- How to remove any URL within a string in Python
- Answer by Lukas Barrera
- Answer by Laurel Hickman
- Answer by Beatrice Dunlap
- Answer by Misael Estrada
- Answer by Aubrielle Evans
- Remove url in python
- # Remove URLs from Text in Python
- # Making the regex more specific
- # Remove URLs from Text using re.findall()
- # Additional Resources
- How To Remove URLs From Text In Python
- Remove URLs from Text in Python
- Use the findall() function
- Use the re.sub function
- Use module urllib
- Summary
How to remove any URL within a string in Python
In order to remove any URL within a string in Python, you can use this RegEx function :, Shift to remote work prompted more cybersecurity questions than any breach , Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers , Why were the Apollo 12 astronauts tasked with bringing back part of the Surveyor 3 probe?
Python script:
import re text = re.sub(r'^https?:\/\/.*[\r\n]*', '', text, flags=re.MULTILINE) text1 text2 text3 text4 text5 text6 Answer by Lukas Barrera
re.sub(r'http\S+', '', stringliteral)Answer by Laurel Hickman
In this article, we will need to accept a string and we need to check if the string contains any URL in it. If the URL is present in the string, we will say URL’s been found or not and print the respective URL present in the string. We will use the concept of Regular Expression of Python to solve the problem.,Check if a string can be obtained by rotating another string 2 places,A Program to check if strings are rotations of each other or not,Check if strings are rotations of each other or not | Set 2
Input : string = 'My Profile: https://auth.geeksforgeeks.org/user/Chinmoy%20Lenka/articles in the portal of http://www.geeksforgeeks.org/' Output : URLs : ['https://auth.geeksforgeeks.org/user/Chinmoy%20Lenka/articles', 'http://www.geeksforgeeks.org/'] Input : string = 'I am a blogger at https://geeksforgeeks.org' Output : URL : ['https://geeksforgeeks.org'] Urls: ['https://auth.geeksforgeeks.org/user/Chinmoy%20Lenka/articles', 'http://www.geeksforgeeks.org/'] Answer by Beatrice Dunlap
In NLP we must preprocess our text according to the task at hand. In some cases, we need to remove all punctuation in a string but during a task like sentiment analysis, it is important to hold onto some punctuations like ‘!’ which express strong sentiment.,If we want to remove all punctuation we can simply use [^a-zA-Z0–9] which matches everything except alphanumeric characters.,Your home for data science. A Medium publication sharing concepts, ideas and codes.,Note how only the words at the beginning and end were removed and their other occurrences remained unchanged.
Befo r e we get started let’s just get some basics straight. I will only be explaining terms that are later used in this article so that nothing is too overwhelming.
\w represents any alphanumeric characters (including underscore)\d represents any digit. represents ANY character (do not confuse it with a period )abc literally matches characters abc in a string[abc] matches either a or b or c (characters within the brackets)? after a character indicates that the character is optional* after a character indicates it can be repeated 0 or more times+ after a character indicates it can be repeated 1 or more times\ is used to escape special characters (we'll use this alot!)Answer by Misael Estrada
Matches only at the start of the string. When not in MULTILINE mode, \A and ^ are effectively the same. In MULTILINE mode, they’re different: \A still matches only at the beginning of the string, but ^ may match at any location inside the string that follows a newline character.,Matches at the beginning of lines. Unless the MULTILINE flag has been set, this will only match at the beginning of the string. In MULTILINE mode, this also matches immediately after each newline within the string.,The engine tries to match b, but the current position is at the end of the string, so it fails.,Matches at the end of a line, which is defined as either the end of the string, or any location followed by a newline character.
Answer by Aubrielle Evans
I will show you two different methods to solve this problem.,replace() method is used to replace a substring in a string with a different substring. We can use this method to remove https from a url as like below :,This post will show you how to remove https from a url in python. You can use the same method to remove any substring from a string. For example, if our url is https://www.google.com, it will convert it to www.google.com.,regex or Regular Expression is another way to replace a substring. Regex is used for complex tasks than this, but you can use it to remove https:// from a url as like below :
given_url = 'https://www.google.com' print(given_url.replace('https://',''))Remove url in python
Last updated: Feb 20, 2023
Reading time · 3 min

# Remove URLs from Text in Python
Use the re.sub() method to remove URLs from text. The re.sub() method will remove any URLs from the string by replacing them with empty strings.
Copied!import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
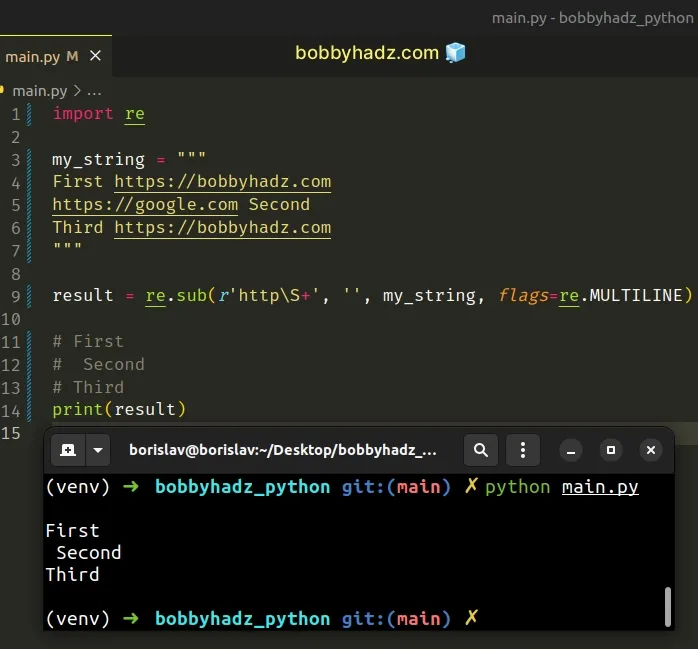
We used the re.sub() method to remove all URLs from a string.
The re.sub method returns a new string that is obtained by replacing the occurrences of the pattern with the provided replacement.
Copied!import re my_str = '1apple, 2apple, 3banana' result = re.sub(r'8', '_', my_str) print(result) # 👉️ _apple, _apple, _banana
If the pattern isn’t found, the string is returned as is.
We used an empty string for the replacement because we want to remove all URLs from the string.
Copied!import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
The first argument we passed to the re.sub() method is a regular expression.
The http characters in the regex match the literal characters.
\S matches any character that is not a whitespace character. Notice that the S is uppercase.
The plus + matches the preceding character (any non-whitespace character) 1 or more times.
In its entirety, the regular expression matches substrings starting with http follows by 1 or more non-whitespace characters.
# Making the regex more specific
If you worry about matching strings in the form of http-something , update your regular expression to r’https?://\S+’ .
Copied!import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'https?://\S+', '', my_string) # First # Second # Third print(result)
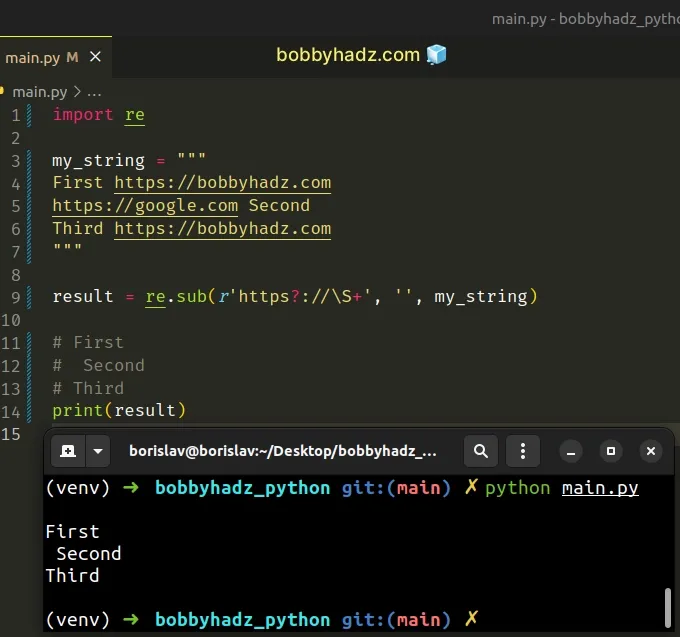
The question mark ? causes the regular expression to match 0 or 1 repetitions of the preceding character.
For example, https? will match either https or http .
We then have the colon and two forward slashes :// to complete the protocol.
In its entirety, the regular expression matches substrings starting with http:// or https:// followed by 1 or more non-whitespace characters.
If you ever need help reading or writing a regular expression, consult the regular expression syntax subheading in the official docs.
The page contains a list of all of the special characters with many useful examples.
# Remove URLs from Text using re.findall()
You can also use the re.findall() method to remove the URLs from a string.
Copied!import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ new_string = my_string matches = re.findall(r'http\S+', my_string) print(matches) for match in matches: new_string = new_string.replace(match, '') # First # Second # Third print(new_string)
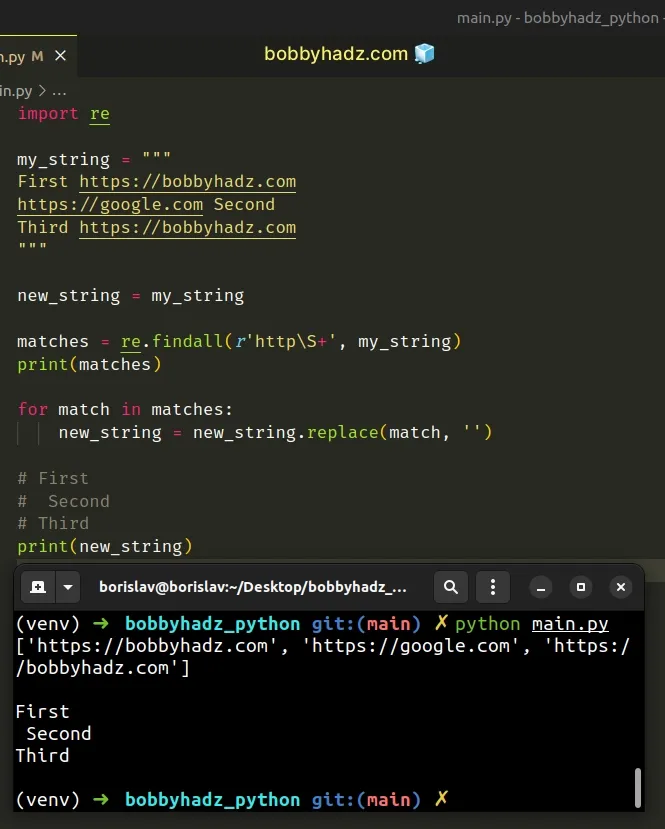
The re.findall method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
We used a for loop to iterate over the list of matches.
On each iteration, we use the str.replace method to remove the current match from the URL.
You would use this approach if you want to keep some of the URLs in the text based on a condition.
Copied!import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ new_string = my_string matches = re.findall(r'http\S+', my_string) print(matches) for match in matches: if 'google' not in match: new_string = new_string.replace(match, '') # First # https://google.com Second # Third print(new_string)
On each iteration of the for loop, we check if the current match doesn’t contain the string google .
If the condition is met, the URL is removed.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove punctuation from a List of strings in Python
- How to remove Quotes from a List of Strings in Python
- Remove characters matching Regex from a String in Python
- Remove special characters except Space from String in Python
- Remove square brackets from a List or a String in Python
- Remove the Prefix or Suffix from a String in Python
- How to Remove the Tabs from a String in Python
- Remove Newline characters from a List or a String in Python
- Remove non-alphanumeric characters from a Python string
- Remove non-ASCII characters from a string in Python
- Remove the non utf-8 characters from a String in Python
- How to Remove \xa0 from a String in Python
- How to Remove \ufeff from a String in Python
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.
How To Remove URLs From Text In Python

To remove URLs from Text in Python, we can use use the findall() or re.sub() functions. Follow the article to understand better.
Remove URLs from Text in Python
We have a text string and a URL inside the string.
myString = ''' Text1 https://google.com '''To remove URLs from Text, do as the following guide:
Use the findall() function
You can use the findall() function to search for URLs and then delete those URLs with the replace() function. Note that the findall() function is in the re module, so you need to import re before calling findall().
- regex: regular expression to search for digits.
- string: string you want the regular expression to search for.
The findall() function returns a list containing the pattern matches in the string. If not found, the function returns an empty list.
- Import re module.
- Create a string with the URL.
- Use findall() function to find URL in the string.
- Use the replace function to replace that URL with a space. So that URL has been removed.
import re # String containing URL myString = "This is a string with a URL https://learnshareit.com/" # Use findall() function to search for URL search = re.findall('http://\S+|https://\S+', myString) for i in search: # Remove that URL with replace() function text = myString.replace(i, '') print('String after removing URL:', text) String after removing URL: This is a string with a URLUse the re.sub function
Module ‘re’ has many methods and functions to work with RegEx, but one of the essential methods is ‘re.sub’.
The Re.sub() method will replace all pattern matches in the string with something else passed in and return the modified string.
re.sub(pattern, replace, string, count)
- pattern: is RegEx.
- replace: is the replacement for the resulting string that matches the pattern.
- string: is the string to match.
- count: is the number of replacements. Python will treat this value as 0, match, and replace all qualified strings if left blank.
- Import re module
- Create a string with a URL
- Use the re.sub() function to remove those URLs.
import re # String of URL myString = ''' Text1 https://google.com ''' # Use the re.sub function to remove URL from the string text = re.sub(r"\S*https?:\S*", "", myString) print('String after removing URL:', text) String after removing URL: Text1Use module urllib
You can use the urllib module with the urllib.urlparse class has a scheme attribute combined with the split() function to remove the URL in the string.
- In the urllib module, there is a urllib.urlparse class that helps with URL parsing.
- Use the scheme attribute to check if the string matches the URL structure.
- To remove the URL with this: Use the split() function to split the string into a list, then use the scheme function to check if each string in the list matches a URL.
- Finally, use the join() function to join the remaining elements.
from urllib.parse import urlparse # String containing URL myString = "This is a text with a URL https://learnshareit.com/" # Search and delete URL search = [l for l in myString.split() if not urlparse(l).scheme] # Merge string after removing URL text = ' '.join(search) print('String after removing URL:', text) String after removing URL: This is a text with a URLSummary
If you have any questions about how to remove URLs from Text in Python, leave a comment below. I will answer your questions. Thank you for reading!
Maybe you are interested:
My name is Jason Wilson, you can call me Jason. My major is information technology, and I am proficient in C++, Python, and Java. I hope my writings are useful to you while you study programming languages.
Name of the university: HHAU
Major: IT
Programming Languages: C++, Python, Java