- Ответы на самые популярные вопросы об интерфейсе Map
- 0. Как перебрать все значения Map
- 1. Как конвертировать Map в List
- 2. Как отсортировать ключи мапы
- 3. Как отсортировать значения мапы
- 4. В чем разница между HashMap, TreeMap, и Hashtable
- 5. Как создать двунаправленную мапу
- 6. Как создать пустую Map
- Структуры данных в картинках. HashMap
- Создание объекта
- Добавление элементов
- Resize и Transfer
- Удаление элементов
- Итераторы
Ответы на самые популярные вопросы об интерфейсе Map


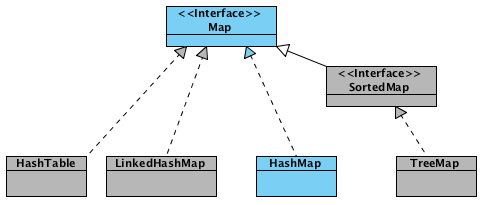
Привет! Сегодня мы дадим ответы на самые распространенные вопросы о Map, но для начала давай вспомним, что это такое. Map — это структура данных, которая содержит набор пар “ключ-значение”. По своей структуре данных напоминает словарь, поэтому ее часто так и называют. В то же время, Map является интерфейсом, и в стандартном jdk содержит основные реализации: Hashmap, LinkedHashMap, Hashtable, TreeMap. Самая используемая реализация — Hashmap, поэтому и будем ее использовать в наших примерах. Вот так выглядит стандартное создание и заполнение мапы:
Map map = new HashMap<>(); map.put(1, "string 1"); map.put(2, "string 2"); map.put(3, "string 3"); String string1 = map.get(1); String string2 = map.get(2); String string3 = map.get(3); 0. Как перебрать все значения Map
Перебор значений — самая частая операция, которую вы выполняете с мапами. Все пары (ключ-значение) хранятся во внутреннем интерфейсе Map.Entry, а чтобы получить их, нужно вызвать метод entrySet() . Он возвращает множество (Set) пар, которые можно перебрать в цикле:
for(Map.Entry entry: map.entrySet()) < // get key Integer key = entry.getKey(); // get value String value = entry.getValue(); >Или используя итератор: Iterator itr = map.entrySet().iterator(); while(itr.hasNext()) < Map.Entryentry = itr.next(); // get key Integer key = entry.getKey(); // get value String value = entry.getValue(); > 1. Как конвертировать Map в List
- keySet() — возвращает множество(Set) ключей;
- values() — возвращает коллекцию(Collection) значений;
- entrySet() — возвращает множество(Set) наборов “ключ-значение”.
// key list List keyList = new ArrayList<>(map.keySet()); // value list List valueList = new ArrayList<>(map.values()); // key-value list List> entryList = new ArrayList<>(map.entrySet()); 2. Как отсортировать ключи мапы
- Поместить Map.Entry в список и отсортировать его, используя Comparator. В компараторе будем сравнивать исключительно ключи пар:
List> list = new ArrayList(map.entrySet()); Collections.sort(list, new Comparator>() < @Override public int compare(Map.Entryo1, Map.Entry o2) < return o1.getKey() - o2.getKey(); >>);Collections.sort(list, Comparator.comparingInt(Map.Entry::getKey));SortedMap sortedMap = new TreeMap<>(new Comparator() < @Override public int compare(Integer o1, Integer o2) < return o1 - o2; >>);SortedMap sortedMap = new TreeMap<>(Comparator.comparingInt(o -> o));3. Как отсортировать значения мапы
Здесь стоит использовать подход, аналогичный первому для ключей — получать список значений и сортировать их в списке:
List > valuesList = new ArrayList(map.entrySet()); Collections.sort(list, new Comparator>() < @Override public int compare(Map.Entryo1, Map.Entry o2) < return o1.getValue().compareTo(o2.getValue()); >>);Collections.sort(list, Comparator.comparing(Map.Entry::getValue));4. В чем разница между HashMap, TreeMap, и Hashtable
- Порядок элементов. HashMap и Hashtable не гарантируют, что элементы будут храниться в порядке добавления. Кроме того, они не гарантируют, что порядок элементов не будет меняться со временем. В свою очередь, TreeMap гарантирует хранение элементов в порядке добавления или же в соответствии с заданным компаратором.
- Допустимые значения. HashMap позволяет иметь ключ и значение null, HashTable — нет. TreeMap может использовать значения null только если это позволяет компаратор. Без использования компаратора (при хранении пар в порядке добавления) значение null не допускается.
- Синхронизация. Только HashTable синхронизирована, остальные — нет. Если к мапе не будут обращаться разные потоки, рекомендуется использовать HashMap вместо HashTable.
| HashMap | HashTable | TreeMap | |
|---|---|---|---|
| Упорядоченность элементов | нет | нет | да |
| null в качестве значения | да | нет | да/нет |
| Потокобезопасность | нет | да | нет |
| Алгоритмическая сложность поиска элементов | O(1) | O(1) | O(log n) |
| Структура данных под капотом | хэш-таблица | хэш-таблица | красно-чёрное дерево |
5. Как создать двунаправленную мапу
Иногда появляется необходимость использовать структуру данных, в которой и ключи, и значения будут уникальными, то есть мапа будет содержать пары “ключ-ключ”. Такая структура данных позволяет создать "инвертированный просмотр/поиск" по мапе. То есть, мы можем найти ключ по его значению.Эту структуру данных называют двунаправленной мапой, которая, к сожалению, не поддерживается JDK. Но, к счастью, ее реализацию можно найти в библиотеках Apache Common Collections или Guava. Там она называется BidiMap и BiMap соответственно. Эти реализации вводят ограничения на уникальность ключей и значений. Таким образом получаются отношения one-to-one.
6. Как создать пустую Map
Map emptyMap = new HashMap<>(); Map emptyMap = Collections.emptyMap(); Структуры данных в картинках. HashMap
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.
HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
- table — Массив типа Entry[], который является хранилищем ссылок на списки (цепочки) значений;
- loadFactor — Коэффициент загрузки. Значение по умолчанию 0.75 является хорошим компромиссом между временем доступа и объемом хранимых данных;
- threshold — Предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле (capacity * loadFactor);
- size — Количество элементов HashMap-а;
// Инициализация хранилища в конструкторе // capacity - по умолчанию имеет значение 16 table = new Entry[capacity]; 
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
- Сначала ключ проверяется на равенство null. Если это проверка вернула true, будет вызван метод putForNullKey(value) (вариант с добавлением null-ключа рассмотрим чуть позже).
static int hash(int h) < h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); > Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением ''0'' метод hashCode() вернул значение 48, в итоге:
h ^ (h >>> 20) ^ (h >>> 12) = 48 h ^ (h >>> 7) ^ (h >>> 4) = 51 static int indexFor(int h, int length)
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
if (e.hash == hash && (e.key == key || key.equals(e.key)))
void addEntry(int hash, K key, V value, int index) < Entrye = table[index]; table[index] = new Entry(hash, key, value, e); . > 
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
- Пропускается, ключ не равен null
h ^ (h >>> 20) ^ (h >>> 12) = 106054 h ^ (h >>> 7) ^ (h >>> 4) = 99486 
- Все элементы цепочки, привязанные к table[0], поочередно просматриваются в поисках элемента с ключом null. Если такой элемент в цепочке существует, его значение перезаписывается.

- Пропускается, ключ не равен null
h ^ (h >>> 20) ^ (h >>> 12) = 104100 h ^ (h >>> 7) ^ (h >>> 4) = 101603 // В table[3] уже хранится цепочка состоящая из элемента ["0", "zero"] Entry e = table[index]; // Новый элемент добавляется в начало цепочки table[index] = new Entry(hash, key, value, e); 
Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
void resize(int newCapacity) < if (table.length == MAXIMUM_CAPACITY) < threshold = Integer.MAX_VALUE; return; >Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); > Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.

Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — "А может оно и не надо?").
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
hashmap = new HashMap(hashmap); Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).