a single worksheet in the CSV file and you would need to break it up into two worksheets manually.
Extract all tables from PDF using Python
In the above sections we focused on extracting tables from a given single page (page 1 or page 2). Now what do we do if we simply want to get all of the tables from the PDF file into different CSV files?
It is easily solvable with tabula-py library. The code is almost identical to the previous part. The only change we would need to do is set pages=’all’, so the code extracts all of the tables it finds as DataFrames and creates a list with them:
Check that the list contains all three DataFrames:
Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
Conclusion
In this article we discussed how to extract table from PDF files using tabula-py library.