- Get HTML Source of WebElement in Selenium WebDriver using Python.
- Syntax
- Syntax
- Example
- How to get HTML source of a Web Element in Selenium WebDriver
- What is HTML Source?
- What is a Web Element?
- How to retrieve the HTML source of a web element using Python?
- How to retrieve the HTML source of a web element using Selenium?
- Method 1
- Method 2
- How To Get Page Source In Selenium Using Python?
- What Is An HTML Page Source?
- What Is An HTML Web Element?
- How To Get Page Source In Selenium WebDriver Using Python?
- Get HTML Page source Using driver.page_source
Get HTML Source of WebElement in Selenium WebDriver using Python.
We can get html source of a webelement with Selenium webdriver.We can get the innerHTML attribute to get the source of the web element.
The innerHTML is an attribute of a webelement which is equal to the text that is present between the starting and ending tag. The get_attribute method is used for this and innerHTML is passed as an argument to the method.
Syntax
s = element.get_attribute('innerHTML') We can obtain the html source of the webelement with the help of Javascript Executor. We shall utilize the execute_script method and pass arguments index.innerHTML and webelement whose html source is to be retrieved to the method.
Syntax
s = driver.find_element_by_id("txt-search") driver.execute_script("return arguments[0].innerHTML;",s) Let us see the below html code of an element. The innerHTML of the element shall be − You are browsing the best resource for Online Education.
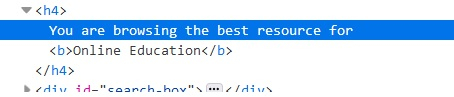
Example
Code Implementation with get_attribute.
from selenium import webdriver driver = webdriver.Chrome(executable_path="C:\chromedriver.exe" # implicit wait applied driver.implicitly_wait(0.5) driver.get("https://www.tutorialspoint.com/index.htm") # to identify element and obtain innerHTML with get_attribute l = driver.find_element_by_css_selector("h4") print("HTML code of element: " + l.get_attribute('innerHTML')) Code Implementation with Javascript Executor.
from selenium import webdriver driver = webdriver.Chrome(executable_path="C:\chromedriver.exe" # implicit wait applied driver.implicitly_wait(0.5) driver.get("https://www.tutorialspoint.com/index.htm") # to identify element and obtain innerHTML with execute_script l = driver.find_element_by_css_selector("h4") h= driver.execute_script("return arguments[0].innerHTML;",l) print("HTML code of element: " + h) How to get HTML source of a Web Element in Selenium WebDriver
Before exploring how to get page source in Selenium , let’s take a quick moment to understand the key terms, such as HTML Source and Web element, which will be addressed in the following sections with code snippets and two methods.
What is HTML Source?
This refers to the HTML code underlying a certain web element on a web page. Since it is the foundation of any web page, testing HTML code in a normal browser and cross-browser testing scenarios becomes vital. Although, do not confuse this with the HTML tag.
What is a Web Element?
Anything that appears on a web page is a web element. Most obviously, this refers to text boxes, checkboxes, buttons, or any other fields that display or require data from the user. Web elements can also mean the tags within the web page’s HTML code. Essentially, interaction with the HTML code is interaction with a web element. Such elements usually have unique identifiers, such as ID, name, or unique classes.
For example, to highlight text on a page, one would have to interact with the “body”, a “div” and perhaps even a “p” element.
It is common for web elements to occur within other web elements. One can use mechanisms such as XPath in Selenium or CSS Selectors to locate them. You find element by XPath in Selenium.
How to retrieve the HTML source of a web element using Python?
To start with, download the Python bindings for Selenium WebDriver.
- One can do this from the PyPI page for the Selenium package.
- Alternatively, one can use pip to install the Selenium package. Python 3.6 provides the pip in the standard library. Install Selenium with pip with the following syntax:
It is also possible to use virtualenv to create isolated Python environments. Python 3.6 offers pyvenv which is quite similar to virtualenv.
Notes for Windows users
- Install Python 3.6 with the MSI provided in the python.org download page.
- Start a command prompt using the cmd.exe program. Then run the pip command with the syntax given below to install Selenium.
C:Python35Scriptspip.exe install selenium
Now, here’s how to get a web element:
elem = wd.find_element_by_css_selector('#my-id') Here’s how to get the HTML source for the full page:
How to retrieve the HTML source of a web element using Selenium?
Method 1
Read the innerHTML attribute to get the source of the element’s content. innerHTML is a property of a DOM element whose value is the HTML between the opening tag and ending tag.
For example, the innerHTML property in the code below carries the value “text”
This property can use to retrieve or dynamically insert content on a web page. However, if it is used to do anything beyond inserting simple text, some differences may occur in how it operates across different browsers. It is a good practice to test your website across browsers and devices, try now.
innerHTML was first implemented in Internet Explorer 5. It has been part of the standard and has existed as a property of HTMLElement and HTMLDocument since HTML 5.
Implement the innerHTML attribute to get the HTML source in Selenium with the following syntax:
element.get_attribute('innerHTML') Java: elem.getAttribute("innerHTML"); element.GetAttribute("innerHTML"); element.attribute("innerHTML") element.getAttribute('innerHTML'); $elem.getAttribute('innerHTML'); Method 2
Read the outerHTML to get the source with the current element. outerHTML is an element property whose value is the HTML between the opening and closing tags and the HTML of the selected element itself.
For example, the code’s outerHTML property carries a value that contains div and span inside that.
Implement the outerHTML attribute to get the HTML source in Selenium with the following syntax:
ele.get_atrribute("outerHTML") Automated selenium testing becomes more efficient and result-driven by implementing the code detailed above. Detect, with ease, the HTML source of designated web elements so that they may be examined for anomalies. Needless to say, identifying anomalies quickly leads to equally quick debugging, thus pushing out websites that provide optimal user experiences in minimal timelines.
How To Get Page Source In Selenium Using Python?

This article is a part of our Content Hub. For more in-depth resources, check out our content hub on Selenium Python Tutorial.
Retrieving the page source of a website under scrutiny is a day-to-day task for most test automation engineers. Analysis of the page source helps eliminate bugs identified during regular website UI testing, functional testing, or security testing drills. In an extensively complex application testing process, automation test scripts can be written in a way that if errors are detected in the program, then it automatically.
- saves that particular page’s source code.
- notifies the person responsible for the URL of the page.
- extracts the HTML source of a specific element or code-block and delegates it to responsible authorities if the error has occurred in one particular independent HTML WebElement or code block.
This is an easy way to trace, fix logical and syntactical errors in the front-end code. In this article, we first understand the terminologies involved and then explore how to get the page source in Selenium WebDriver using Python.
TABLE OF CONTENT

What Is An HTML Page Source?
In non-technical terminology, it’s a set of instructions for browsers to display info on the screen in an aesthetic fashion. Browsers interpret these instructions in their own ways to create browser screens for the client-side. These are usually written using HyperText Markup Language (HTML), Cascading Style Sheets (CSS) & Javascript.
This entire set of HTML instructions that make a web page is called page source or HTML source, or simply source code. Website source code is a collection of source code from individual web pages.
Here’s an example of a Source Code for a basic page with a title, form, image & a submit button.
What Is An HTML Web Element?
The easiest way to describe an HTML web element would be, “any HTML tag that constitutes the HTML page source code is a web Element.” It could be an HTML code block, an independent HTML tag like , a media object on the web page – image, audio, video, a JS function or even a JSON object wrapped within tags.
In the above example – is an HTML web element, so is and the children of body tags are HTML web elements too i.e., , etc.
How To Get Page Source In Selenium WebDriver Using Python?
Selenium WebDriver is a robust automation testing tool and provides automation test engineers with a diverse set of ready-to-use APIs. And to make Selenium WebDriver get page source, Selenium Python bindings provide us with a driver function called page_source to get the HTML source of the currently active URL in the browser.
Alternatively, we can also use the “GET” function of Python’s request library to load the page source. Another way is to execute javascript using the driver function execute_script and make Selenium WebDriver get page source in Python. A not-recommended way of getting page source is using XPath in tandem with “view-source:” URL. Let’s explore examples for these four ways of how to get page source in Selenium WebDriver using Python –
We’ll be using a sample small web page hosted on GitHub for all four examples. This page was created to demonstrate drag and drop testing in Selenium Python using LambdaTest.
Get HTML Page source Using driver.page_source
We’ll fetch “pynishant.github.io” in the ChromeDriver and save its content to a file named “page_source.html.” This filename could be anything of your choice. Next, we read the file’s content and print it on the terminal before closing the driver.