- html-stripper 0.3
- Подробности проекта
- Ссылки проекта
- Статистика
- Метаданные
- Сопровождающие
- Классификаторы
- История выпусков Уведомления о выпусках | Лента RSS
- Загрузка файлов
- Source Distribution
- Хеши для html_stripper-0.3.tar.gz
- Помощь
- О PyPI
- Внесение вклада в PyPI
- Использование PyPI
- Python stripping html tags
- # Table of Contents
- # Remove the HTML tags from a String in Python
- # Remove the HTML tags from a String using xml.etree.ElementTree
- # Remove the HTML tags from a String using lxml
- # Remove the HTML tags from a String using BeautifulSoup
- # Remove the HTML tags from a String using HTMLParser in Python
- # Additional Resources
- Python: 5 ways to remove HTML tags from a string
- Using lxml
- Using Regular Expressions
- Using BeautifulSoup
- Using a for loop and if…else statements
- Using HTMLParser
- strip-tags
- Keeping the markup for specified tags
- This is the heading
- As a Python library
- strip-tags —help
- Development
html-stripper 0.3
A simple package to extract text from (even broken/invalid) HTML. No dependencies, it just uses Python’s internal HTMLParser with a few tweaks.
Подробности проекта
Ссылки проекта
Статистика
Метаданные
Лицензия: GNU General Public License v3 (GPLv3)
Требует: Python >=3.6
Сопровождающие
Классификаторы
История выпусков Уведомления о выпусках | Лента RSS
Загрузка файлов
Загрузите файл для вашей платформы. Если вы не уверены, какой выбрать, узнайте больше об установке пакетов.
Source Distribution
Uploaded 30 июл. 2020 г. source
Хеши для html_stripper-0.3.tar.gz
| Алгоритм | Хеш-дайджест | |
|---|---|---|
| SHA256 | b9ea66bc75d00adc06447f3c3a278899c10cf12fad0c0faab39457057b4056b9 | Копировать |
| MD5 | 50dfb87e9e4fe54b52f35dfff89cca5e | Копировать |
| BLAKE2b-256 | 21e0c6b141679eed08bb139a7a82f36ed30336b15d69c9b2c4a735549a53efad | Копировать |
Помощь
О PyPI
Внесение вклада в PyPI
Использование PyPI
Разработано и поддерживается сообществом Python’а для сообщества Python’а.
Пожертвуйте сегодня!
PyPI», «Python Package Index» и логотипы блоков являются зарегистрированными товарными знаками Python Software Foundation.
Python stripping html tags
Last updated: Feb 19, 2023
Reading time · 4 min

# Table of Contents
# Remove the HTML tags from a String in Python
Use the re.sub() method to remove the HTML tags from a string.
The re.sub() method will remove all of the HTML tags in the string by replacing them with empty strings.
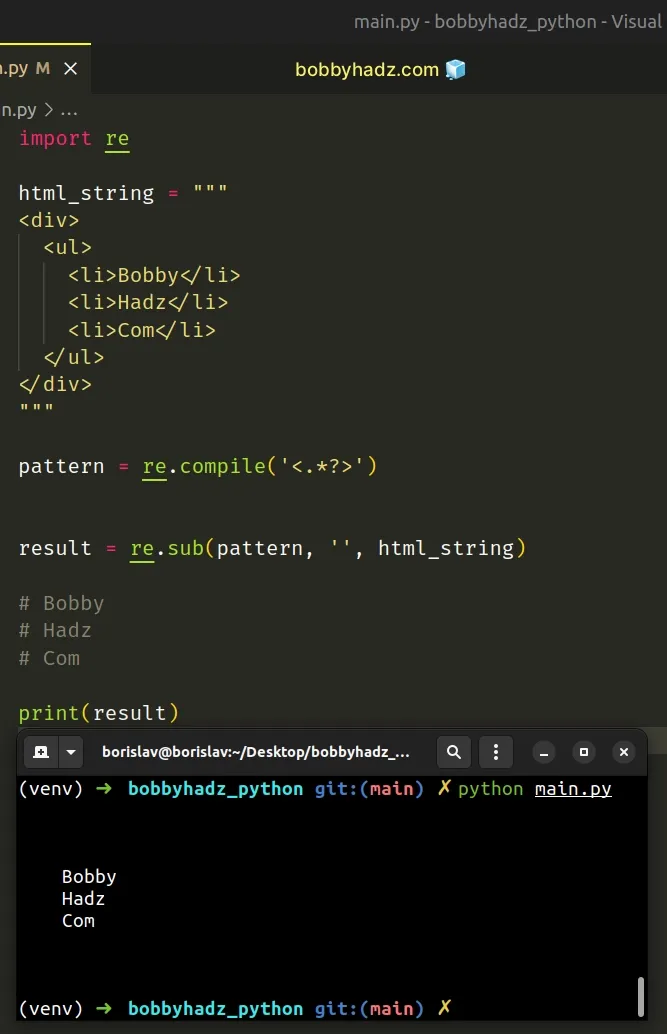
The code sample uses a regular expression to strip the HTML tags from a string.
The re.sub method returns a new string that is obtained by replacing the occurrences of the pattern with the provided replacement.
If the pattern isn’t found, the string is returned as is.
The brackets < and >match the opening and closing characters of an HTML tag.
The dot . matches any character except a newline character.
Adding a question mark ? after the qualifier makes it perform a non-greedy or minimal match.
For example, using the regular expression <.*?>will match only .
In its entirety, the regular expression matches all opening and closing HTML tags.
# Remove the HTML tags from a String using xml.etree.ElementTree
You can also use the xml.etree.ElementTree module to strip the HTML tags from a string.
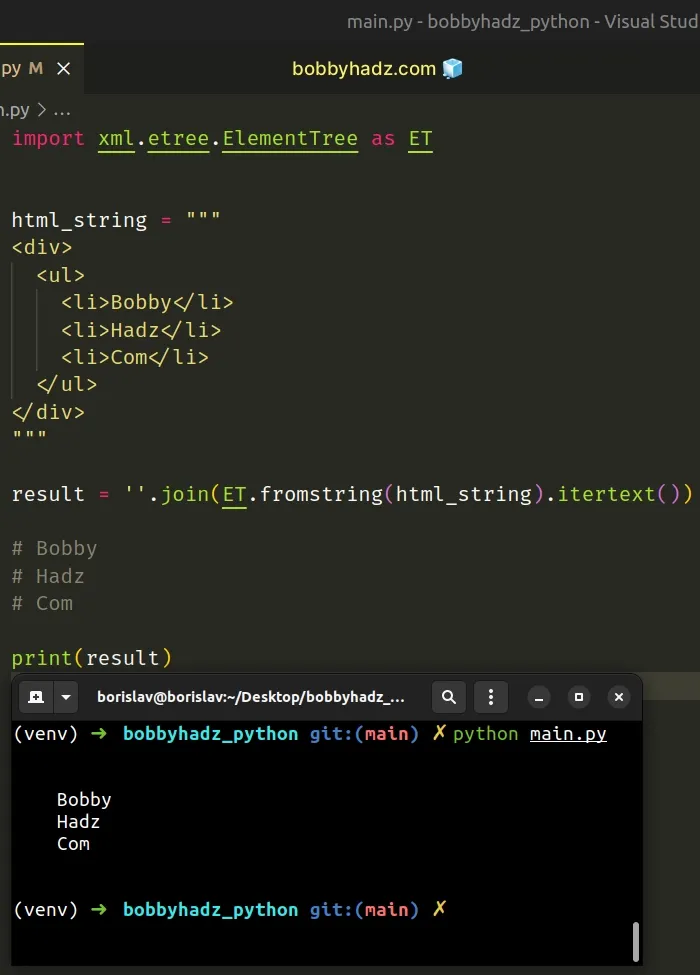
The fromstring method parses an XML section from a string constant and returns an Element instance.
The itertext method creates a text iterator that we can join with the str.join() method.
# Remove the HTML tags from a String using lxml
You can also use the lxml module to strip the HTML tags from a string.
Make sure you have the module installed by running the following command.
Copied!pip install lxml # 👇️ or pip3 pip3 install lxml
Now you can import and use the lxml module to strip the HTML tags from the string.
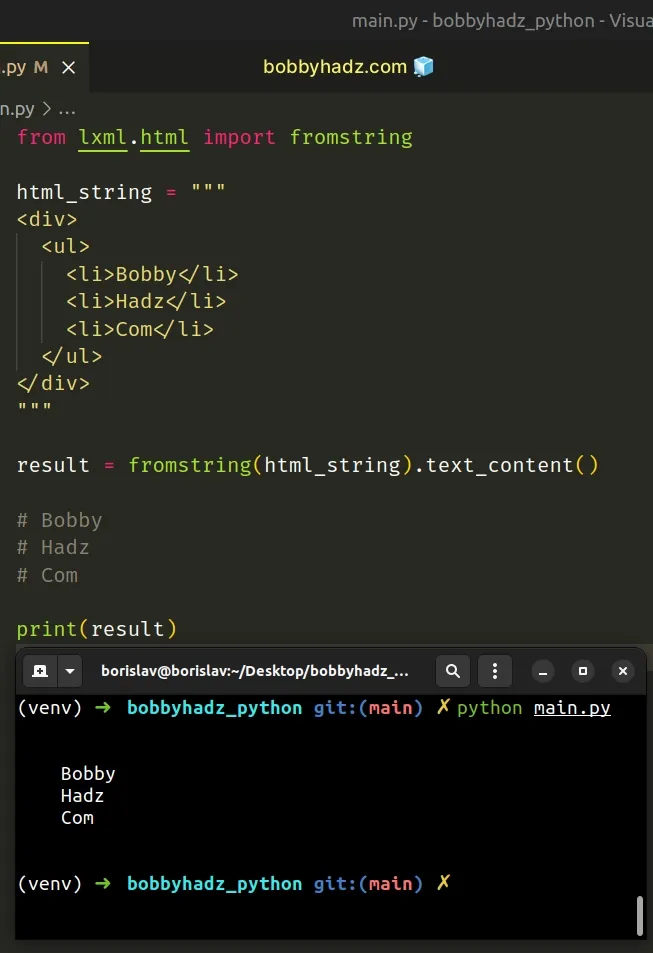
The text_content method removes all markup from a string.
# Remove the HTML tags from a String using BeautifulSoup
You can also use the BeautifulSoup4 module to remove the HTML tags from a string.
Make sure you have the module installed to be able to run the code sample.
Copied!pip install lxml pip install beautifulsoup4 # 👇️ or pip3 pip3 install lxml pip3 install beautifulsoup4
Now you can import and use the BeautifulSoup module to strip the HTML tags from the string.
The text attribute on the BeautifulSoup object returns the text content of the string, excluding the HTML tags.
# Remove the HTML tags from a String using HTMLParser in Python
This is a four-step process:
- Extend from the HTMLParser class from the html.parser module.
- Implement the handle_data method to get the data between the HTML tags.
- Store the data in a list on the class instance.
- Call the get_data() method on an instance of the class.
The remove_html_tags function takes a string and strips the HTML tags from the supplied string.
We extended from the HTMLParser class. The code snippet is very similar to the one used internally by the django module.
The HTMLParser class is used to find tags and other markup and call handler functions.
The data between the HTML tags is passed from the parser to the derived class by calling self.handle_data() .
When convert_charrefs is set to True , character references automatically get converted to the corresponding Unicode character.
If convert_charrefs is set to False , character references are passed by calling the self.handle_entityref() or self.handle_charref() methods.
The str.join method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The remove_html_tags() function takes a string that contains HTML tags and returns a new string where all opening and closing HTML tags have been removed.
The function instantiates the class and feeds the string containing the html tags to the parser.
Lastly, we call the get_data() method on the instance to join the list of strings into a single string that doesn’t contain any HTML tags.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.
Python: 5 ways to remove HTML tags from a string
This concise, example-based article will walk you through some different approaches to stripping HTML tags from a given string in Python (to get plain text).
The raw HTML string we will use in the examples to come is shown below:
html_string = """ This is a heading
Some meaningless text
Sample link Sample link 
"""
As you can see, it contains several common HTML tags like , , ,
, self-closing ones like
,
, and a sample comment. The reason we use such a long HTML string is to make sure that our methods can work well in many different scenarios. If the test HTML string is too short and simple, potential pitfalls might be overlooked.
Using lxml
lxml is a powerful tool for processing HTML and XML. It’s fast, safe, and reliable. This is an external package, so we need to install it first:
from lxml import etree html_string = """ This is a heading
Some meaningless text
Sample link Sample link
""" def remove_html_tags(text): parser = etree.HTMLParser() tree = etree.fromstring(text, parser) return etree.tostring(tree, encoding='unicode', method='text') plan_text = remove_html_tags(html_string) print(plan_text.strip()) Sling Academy This is a heading Some meaningless text Sample link Sample linkUsing Regular Expressions
You can use the re module to create a pattern that matches any text inside < and >, and then use the re.sub() method to replace them with empty strings.
import re html_string = """ This is a heading
Some meaningless text
Sample link Sample link
""" def remove_html_tags(text): clean = re.compile('<.*?>') return re.sub(clean, '', text) result = remove_html_tags(html_string) # print the result without leading and trailing white spaces print(result.strip()) The output looks exactly as what we got after using the previous method:
Sling Academy This is a heading Some meaningless text Sample link Sample linkUsing BeautifulSoup
This solution involves using the popular BeautifulSoup library, which provides convenient methods to parse and manipulate HTML.
pip install beautifulsoup4from bs4 import BeautifulSoup html_string = """ This is a heading
Some meaningless text
Sample link Sample link
""" def remove_html_tags(input): soup = BeautifulSoup(input, 'html.parser') return soup.get_text() print(remove_html_tags(html_string).strip())Still, the same plain text you got in the previous examples, but the indentation is automatically removed:
Sling Academy This is a heading Some meaningless text Sample link Sample linkUsing a for loop and if…else statements
This technique is super flexible, and you can customize it as needed. Our weapons are just a for loop, some if. else statements, and some basic string operations.
html_string = """ This is a heading
Some meaningless text
Sample link Sample link
""" def remove_html_tags(text): inside_tag = False result = '' for char in text: if char == '': inside_tag = False else: if not inside_tag: result += char return result print(remove_html_tags(html_string).strip()) Sling Academy This is a heading Some meaningless text Sample link Sample linkUsing HTMLParser
This solution makes use of the built-in html.parser module in Python for parsing HTML and extracting the text. However, it’s a little bit longer in comparison to the preceding approaches.
from html.parser import HTMLParser class HTMLTagRemover(HTMLParser): def __init__(self): super().__init__() self.result = [] def handle_data(self, data): self.result.append(data) def get_text(self): return ''.join(self.result) def remove_html_tags(text): remover = HTMLTagRemover() remover.feed(text) return remover.get_text() html_string = """ This is a heading
Some meaningless text
Sample link Sample link
""" print(remove_html_tags(html_string).strip())Sling Academy This is a heading Some meaningless text Sample link Sample linkThat’s it. Happy coding & have a nice day!
strip-tags
To run against just specific areas identified by CSS selectors:
strip-tags -i input.html > output.txt
This can be called with multiple selectors:
cat input.html strip-tags > output.txt
To return just the first element on the page that matches one of the selectors, use —first :
cat input.html strip-tags .content --first > output.txt
To remove content contained by specific selectors — e.g. the section of a page, use -r or —remove :
cat input.html strip-tags -r nav > output.txt
To minify whitespace — reducing multiple space and tab characters to a single space, and multiple newlines and spaces to a maximum of two newlines — add -m or —minify :
cat input.html strip-tags -m > output.txt
You can also run this command using python -m like this:
Keeping the markup for specified tags
When passing content to a language model, it can sometimes be useful to leave in a subset of HTML tags —
This is the heading
for example — to provide extra hints to the model.
The -t/—keep-tag option can be passed multiple times to specify tags that should be kept.
This example looks at the section of https://datasette.io/ and keeps the tags around the list items and elements:
curl -s https://datasette.io/ | strip-tags header -t h1 -t li All attributes will be removed from the tags, except for the id= and class= attribute since those may provide further useful hints to the language model.
The href attribute on links, the alt attribute on images and the name and value attributes on meta tags are kept as well.
You can also specify a bundle of tags. For example, strip-tags -t hs will keep the tag markup for all levels of headings.
The following bundles can be used:
As a Python library
You can use strip-tags from Python code too. The function signature looks like this:
This has tags
And whitespace toostrip-tags —help
Usage: strip-tags [OPTIONS] [SELECTORS]. Strip tags from HTML, optionally from areas identified by CSS selectors Example usage: cat input.html | strip-tags > output.txt To run against just specific areas identified by CSS selectors: cat input.html | strip-tags .entry .footer > output.txt Options: --version Show the version and exit. -r, --remove TEXT Remove content in these selectors -i, --input FILENAME Input file -m, --minify Minify whitespace -t, --keep-tag TEXT Keep these --all-attrs Include all attributes on kept tags --first First element matching the selectors --help Show this message and exit. Development
To contribute to this tool, first checkout the code. Then create a new virtual environment:
strip-tags python -m venv venv venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e To run the tests: