ShellSort
Shell sort is mainly a variation of Insertion Sort. In insertion sort, we move elements only one position ahead. When an element has to be moved far ahead, many movements are involved. The idea of ShellSort is to allow the exchange of far items. In Shell sort, we make the array h-sorted for a large value of h. We keep reducing the value of h until it becomes 1. An array is said to be h-sorted if all sublists of every h’th element are sorted.
Step 1 − Start
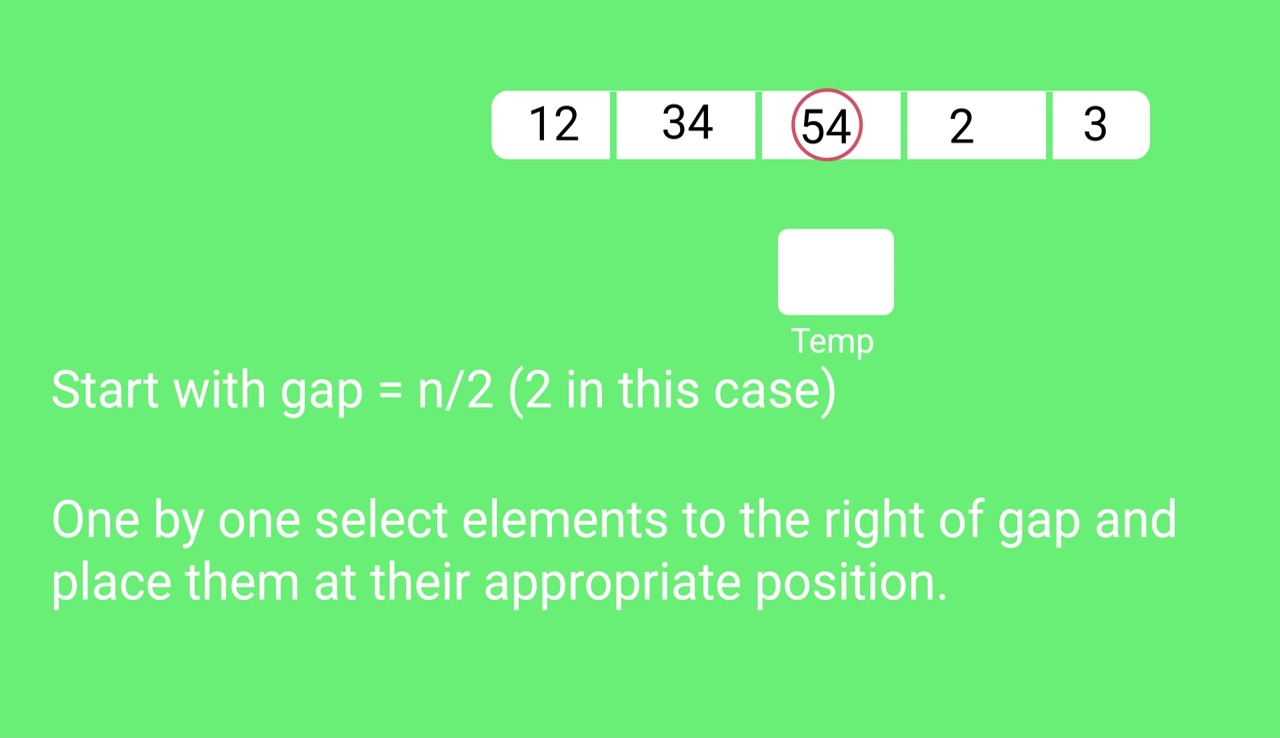
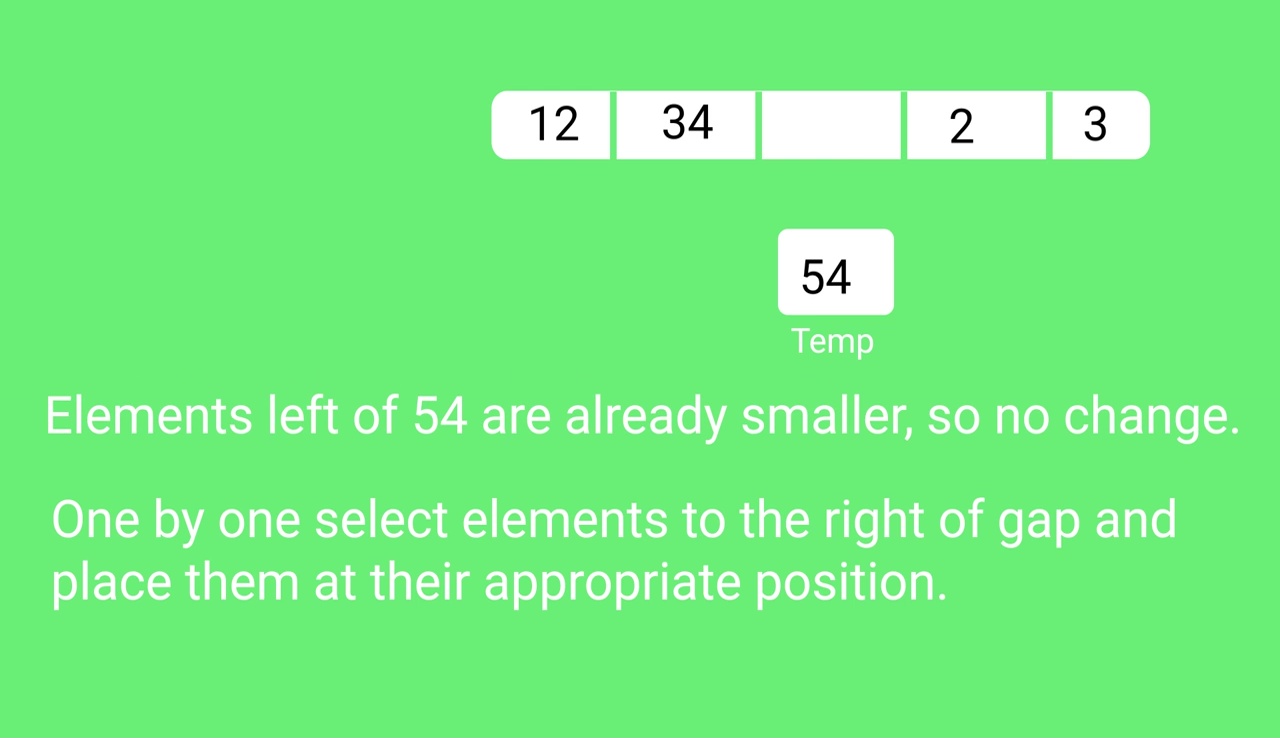
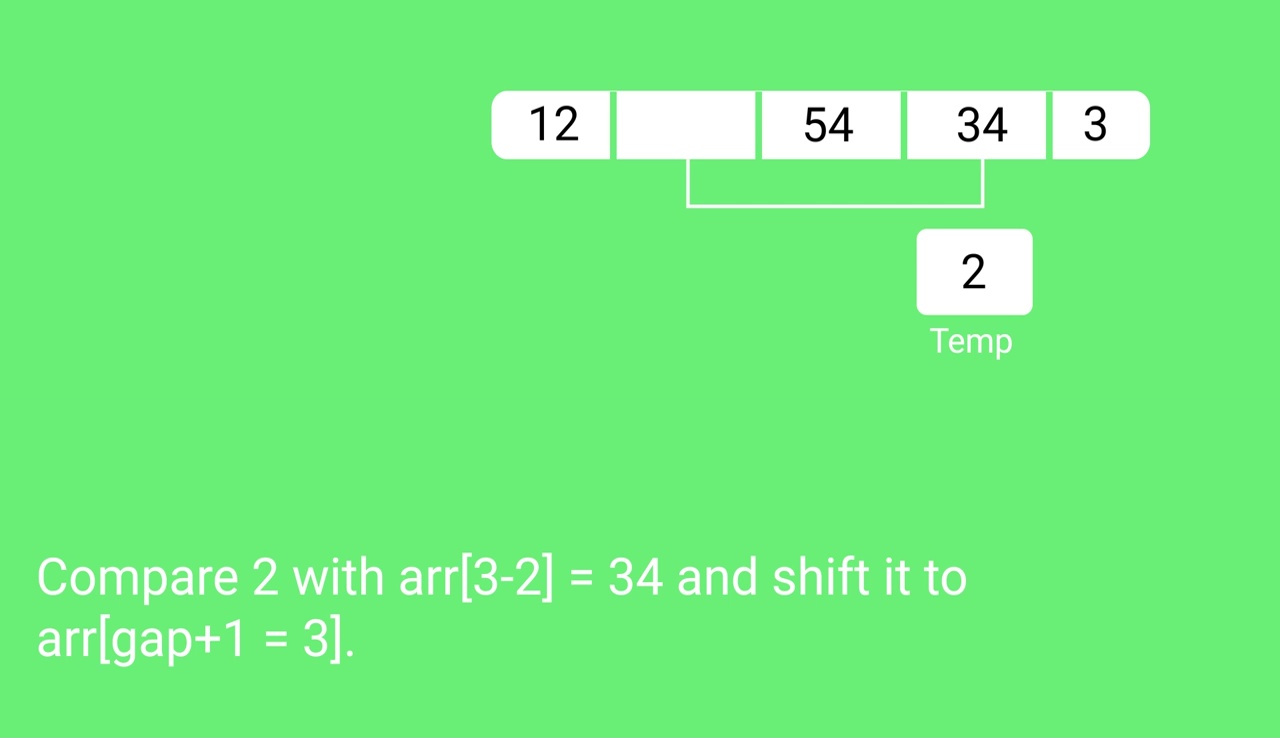
Step 2 − Initialize the value of gap size. Example: h
Step 3 − Divide the list into smaller sub-part. Each must have equal intervals to h
Step 4 − Sort these sub-lists using insertion sort
Step 5 – Repeat this step 2 until the list is sorted.
Step 6 – Print a sorted list.
Step 7 – Stop.
Pseudocode :
PROCEDURE SHELL_SORT(ARRAY, N)
WHILE GAP < LENGTH(ARRAY) /3 :
GAP = ( INTERVAL * 3 ) + 1
END WHILE LOOP
WHILE GAP > 0 :
FOR (OUTER = GAP; OUTER < LENGTH(ARRAY); OUTER++):
INSERTION_VALUE = ARRAY[OUTER]
INNER = OUTER;
WHILE INNER > GAP-1 AND ARRAY[INNER – GAP] >= INSERTION_VALUE:
ARRAY[INNER] = ARRAY[INNER – GAP]
INNER = INNER – GAP
END WHILE LOOP
ARRAY[INNER] = INSERTION_VALUE
END FOR LOOP
GAP = (GAP -1) /3;
END WHILE LOOP
END SHELL_SORT
Following is the implementation of ShellSort.
C++
Java
Python3
C#
Javascript
Array before sorting: 12 34 54 2 3 Array after sorting: 2 3 12 34 54
Time Complexity: Time complexity of the above implementation of Shell sort is O(n 2 ). In the above implementation, the gap is reduced by half in every iteration. There are many other ways to reduce gaps which leads to better time complexity. See this for more details.
Worst Case Complexity
The worst-case complexity for shell sort is O(n 2 )
Best Case Complexity
When the given array list is already sorted the total count of comparisons of each interval is equal to the size of the given array.
So best case complexity is Ω(n log(n))
Average Case Complexity
The shell sort Average Case Complexity depends on the interval selected by the programmer.
θ(n log(n)2).
THE Average Case Complexity: O(n*log n)~O(n 1.25 )
Space Complexity
The space complexity of the shell sort is O(1).
Questions:
1. Which is more efficient shell or heap sort?
Ans. As per big-O notation, shell sort has O(n^) average time complexity whereas, heap sort has O(N log N) time complexity. According to a strict mathematical interpretation of the big-O notation, heap sort surpasses shell sort in efficiency as we approach 2000 elements to be sorted.
Note:- Big-O is a rounded approximation and analytical evaluation is not always 100% correct, it depends on the algorithms’ implementation which can affect actual run time.
Shell Sort Applications
1. Replacement for insertion sort, where it takes a long time to complete a given task.
2. To call stack overhead we use shell sort.
3. when recursion exceeds a particular limit we use shell sort.
4. For medium to large-sized datasets.
5. In insertion sort to reduce the number of operations.



Quiz on Shell Sort
Other Sorting Algorithms on GeeksforGeeks/GeeksQuiz:
Solve DSA problems on GfG Practice.
Shell Sort in Java
![]()
The Kubernetes ecosystem is huge and quite complex, so it’s easy to forget about costs when trying out all of the exciting tools.
To avoid overspending on your Kubernetes cluster, definitely have a look at the free K8s cost monitoring tool from the automation platform CAST AI. You can view your costs in real time, allocate them, calculate burn rates for projects, spot anomalies or spikes, and get insightful reports you can share with your team.
Connect your cluster and start monitoring your K8s costs right away:
![]()
We rely on other people’s code in our own work. Every day.
It might be the language you’re writing in, the framework you’re building on, or some esoteric piece of software that does one thing so well you never found the need to implement it yourself.
The problem is, of course, when things fall apart in production — debugging the implementation of a 3rd party library you have no intimate knowledge of is, to say the least, tricky.
Lightrun is a new kind of debugger.
It’s one geared specifically towards real-life production environments. Using Lightrun, you can drill down into running applications, including 3rd party dependencies, with real-time logs, snapshots, and metrics.
Learn more in this quick, 5-minute Lightrun tutorial:
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes:
![]()
DbSchema is a super-flexible database designer, which can take you from designing the DB with your team all the way to safely deploying the schema.
The way it does all of that is by using a design model, a database-independent image of the schema, which can be shared in a team using GIT and compared or deployed on to any database.
And, of course, it can be heavily visual, allowing you to interact with the database using diagrams, visually compose queries, explore the data, generate random data, import data or build HTML5 database reports.
![]()
The Kubernetes ecosystem is huge and quite complex, so it’s easy to forget about costs when trying out all of the exciting tools.
To avoid overspending on your Kubernetes cluster, definitely have a look at the free K8s cost monitoring tool from the automation platform CAST AI. You can view your costs in real time, allocate them, calculate burn rates for projects, spot anomalies or spikes, and get insightful reports you can share with your team.
Connect your cluster and start monitoring your K8s costs right away:
We’re looking for a new Java technical editor to help review new articles for the site.
1. Introduction
In this tutorial, we’ll describe the Shell sort algorithm in Java.
2. The Shell Sort Overview
2.1. Description
Let’s first describe the Shell sort algorithm so we know what we’re trying to implement.
Shell sort is based on the Insertion sorting algorithm, and it belongs to the group of very efficient algorithms. In general, the algorithm breaks an original set into smaller subsets and then each of those is sorted using Insertion sort.
But, how it makes the subsets is not straightforward. It doesn’t choose neighboring elements to form a subset as we might expect. Rather, shell sort uses the so-called interval or gap for subset creation. For example, if we have the gap I, it means that one subset will contain the elements that are I positions apart.
Firstly, the algorithm sorts the elements that are far away from each other. Then, the gap becomes smaller and closer elements are compared. This way, some elements that aren’t in a correct position can be positioned faster than if we made the subsets out of the neighboring elements.
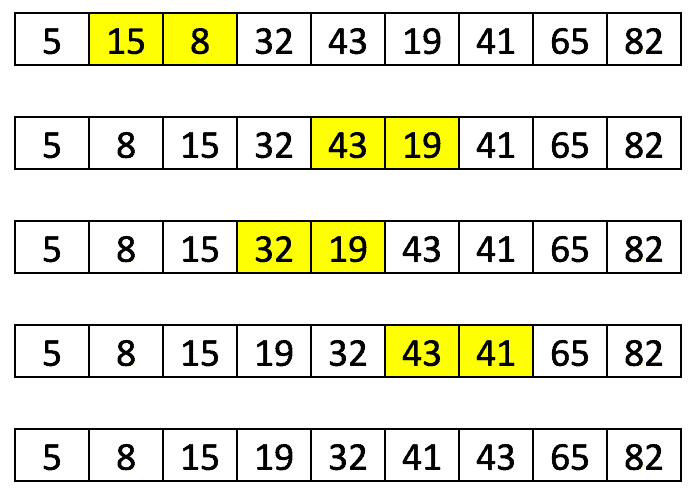
2.2. An Example
Let’s see this in the example with the gaps of 3 and 1 and the unsorted list of 9 elements:

If we follow the above description, in the first iteration, we’ll have three subsets with 3 elements (highlighted by the same color):

After sorting each of the subsets in the first iteration, the list would look like:

We can note that, although we don’t have a sorted list yet, the elements are now closer to desired positions.
Finally, we need to do one more sort with the increment of one and it’s actually a basic insertion sort. The number of shifting operations that we need to perform to sort a list is now smaller than it would be the case if we didn’t do the first iteration:
2.3. Choosing the Gap Sequences
As we mentioned, the shell sort has a unique way of choosing gap sequences. This is a difficult task and we should be careful not to choose too few or too many gaps. More details can be found in the most proposed gap sequences listing.
3. Implementation
Let’s now take a look at the implementation. We’ll use Shell’s original sequence for interval increments:
N/2, N/4, …, 1 (continuously dividing by 2)The implementation itself is not too complex:
public void sort(int arrayToSort[]) < int n = arrayToSort.length; for (int gap = n / 2; gap >0; gap /= 2) < for (int i = gap; i < n; i++) < int key = arrayToSort[i]; int j = i; while (j >= gap && arrayToSort[j - gap] > key) < arrayToSort[j] = arrayToSort[j - gap]; j -= gap; >arrayToSort[j] = key; > > >We first created a gap sequence with a for loop and then did the insertion sort for each gap size.
Now, we can easily test our method:
@Test void givenUnsortedArray_whenShellSort_thenSortedAsc() < int[] input = ; ShellSort.sort(input); int[] expected = ; assertArrayEquals("the two arrays are not equal", expected, input); >4. Complexity
Generally, the Shell sort algorithm is very efficient with medium-sized lists. The complexity is difficult to determine since it depends a lot on the gap sequence, but the time complexity varies between O(N) and O(N^2).
The worst-case space complexity is O(N) with O(1) auxiliary space.
5. Conclusion
In this tutorial, we described Shell sort and illustrated how we can implement it in Java.
As usual, the entire code could be found over on GitHub.
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes: