What is R?
R is a language and environment for statistical computing and graphics. It is a GNU project which is similar to the S language and environment which was developed at Bell Laboratories (formerly AT&T, now Lucent Technologies) by John Chambers and colleagues. R can be considered as a different implementation of S. There are some important differences, but much code written for S runs unaltered under R.
R provides a wide variety of statistical (linear and nonlinear modelling, classical statistical tests, time-series analysis, classification, clustering, …) and graphical techniques, and is highly extensible. The S language is often the vehicle of choice for research in statistical methodology, and R provides an Open Source route to participation in that activity.
One of R’s strengths is the ease with which well-designed publication-quality plots can be produced, including mathematical symbols and formulae where needed. Great care has been taken over the defaults for the minor design choices in graphics, but the user retains full control.
R is available as Free Software under the terms of the Free Software Foundation’s GNU General Public License in source code form. It compiles and runs on a wide variety of UNIX platforms and similar systems (including FreeBSD and Linux), Windows and MacOS.
The R environment
R is an integrated suite of software facilities for data manipulation, calculation and graphical display. It includes
- an effective data handling and storage facility,
- a suite of operators for calculations on arrays, in particular matrices,
- a large, coherent, integrated collection of intermediate tools for data analysis,
- graphical facilities for data analysis and display either on-screen or on hardcopy, and
- a well-developed, simple and effective programming language which includes conditionals, loops, user-defined recursive functions and input and output facilities.
The term “environment” is intended to characterize it as a fully planned and coherent system, rather than an incremental accretion of very specific and inflexible tools, as is frequently the case with other data analysis software.
R, like S, is designed around a true computer language, and it allows users to add additional functionality by defining new functions. Much of the system is itself written in the R dialect of S, which makes it easy for users to follow the algorithmic choices made. For computationally-intensive tasks, C, C++ and Fortran code can be linked and called at run time. Advanced users can write C code to manipulate R objects directly.
Many users think of R as a statistics system. We prefer to think of it as an environment within which statistical techniques are implemented. R can be extended (easily) via packages. There are about eight packages supplied with the R distribution and many more are available through the CRAN family of Internet sites covering a very wide range of modern statistics.
R has its own LaTeX-like documentation format, which is used to supply comprehensive documentation, both on-line in a number of formats and in hardcopy.
© The R Foundation. For queries about this web site, please contact ; for queries about R itself, please consult the Getting Help section.
📌 Структура R
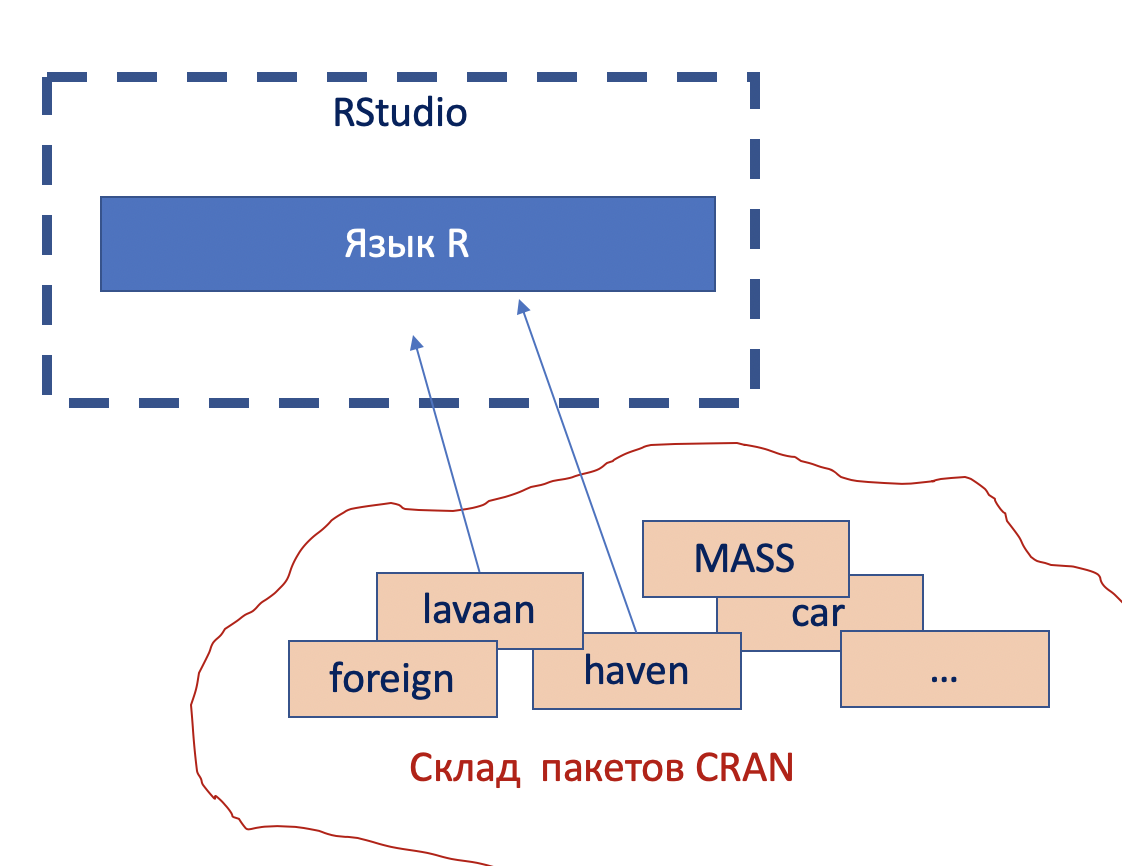
IDE — integrated development environment, программные пакеты, которые облегчают программирование.
RStudio — интегрированная система для программирования в R. Нужно дополнительно устанавливать.
❗️Есть пробная онлайн-версия: https://rstudio.cloud/ — но медленная.
Установка и использование пакетов
install.packages("readxl") # Один раз на каждом компьютере library("readxl") # Перед использованием. После каждого перезапуска R. # Кстати, хэштэгом обозначают комментарии, которые не считываются R.🐣 Ключевые структуры R
Объекты
Об R можно думать как об умном калькуляторе.
В верхнем окошке вы видите то, что вводит человек, в нижнем — то, чем отвечает на это компьютер.
[1] в ответе компьютера обозначает порядковый номер значения.
В дополнение к вычислениям, R может хранить в памяти различные данные (в широком смысле) — они называются объектами.
❗️Названия объектов должны начинаться c буквы или точки.
❗️R различает большие и маленькие буквы.
Виды (классы) объектов
Объектами могут быть любые фрагменты информации. Это может быть одно значение, вектор однотипных значений (переменная), список разнотипных значений, таблица, или даже список других объектов. И многое другое. Вид информации, хранящейся в объекте, называется класс объекта.
a) Типы переменных
- числовые numeric для интервальных непрерывных переменных;
- так называемые факторы factor для номинальных и порядковых ( ordered factor ) переменных;
- строчные string или character — для текстовых переменных;
- логические logical , переменные принимающие только значение TRUE или FALSE.
При чтении данных многие функции автоматически определяют тип переменных, но все равно лучше проверять.
numeric
string/character
factor (unordered)
[1] horsebean horsebean horsebean Levels: casein horsebean linseed meatmeal soybean sunflowerordered factor
[1] Primary Primary Levels: Primary < Secondary < Higherlogical
b) Структуры хранения данных
- векторы c - для отдельных переменных;
- двухмерные таблицы data.frame - наиболее используемые и привычные таблицы данных;
- матрицы matrix - двухмерная таблица, удобныя для матричных преобразований,
- массивы array - многомерная таблица,
- списки list - может содержать данные разных типов и любые объекты.
векторы c()
data.frame
var.one var.two 1 1 A 2 2 B 3 3 C matrix
[,1] [,2] [,3] [,4] [,5] [1,] 1 7 13 19 25 [2,] 2 8 14 20 26 [3,] 3 9 15 21 27 [4,] 4 10 16 22 28 [5,] 5 11 17 23 29 [6,] 6 12 18 24 30 array
, , 1 [,1] [,2] [,3] [,4] [,5] [1,] 1 4 7 10 13 [2,] 2 5 8 11 14 [3,] 3 6 9 12 15 , , 2 [,1] [,2] [,3] [,4] [,5] [1,] 16 19 22 25 28 [2,] 17 20 23 26 29 [3,] 18 21 24 27 30list
$`можно дать имя одному или всем элементам` [1] 1 2 3 4 5 [[2]] [1] "a" "c" [[3]] [1] "Просто единичная строка"Операторы
С объектами можно производить различные операции. Типичные операции можно осуществлять с помощью специальных символов — операторов. Создадим два объекта a и b и сложим их значения:
Функции
Функции – это типовые операции, которые, чтобы не прописать заново, можно сохранять.
Весь R работает на функциях.
Например, можно подсчитать сумму, применив функцию sum() к числовому вектору.
mean() вычисляет среднюю, sd() - стандартное отклонение средней.
Другая простейшая функция c() - она объединяет ряд значений в вектор и конвертирует их в один и тот же тип.
In and Out
В каждой функции есть вводные параметры (аргументы), и ее продукт, результат, или то, что функция возвращает.
Форма
Большинство функций имеет форму:
НАЗВАНИЕ_ФУНКЦИИ(аргумент1 = "умолчание", аргумент2 = "умолчание2", . ) Иногда значение по умолчанию не задано, такие аргументы нужно обязательно указывать - обязательные аргументы. Аргументы, имеющие значение по умолчанию называются необязательными.
У каждого аргумента есть имя .
Количество и имена аргументов в каждой функции свои собственные (но могут быть и одинаковыми).
Пример
Функция subset имеет три обязательных аргумента, у которых нет умолчаний
- x - массив, который фильтруем,
- subset - какие строки из массива х нужно оставить,
- select - какие переменные из массива нужно оставить.
А в функции c() [то есть c ombine] нет умолчаний, у аргументов нет имен и количество их не ограничено. Она возвращает вектор, объединяющий все данные ей аргументы.
Результат
Разные функции возвращают разные типы объектов, это может быть одно число, строка, массив данных, список, таблица, график, и так далее. В документации к каждой функции есть разел Value, где указывается, что возвращает функция.
Использование функций
Аргументы
Приписывание значений аргументам возможно только с использованием = .
❗️Если нужно проверить равенство, необходимо использовать == . Например: a == b вернет TRUE или FALSE, a = b не вернет ничего, но создаст (перезапишет) объект а скоровав в него значение объекта b .
Если мы решили использовать значение по умолчанию, можно пропустить аргумент. Можно также пропустить имя аргумента, но тогда нужно вводить аргументы в правильной последовательности.
# Эти строки эквивалентны: subset(x = mydata, subset = age > 65, select = c("health", "income")) subset( mydata, age > 65, c("health", "income")) Результат
В большинстве случаев результат работы функции нужно сохранять.
# Эта строка сохранит подмассив пожилых респондентов и только две переменных в объект old.respondents: old.respondents 65, c("health", "income")) ❗️Если не сохранить результат работы функции в объект, вы увидите только часть информации в консоли, а сам результат потеряется.
Если результат сохранен в объект, в консоли обычно ничего не выводится.