Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель «убить» CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — «понять», так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой «лисп»/»питон»/»ваш абсолютно новый синтаксис» на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github’е. Тегами обозначены начало и концы статей для удобства.
Немного теории
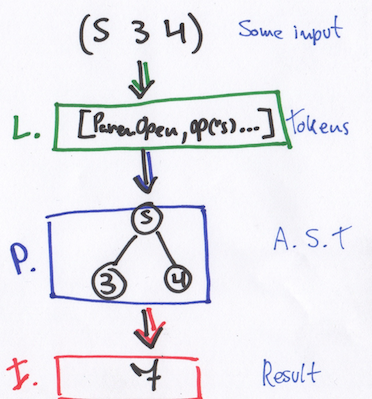
Не углубляясь в википедийность, процесс трансляции исходного кода в конечный JS код протекает следующим образом:
source code -(Lexer)-> tokens -(Parser)-> AST -(Compiler)-> js codeЧто тут происходит:
1) Lexer
Исходный код нашей программы разбивается на лексемы. По-простому это нахождение в исходном тексте ключевых слов, литералов, символов, идентификаторов и т.д.
Т.е. на выходе из этого (CoffeeScript):
a = true if a console.log('Hello, lexer')Мы получаем это (сокращенная запись):
[IDENTIFIER:"a"] [ASSIGN:"="] [BOOLEAN:"true"] [NEWLINE:"\n"] [NEWLINE:"\n"] [KEYWORD:"if"] [IDENTIFIER:"a"] [NEWLINE:"\n"] [INDENT:" "] [IDENTIFIER:"console"] [DOT:"."] [IDENTIFIER:"log"] [ROUND_BRAKET_START:"("] [STRING:"'Hello, lexer'"] [ROUND_BRAKET_END:")"] [NEWLINE:"\n"] [OUTDENT:""] [EOF:"EOF"]Так-как CoffeeScript отступо-чувствительный и не имеет явного выделения блока скобками < и >, блоки отделяются отступами ( INDENT ом и OUTDENT ом), которые по сути заменяет скобки.
2) Parser
Парсер составляет AST из токенов (лексем). Он обходит весь массив и рекурсивно подбирает подходящие паттерны, основываясь на типи токена или их последовательности.
Из полученных токенов в пункте 1, parser составит, примерно такое дерево (сокращенная запись):
< type: 'ROOT', // Основная нода нешего дерава nodes: [< type: 'VARIABLE', // a = true id: < type: 'IDENTIFIER', value: 'a' >, init: < type: 'LITERAL', value: true >>, < type: 'IF_STATEMENT', // Условное выражение test: < type: 'IDENTIFIER', value: 'a' >, consequent: < type: 'BLOCK_STATEMENT', nodes: [< type: 'EXPRESSION_STATEMENT', // Вызов console.log expression: < type: 'CALL_EXPRESSION', callee: < type: 'MEMBER_EXPRESSION', object: < type: 'IDENTIFIER', value: 'console' >, property: < type: 'IDENTIFIER', value: 'log' >>, arguments: [< type: 'LITERAL', value: 'Hello, lexer' >] > >] > >] >Не стоит пугаться объема дерева, на деле он генерируется рекурсивно и его создание не вызывает трудностей.
3) Compiler
Построение конечного кода по AST. Этот пункт можно заменить на компиляцию в байткод, или даже рантайм, но в рамках данной серии статей мы рассмотрим реализацию транслятора в другой язык программирования.
Компилятор (читай транслятор) преобразует Абстрактно-Синтаксическое Дерево в JavaScript код:
Вот и все. Большинство компиляторов работают именно по такому принципу (с незначительными изменениями. Иногда добавляют процесс стримминга исходного текста в поток символов, иногда напротив объединяют парсинг и компиляцию в один этап, но не нам их судить).
Habrlang
Итак, разобравшись с теорией, нам предстоит собрать свой язык программирования, у которого будет примерно следующий синтаксис (что-бы не особо париться, мы будем делать смесь из Ruby, Python и CoffeeScript):
#!/bin/habrlang # Hello habrlang def hello В следующей главе вы реализуем все основные классы нашего транслятора, и научим его транслировать комментарии Habrlang'а в JavaScript.
Объясняем бабушке, как написать свой язык программирования
Это игровая площадка, где я попытаюсь объяснить, как создать малюсенький язык программирования (Mu). Можно посмотреть вживую на открытые исходники здесь или скачать тут. Туториал можете прочитать прямо сейчас.

Пишем свой язык программирования (на Swift)
Для того, чтобы написать свой язык программирования, необязательно иметь степень в Computer Science, достаточно понимать 3 базовых шага.
Язык: Mu(μ)
Mu — это минимальный язык, который содержит постфиксный оператор, бинарную операцию и «одноциферные» числа.
Пример: (s 2 4) or (s (s 4 5) 4) or (s (s 4 5) (s 3 2))…

Подходы к двух- и трехступечатому проектированию, которые мы используем на проектах в EDISON Software Development Centre.
Шаги:
Lexer
В компьютерных науках лексический анализ — это процесс аналитического разбора входной последовательности символов (например, такой как исходный код на одном из языков программирования) с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в словах).
Группа символов входной последовательности, идентифицируемая на выходе процесса как токен, называется лексемой. В процессе лексического анализа производится распознавание и выделение лексем из входной последовательности символов.
— Википедия
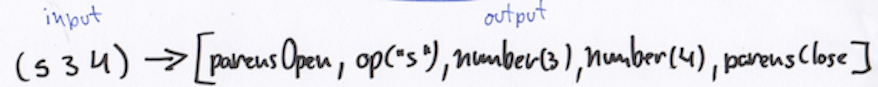
Из-за того, что Mu так мал — только один оператор и числа — вы можете просто совершать итерации ввода и проверять каждый символ.
enum Token < case parensOpen case op(String) case number(Int) case parensClose >struct Lexer < static func tokenize(_ input: String) ->[Token] < return input.characters.flatMap < switch $0 < case "(": return Token.parensOpen case ")": return Token.parensClose case "s": return Token.op($0.description) default: if "0". "9" ~= $0 < return Token.number(Int($0.description)!) >> return nil > > > let input = "(s (s 4 5) 4)" let tokens = Lexer.tokenize(input) Parser
Парсер или синтаксический анализатор — это часть программы, преобразующей входные данные (как правило, текст) в структурированный формат. Парсер выполняет синтаксический анализ текста.
Grammar:
expression: parensOpen operator primaryExpression primaryExpression parensClose primaryExpression: expression | number parensOpen: "(" parensClose: ")" operator: "s" number: 8Грамматика Mu — это бесконтекстная грамматика, что означает, что она описывает все возможные варианты строк в языке. Парсер начинает с верха (корня сгенерированного дерева) и двигается до самого нижнего узла.
Совет: код должен быть прямым представлением граммматики
func parseExpression() -> ExpressionNode < . firstPrimaryExpression = parsePrimaryExpression() secondPrimaryExpression = parsePrimaryExpression() . >func parseExpression() -> PrimaryExpressionNode
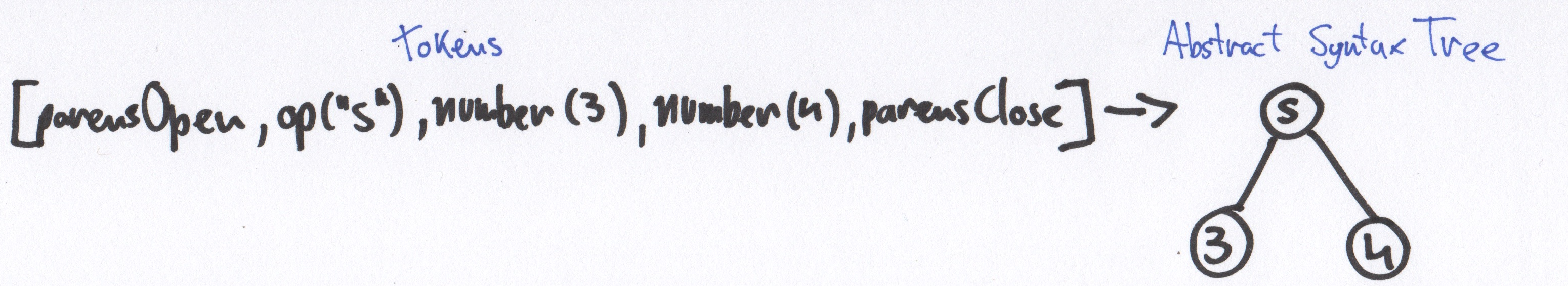
indirect enum PrimaryExpressionNode < case number(Int) case expression(ExpressionNode) >struct ExpressionNode < var op: String var firstExpression: PrimaryExpressionNode var secondExpression: PrimaryExpressionNode >struct Parser < var index = 0 let tokens: [Token] init(tokens: [Token]) < self.tokens = tokens >mutating func popToken() -> Token < let token = tokens[index] index += 1 return token >mutating func peekToken() -> Token < return tokens[index] >mutating func parse() throws -> ExpressionNode < return try parseExpression() >mutating func parseExpression() throws -> ExpressionNode < guard case .parensOpen = popToken() else < throw ParsingError.unexpectedToken >guard case let Token.op(_operator) = popToken() else < throw ParsingError.unexpectedToken >let firstExpression = try parsePrimaryExpression() let secondExpression = try parsePrimaryExpression() guard case .parensClose = popToken() else < throw ParsingError.unexpectedToken >return ExpressionNode(op: _operator, firstExpression: firstExpression, secondExpression: secondExpression) > mutating func parsePrimaryExpression() throws -> PrimaryExpressionNode < switch peekToken() < case .number: return try parseNumber() case .parensOpen: let expressionNode = try parseExpression() return PrimaryExpressionNode.expression(expressionNode) default: throw ParsingError.unexpectedToken >> mutating func parseNumber() throws -> PrimaryExpressionNode < guard case let Token.number(n) = popToken() else < throw ParsingError.unexpectedToken >return PrimaryExpressionNode.number(n) > > //MARK: Utils extension ExpressionNode: CustomStringConvertible < public var description: String < return "\(op) ->[\(firstExpression), \(secondExpression)]" > > extension PrimaryExpressionNode: CustomStringConvertible < public var description: String < switch self < case .number(let n): return n.description case .expression(let exp): return exp.description >> > let input = "(s 2 (s 3 5))" let tokens = Lexer.tokenize(input) var parser = Parser(tokens: tokens) var ast = try! parser.parse()Interpreter
В computer science, интерпретатор — это программа, которая последовательно выполняет инструкции, написанные на языке программирования или скриптовом языке, без предварительной компиляции в машинный код. (Википедия)
Интерпретатор Mu будет проходить через свои A.S.T и вычислять значения, применяя оператор к дочерним узлам.
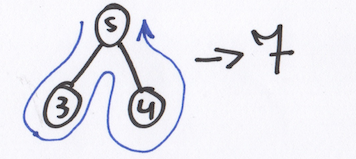
enum InterpreterError: Error < case unknownOperator >struct Interpreter < static func eval(_ expression: ExpressionNode) throws ->Int < let firstEval = try eval(expression.first) let secEval = try eval(expression.second) if expression.op == "s" < return firstEval + secEval >throw InterpreterError.unknownOperator > static func eval(_ prim: PrimaryExpressionNode) throws -> Int < switch prim < case .expression(let exp): return try eval(exp) case .number(let n): return Int(n) >> > let input = "(s (s 5 2) 4)" let tokens = Lexer.tokenize(input) var parser = Parser(tokens: tokens) let ast = try! parser.parse() try! Interpreter.eval(ast)Заключение
- Проходим по дереву, вычисляя значения, находящиеся внутри узлов (Interpreting). let result = try! Interpreter.eval(ast)
Resources
Свой язык, или как я устал от ассемблера и С
Это не гайд, не туториал и не исследование. Эта статья - просто история о том, как я решил создать свой язык для низкоуровневых штучек, отличного от ассемблера и С. Приятного прочтения!
Предыстория
Как вы знаете, я обожал (и до сих пор обожаю) язык ассемблера, а именно - fasm. Я уже давно его изучил и пользуюсь им, но постепенно стал давать слабину. Я устал писать код на ассемблере, так как это долго и довольно таки тяжело (рано, или поздно, это всё равно произошло бы). Понять мою любовь к этому языку можно прочитав мои предыдущие статьи: раз, два, три, четыре. Почему же я не стал использовать С? Он мне просто не нравится. Неудобно мне. Вот и всё.
Концепт
Концепт заключается в том, что человек указывает все данные для компиляции в главном файле с помощью директивы, например, format . Так же, есть два типа библиотек: встроенные (стандартные) и кастомные (пользовательские). Иначе говоря, либы и модули. Для использования shared object, dll и пр. будет отдельная директива. Указателей в языке не будет, а для разыменывания будет использоваться макрос OFFSET . Для работы с железом на все случаи жизни будут стдлибы. Синтаксис будет чем-то средним между Java, TS, fasm (для некоторых выражений) и Python.
Синтаксис
Это, пожалуй, первое, с чего я начал. Для начала, я написал пример кода, который устроит меня своим синтаксисом. Вышло как-то так:
format mbr.x86.16.executable; use Bios; use Console; fn main() -> Void
Я решил не сильно париться, поэтому использовал библиотеку parglare. Она очень легкая и удобная, всем рекомендую. Для описания синтаксиса парсер принимает строку в соответствующем формате, использует регулярные выражения (не надо осуждать регулярки, они всесильны!). Итак, вот такое описание синтаксиса у меня получилось:
sroot: sany*; sany: sformat | suse | sfn | sdefine; sformat: "format" tname ";"; suse: "using" tname ";"; sfn: "fn" tname "(" sargs? ")" "->" tname sbody; sargs: sarg ("," sarg)*; sarg: tname ":" tname; sbody: ""; sline: (scall | sequal | sdefine | sreturn) ";"; scall: tname "(" scallargs? ")"; scallargs: sexpr ("," sexpr)*; sequal: tname "=" sexpr ";"; sdefine: sarg ("=" sexpr)* ";"; sreturn: "return" sexpr?; sexpr: "(" sexpr ")" |(ssequence | tname) "[" tinteger "]" |sexpr "*" "*" sexpr |"-" sexpr |sexpr "*" sexpr |sexpr "/" sexpr |sexpr "+" sexpr |sexpr "-" sexpr |"!" sexpr |sexpr "&" sexpr |sexpr "|" sexpr |sexpr "^" sexpr |tinteger |tstring |tname |ssequence; ssequence: ""; terminals tstring: /"[^"]*"/; tname: /([A-Za-z_]\w*\.)*[A-Za-z_]\w*/; tinteger: /00?|8\d*/;Вышло кратко. А краткость - сестра таланта. Да и к тому же, так будет проще.
Компиляция в язык ассемблера (fasm)
Я долго ломал голову, как это полаконичней сделать, и никак не мог придумать решение. Через пару дней я наткнулся на статью про pyast64 (на медиум, по-моему). Она раскрыла мне глаза. В коде этого скрипта было все что мне нужно: и работа со стеком, и соглашение о вызовах, и пр и тп. Я очень шустро накидал константы:
SIMPLE_BINOPS = ( "add", "sub", "or", "and", "xor", "mul", "div" ) SIMPLE_UNOPS = ( "neg", "not" ) SIMPLE_TYPES = ( "integer", "string", "label" ) COMPLEX_BINOPS = ( "pow", "ind" ) MUTABLE = ( "integer" ) ASM_BINOP = """ pop qword rdx pop qword rax %s qword rax, rdx push qword rax""" ASM_DEF = """ %s d_%s %s""" ASM_EQU = """ pop qword rdx mov [%s], rdx""" ASM_LDR = """ push qword [%s]""" ASM_LEA = """ push qword %s""" ASM_PTR = """ push qword %s""" ASM_RET = "\n ret" ASM_SEQ = """ push %s """Дописать транслятор в ассемблер я ещё не успел, но до этого не долго осталось. Весь исходный код опубликован здесь: группа Telegram, здесь же можно обсудить и/или поддержать проект. Спасибо за внимание!