- Project Jupyter Documentation#
- What is a Notebook?#
- Where do I start?#
- More information#
- Sub-project documentation#
- Среда программирования jupiter notebook
- JupyterLab: A Next-Generation Notebook Interface
- Jupyter Notebook: The Classic Notebook Interface
- Language of choice
- Share notebooks
- Interactive output
- Big data integration
- Pluggable authentication
- Centralized deployment
- Container friendly
- Code meets data
- Voilà: Share your results
- Currently in use at
- Open Standards for Interactive Computing
- Notebook Document Format
- Interactive Computing Protocol
- The Kernel
- Руководство по Jupyter Notebook для начинающих
- Настройка Jupyter Notebook
- Основы Jupyter Notebook
- Добавление описания к notebook
- Интерактивная наука о данных
- Меню
Project Jupyter Documentation#
Welcome to the Project Jupyter documentation site. Jupyter is a large umbrella project that covers many different software offerings and tools, including the popular Jupyter Notebook and JupyterLab web-based notebook authoring and editing applications. The Jupyter project and its subprojects all center around providing tools (and standards) for interactive computing with computational notebooks .
What is a Notebook?#
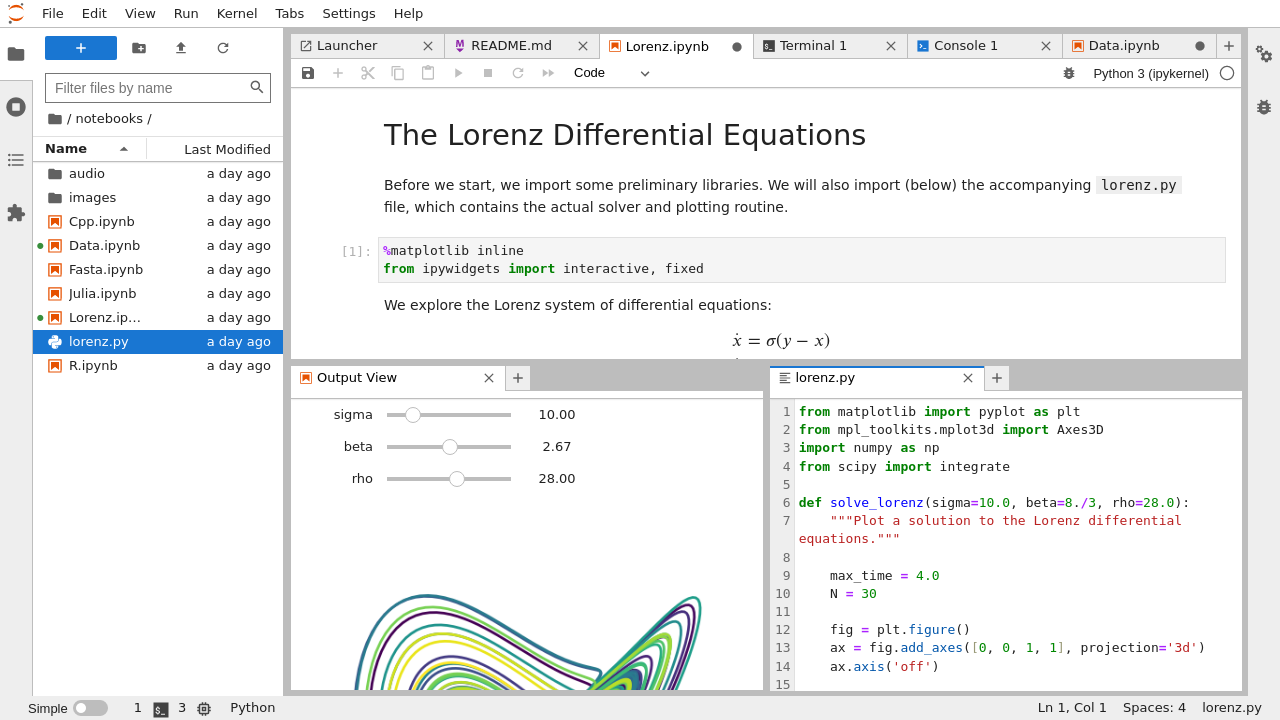
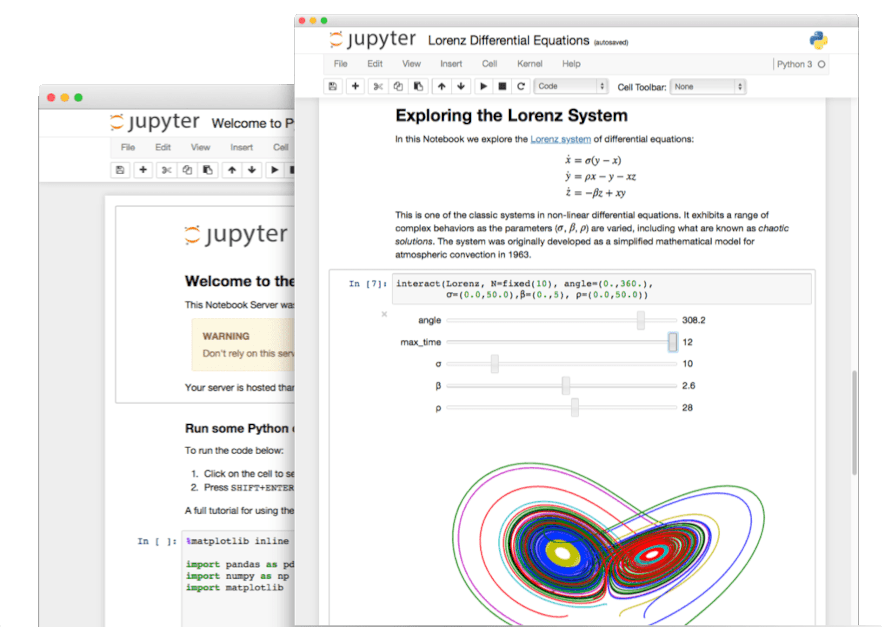
Pictured: A computational notebook document, shown inside JupyterLab
A notebook is a shareable document that combines computer code, plain language descriptions, data, rich visualizations like 3D models, charts, graphs and figures, and interactive controls. A notebook, along with an editor (like JupyterLab), provides a fast interactive environment for prototyping and explaining code, exploring and visualizing data, and sharing ideas with others.
Where do I start?#
Most people begin with Jupyter by installing an editing application that fits their preferences, like JupyterLab or Jupyter Notebook, and making their first notebook document:
- Jupyter Notebook offers a simplified, lightweight notebook authoring experience
- JupyterLab offers a feature-rich, tabbed multi-notebook editing environment with additional tools like a customizable interface layout and system console
- And more… read about additional notebook interfaces here !
You can also develop your own extensions or applications on top of existing Jupyter software. Check out the subproject sites below for more information.
More information#
These are a few high-level topics to help you learn more about the Jupyter community and ecosystem.
Sustainability and growth
How to contribute to the projects
Narratives of common deployment scenarios
New features, upgrades, deprecation notes, and bug fixes
An interactive Python kernel and REPL
Documentation for advanced use-cases
Sub-project documentation#
Individual sub-projects are typically organized around a key feature of the Jupyter ecosystem, and have their own community, documentation and governance. Below is a list of documentation for major parts of the Jupyter ecosystem.
Среда программирования jupiter notebook
Free software, open standards, and web services for interactive computing across all programming languages
JupyterLab: A Next-Generation Notebook Interface
JupyterLab is the latest web-based interactive development environment for notebooks, code, and data. Its flexible interface allows users to configure and arrange workflows in data science, scientific computing, computational journalism, and machine learning. A modular design invites extensions to expand and enrich functionality.
Jupyter Notebook: The Classic Notebook Interface
The Jupyter Notebook is the original web application for creating and sharing computational documents. It offers a simple, streamlined, document-centric experience.
Language of choice
Jupyter supports over 40 programming languages, including Python, R, Julia, and Scala.
Share notebooks
Notebooks can be shared with others using email, Dropbox, GitHub and the Jupyter Notebook Viewer.
Interactive output
Your code can produce rich, interactive output: HTML, images, videos, LaTeX, and custom MIME types.
Big data integration
Leverage big data tools, such as Apache Spark, from Python, R, and Scala. Explore that same data with pandas, scikit-learn, ggplot2, and TensorFlow.
A multi-user version of the notebook designed for companies, classrooms and research labs
Pluggable authentication
Manage users and authentication with PAM, OAuth or integrate with your own directory service system.
Centralized deployment
Deploy the Jupyter Notebook to thousands of users in your organization on centralized infrastructure on- or off-site.
Container friendly
Use Docker and Kubernetes to scale your deployment, isolate user processes, and simplify software installation.
Code meets data
Deploy the Notebook next to your data to provide unified software management and data access within your organization.
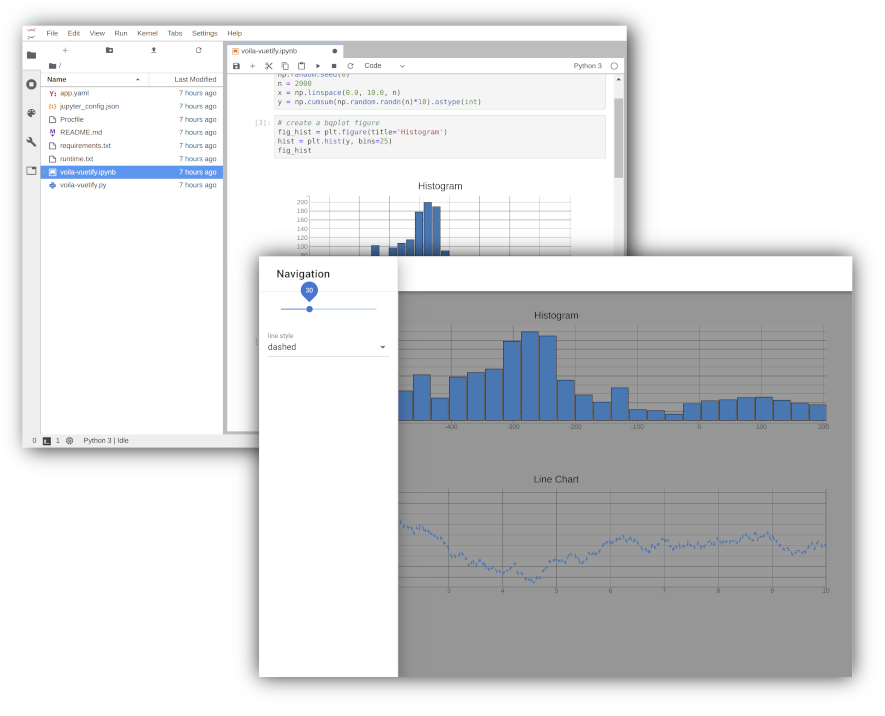
Voilà: Share your results
Voilà helps communicate insights by transforming notebooks into secure, stand-alone web applications that you can customize and share.
Currently in use at
Open Standards for Interactive Computing
Project Jupyter promotes open standards that third-party developers can leverage to build customized applications. Think HTML and CSS for interactive computing on the web.
Notebook Document Format
Jupyter Notebooks are an open document format based on JSON. They contain a complete record of the user’s sessions and include code, narrative text, equations, and rich output.
Interactive Computing Protocol
The Notebook communicates with computational Kernels using the Interactive Computing Protocol, an open network protocol based on JSON data over ZMQ, and WebSockets.
The Kernel
Kernels are processes that run interactive code in a particular programming language and return output to the user. Kernels also respond to tab completion and introspection requests.
Руководство по Jupyter Notebook для начинающих
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
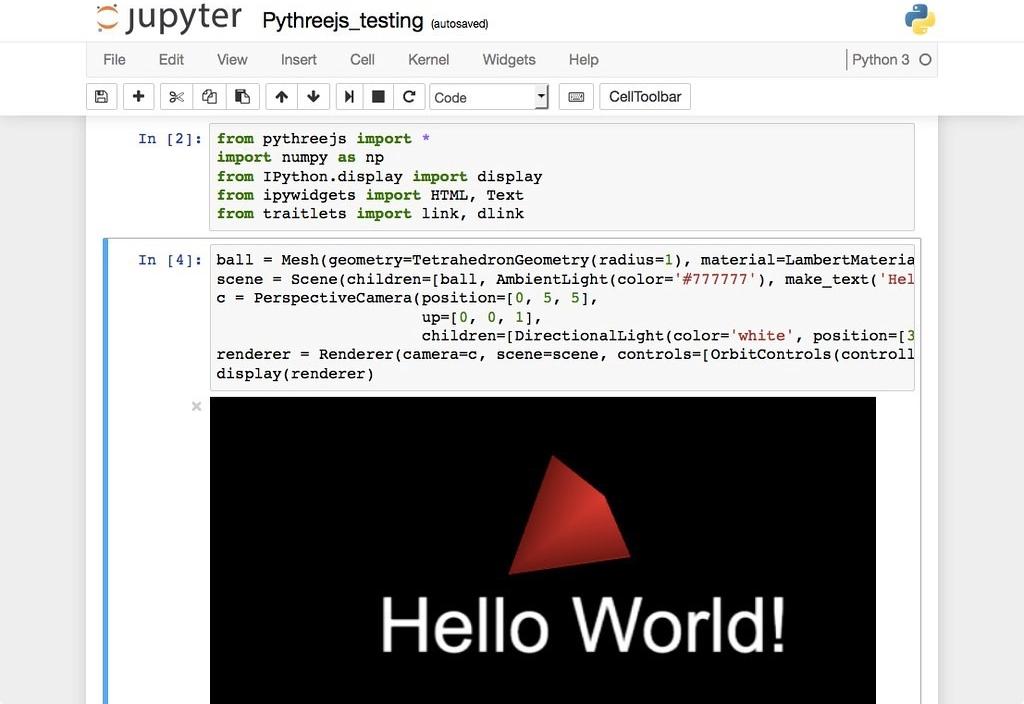
Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
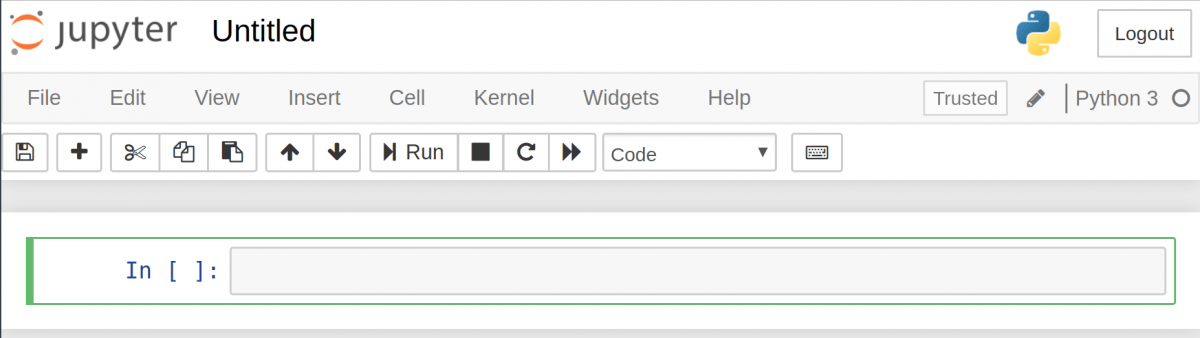
Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George’s Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».
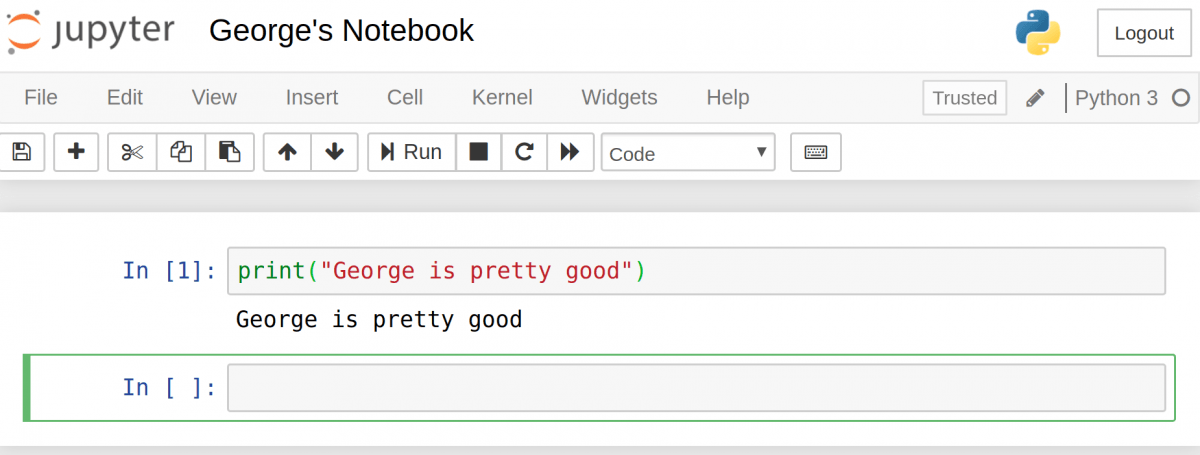
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.
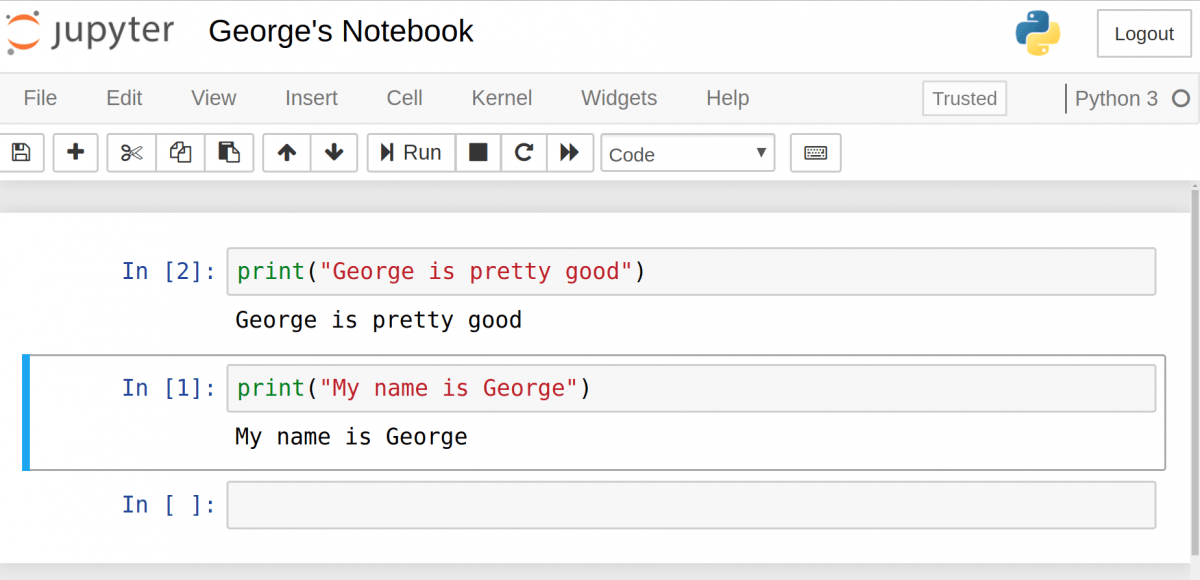
Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
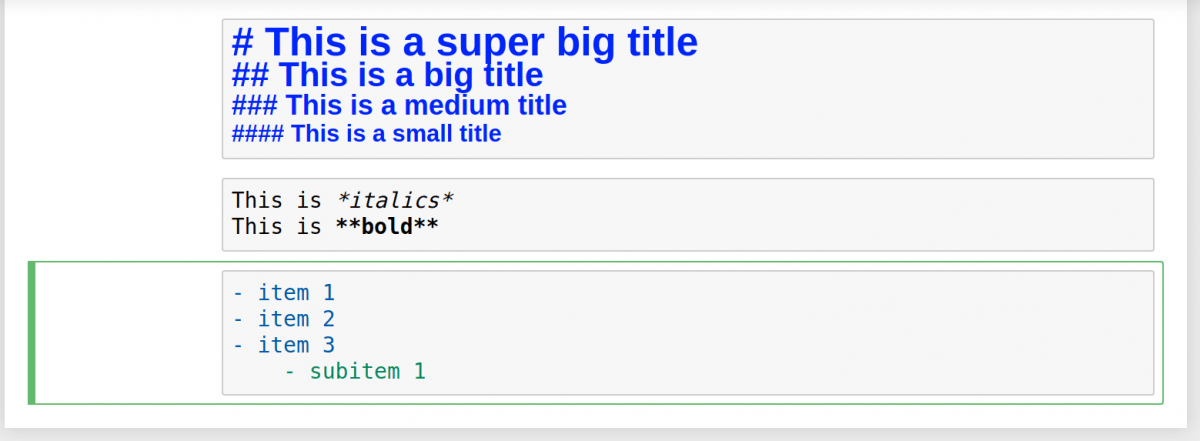
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа # . Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше # , тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного # . Затем список и описание всех библиотек, которые необходимо импортировать.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

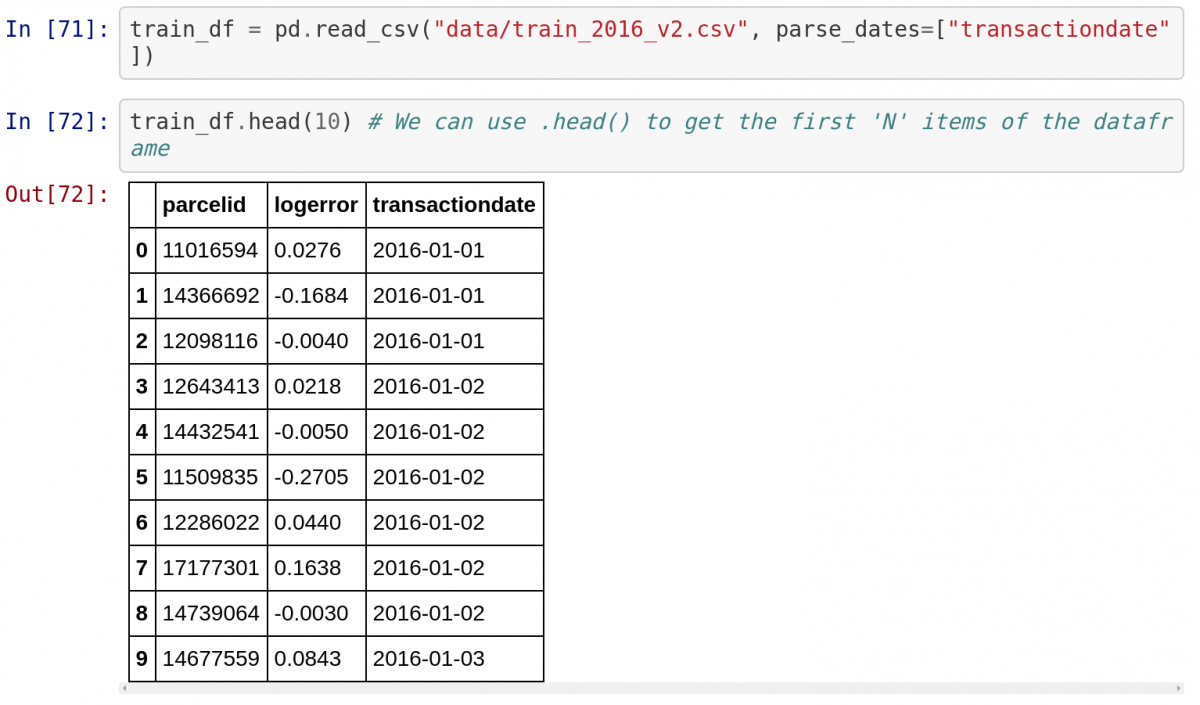
Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!
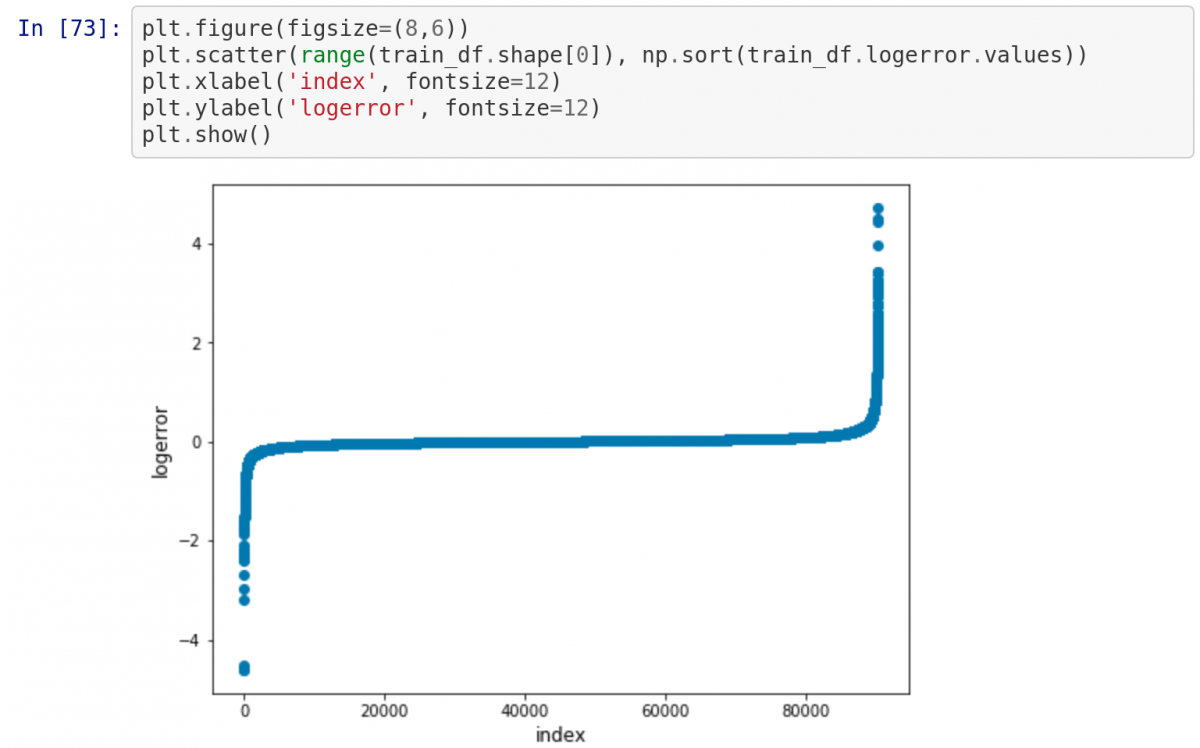
Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
Это простейший способ создания интерактивного проекта Data Science!
Меню
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.