- The Perfect URL Regular Expression
- PHP (use with preg_match)
- PHP (with validate filter)
- Python
- Javascript
- HTML5
- Perl
- Ruby
- Go (use the govalidator IsURL())
- Objective-C
- Swift
- Swift (use canOpenURL)
- Java
- VB.NET
- C#
- MySQL
- Bonus: What does the following regex do?
- Regex Cheat Sheet
- Modifiers:
- Brackets:
- Metacharacters
- Quantifiers
- URL RegEx Pattern – How to Write a Regular Expression for a URL
- What We’ll Cover
- What is a URL?
- How to Write a Regular Expression for a URL
- Testing the RegEx with JavaScript
- Conclusion
- The Perfect URL Regular Expression
- PHP (use with preg_match)
- PHP (with validate filter)
- Python
- Javascript
- HTML5
- Perl
- Ruby
- Go (use the govalidator IsURL())
- Objective-C
- Swift
- Swift (use canOpenURL)
- Java
- VB.NET
- C#
- MySQL
- Bonus: What does the following regex do?
- Regex Cheat Sheet
- Modifiers:
- Brackets:
- Metacharacters
- Quantifiers
- JavaScript | Регулярное выражение для извлечения HTML-ссылок из строки
- Что мы считаем адресом в HTML-ссылке из строки?
- Нюансы в решении задачи на извлечение HTML-ссылок
- Получение всех HTML-ссылок из строки
- Получение всех значений HREF из HTML-ссылок из строки
The Perfect URL Regular Expression
Simply copy and paste the URL regex below for the language of your choice.
PHP (use with preg_match)
%^(?:(?:https?|ftp)://)(?:\S+(. \S*)?@|\d(?:\.\d)|(?:(?:[a-z\d\x-\x]+-?)*[a-z\d\x-\x]+)(?:\.(?:[a-z\d\x-\x]+-?)*[a-z\d\x-\x]+)*(?:\.[a-z\x-\x]))(. \d+)?(?:[^\s]*)?$%iu
PHP (with validate filter)
if (filter_var($url, FILTER_VALIDATE_URL) !== false).
Python
Javascript
HTML5
Below is the regex used in type=”url” from RFC3986:
Perl
^(((ht|f)tp(s?))\://)?(www.|[a-zA-Z].)[a-zA-Z0-9\-\.]+\.(com|edu|gov|mil|net|org|biz|info|name|museum|us|ca|uk)(\:1+)*(/($|[a-zA-Z0-9\.\,\;\?\'\\\+&%\$#\=~_\-]+))*$
Ruby
/\A(?:(?:https?|ftp):\/\/)(?:\S+(. \S*)?@)?(?:(?!10(?:\.\d))(?!127(?:\.\d))(?!169\.254(?:\.\d))(?!192\.168(?:\.\d))(?!172\.(?:19|2\d|31)(?:\.\d))(?:4\d?|1\d\d|2[01]\d|223)(?:\.(?:1?\d|22\d|252))(?:\.(?:6\d?|1\d\d|21\d|253))|(?:(?:[a-z\u00a1-\uffff0-9]+-?)*[a-z\u00a1-\uffff0-9]+)(?:\.(?:[a-z\u00a1-\uffff0-9]+-?)*[a-z\u00a1-\uffff0-9]+)*(?:\.(?:[a-z\u00a1-\uffff])))(. \d)?(?:\/[^\s]*)?\z/i
Go (use the govalidator IsURL())
package main import ( "fmt" "github.com/asaskevich/govalidator" ) func main() < str := "https://www.urlregex.com" validURL := govalidator.IsURL(str) fmt.Printf("%s is a valid URL : %v \n", str, validURL) > Objective-C
Swift
func canOpenURL(string: String?) -> Bool < let regEx = "((https|http)://)((\\w|-)+)(([.]|[/])((\\w|-)+))+" let predicate = NSPredicate(format:"SELF MATCHES %@", argumentArray:[regEx]) return predicate.evaluateWithObject(string) >
if canOpenURL(«https://www.urlregex.com») < print("valid url.") >else
Swift (use canOpenURL)
UIApplication.sharedApplication().canOpenURL(urlString)
Java
^(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|. ;]*[-a-zA-Z0-9+&@#/%=~_|]
VB.NET
C#
^(ht|f)tp(s?)\:\/\/[0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*(:(0-9)*)*(\/?)([a-zA-Z0-9\-\.\?\,\'\/\\\+&%\$#_]*)?$
MySQL
SELECT field FROM table WHERE field REGEXP «^(https?://|www\\.)[\.A-Za-z0-9\-]+\\.[a-zA-Z]
Bonus: What does the following regex do?
Regex Cheat Sheet
Modifiers:
Brackets:
| [abc] | Match a single character a, b, or c |
| [^abc] | Match any character except a, b, or c |
| [A-z] | Match any character from uppercase A to lowercase z |
| (ab|cd|ef) | Match either ab, cd, or ef |
| (…) | Capture anything enclosed |
Metacharacters
| ^ | Start of line |
| $ | End of line |
| . | Match any character |
| \w | Match a word chracter |
| \W | Match a non-word character |
| \d | Match a digit |
| \D | Match any non-digit character |
| \s | Match a whitespace character |
| \S | Match a non-whitespace character |
| \b | Match character at the beginning or end of a word |
| \B | Match a character not at beginning or end of a word |
| \0 | Match a NUL character |
| \t | Match a tab character |
| \xxx | Match a character specified by octal number xxx |
| \xdd | Match a character specified by hexadecimal number dd |
| \uxxxx | Match a Unicode character specified by hexadecimal number xxxx |
Quantifiers
| n+ | Match at least one n |
| n* | Match zero or more n’s |
| n? | Match zero or one n |
| n | Match sequence of X n’s |
| n | Match sequence of X to Y n’s |
| n | Match sequence of X or more n’s |
URL RegEx Pattern – How to Write a Regular Expression for a URL

Kolade Chris

Regular expressions provide a powerful and flexible way to define patterns and match specific strings, be it usernames, passwords, phone numbers, or even URLs.
In this article, I’ll show you the fundamentals of crafting a regular expression for URLs. Whether you need to validate user input, extract components from URLs, or perform any other URL-related tasks, understanding how to construct a regex for URLs can greatly enhance URL validation in your applications.
First, let me show you what a URL is.
What We’ll Cover
What is a URL?
A URL, short for Uniform Resource Locator, is a string that identifies the location of a resource on the web. It typically consists of various components, including:
- the protocol – for instance, HTTP or HTTPS
- domain name – for example, freecodecamp.org
- subdomain – for example, Chinese.freecodecamp.org
- port number – 3000, 5000, 4000, and more
- path – for example, freecodecamp.org/news
- query parameters – for example, https://example.com/search?q=apple&category=fruits
How to Write a Regular Expression for a URL
A URL can be a base URL (without a subdomain, path, or query param). It can also contain a subdomain, path, or other components. Due to this, you have to tailor your regular expression to the way you’re expecting the URL.
If the users are typing in a base URL, you have to tailor your regex fir that, and if you’re expecting a URL that has a subdomain or path, you have to tailor your regex that way. If you like, you can also write a complex regex that can accept a URL in any form it can come. It is not impossible.
Here’s a regex pattern that matches a base URL of any domain extension:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9](\.[a-zA-Z0-9])(\.[a-zA-Z0-9])? This would match domains like https://www.freecodecamp.org , http://www.freecodecamp.org/ , freeCodeCamp.org , google.co.uk , facebook.net , google.com.ng , google.com.in , and many other base URLs.
The pattern below matches any URL with a path:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9](\.[a-zA-Z0-9])(\.[a-zA-Z0-9])?\/[a-zA-Z0-9]
This include URLs like https://www.freecodecamp.org/news ,
http://www.freecodecamp.org/ukrainian , and others
If you want to match a URL with a subdomain, the pattern below can do it for you:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]\.[a-zA-Z0-9]\.[a-zA-Z0-9](\.[a-zA-Z0-9])? This would match subdomains like https://www.chinese.freecodecamp.org ,
chinese.freecodecamp.org , https://chinese.freecodecamp.org , and others.
If you want a regex that matches any URL that is base, has a subdomain, or a path, you can combine all the patterns I’ve shown you like this:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z](\.[a-zA-Z])(\.[a-zA-Z])?\/[a-zA-Z0-9]|((https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z](\.[a-zA-Z])(\.[a-zA-Z])?)|(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]\.[a-zA-Z0-9]\.[a-zA-Z0-9](\.[a-zA-Z0-9])? 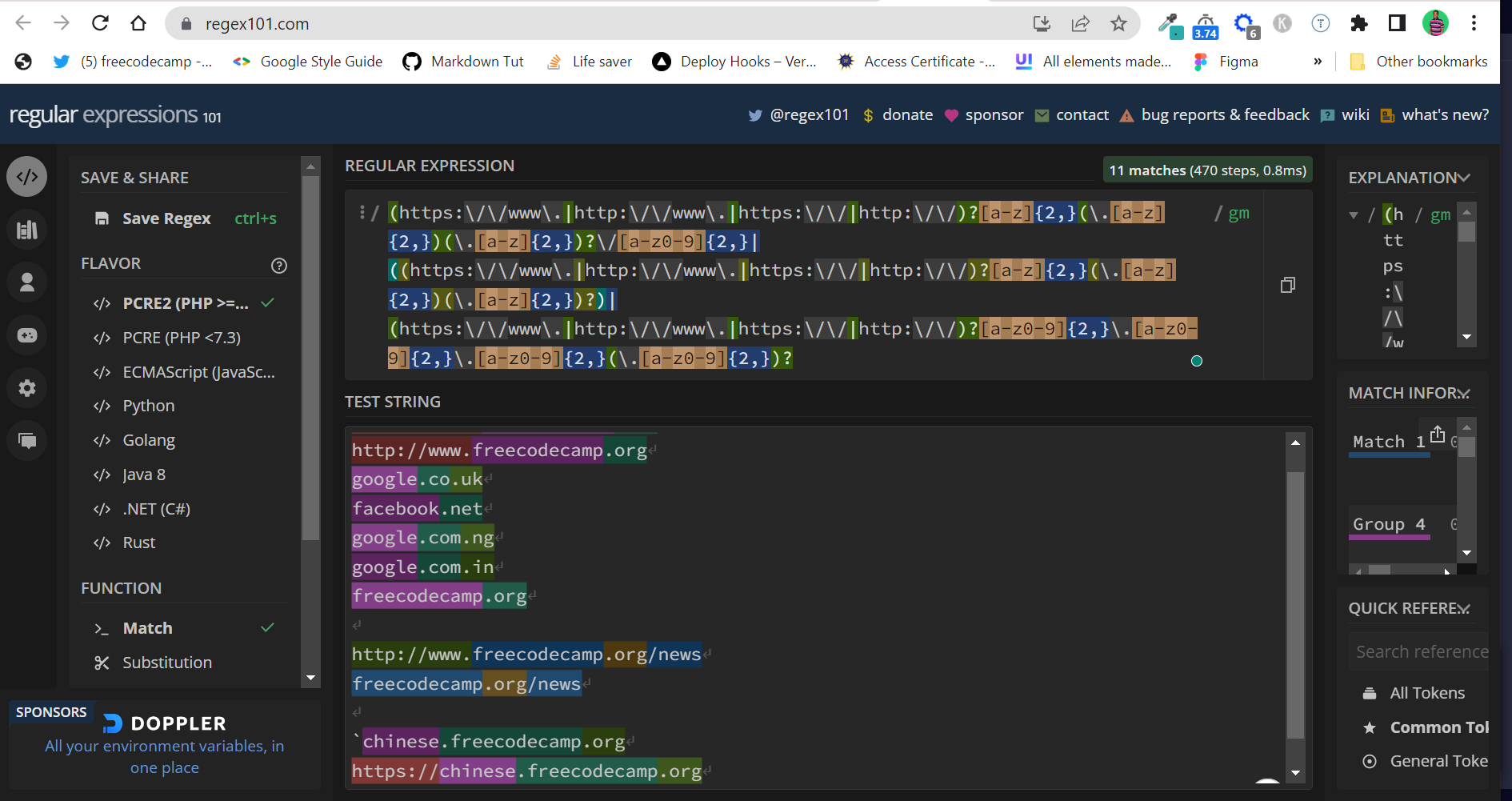
Not the prettiest way to do things, but it works:
Testing the RegEx with JavaScript
On testing the regex using the test() method of JavaScript RegEx, I got true :
const pattern = /(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z](\.[a-zA-Z])(\.[a-zA-Z])?\/[a-zA-Z0-9]|((https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z](\.[a-zA-Z])(\.[a-zA-Z])?)|(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]\.[a-zA-Z0-9]\.[a-zA-Z0-9](\.[a-zA-Z0-9])?/g; const urls = `https://www.freecodecamp.org http://www.freecodecamp.org google.co.uk facebook.net google.com.ng google.com.in freecodecamp.org yoruba.freecodecamp.org freecodecamp.org/yoruba http://www.freecodecamp.org/news freecodecamp.org/news chinese.freecodecamp.org https://chinese.freecodecamp.org`; console.log(pattern.test(urls)); //true; 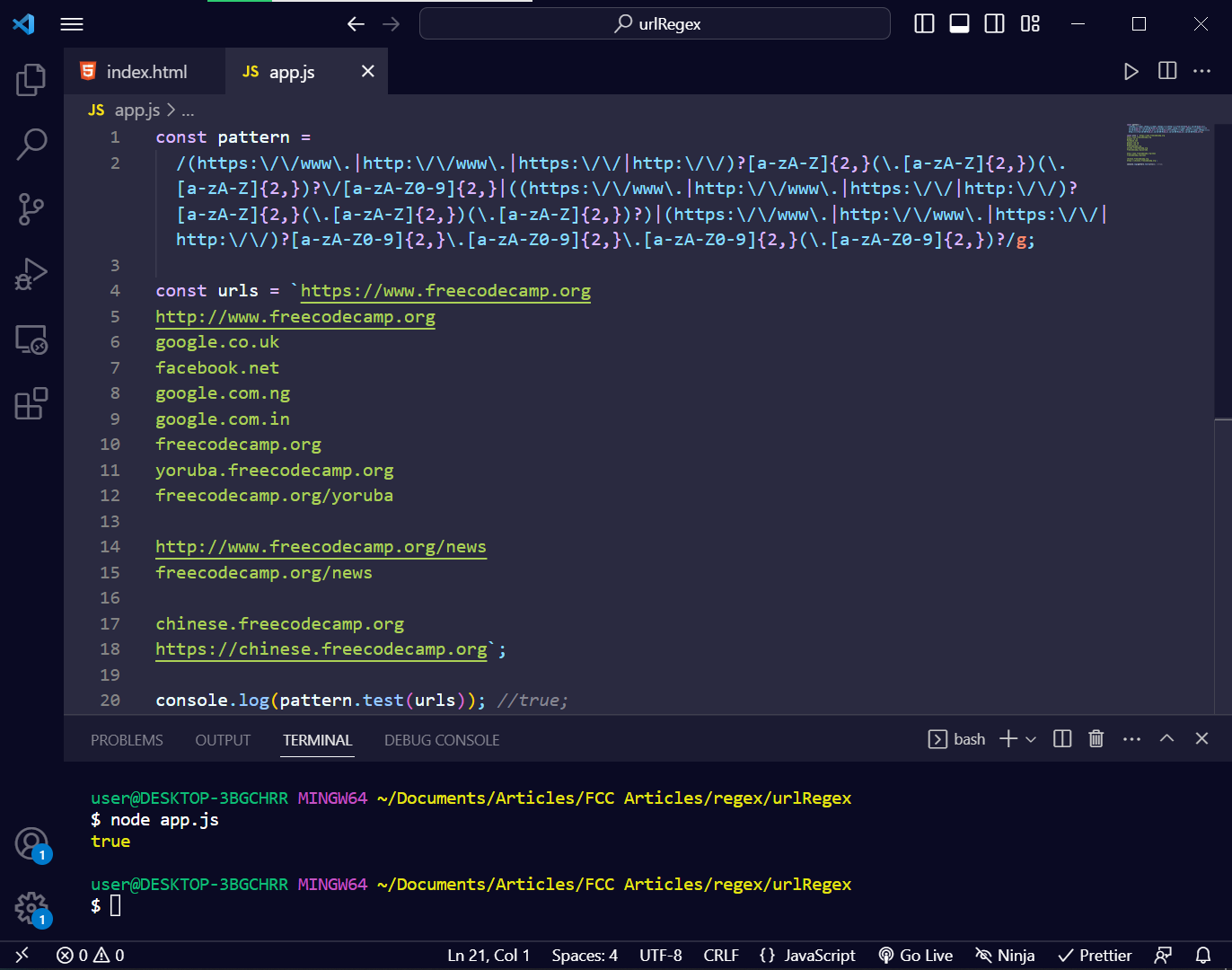
Conclusion
The regular expression patterns for matching a URL depend on your specific need – since URLs can be in various forms. So, while writing the patterns for the URL, you have to write them to suit the way you expect the URL.
Writing a regex that matches all kinds of URLs works, but it’s not the best way to because it’s very hard to read and debug.
Kolade Chris
Web developer and technical writer focusing on frontend technologies. I also dabble in a lot of other technologies.
If you read this far, tweet to the author to show them you care. Tweet a thanks
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
freeCodeCamp is a donor-supported tax-exempt 501(c)(3) charity organization (United States Federal Tax Identification Number: 82-0779546)
Our mission: to help people learn to code for free. We accomplish this by creating thousands of videos, articles, and interactive coding lessons — all freely available to the public. We also have thousands of freeCodeCamp study groups around the world.
Donations to freeCodeCamp go toward our education initiatives, and help pay for servers, services, and staff.
The Perfect URL Regular Expression
Simply copy and paste the URL regex below for the language of your choice.
PHP (use with preg_match)
%^(?:(?:https?|ftp)://)(?:\S+(. \S*)?@|\d(?:\.\d)|(?:(?:[a-z\d\x-\x]+-?)*[a-z\d\x-\x]+)(?:\.(?:[a-z\d\x-\x]+-?)*[a-z\d\x-\x]+)*(?:\.[a-z\x-\x]))(. \d+)?(?:[^\s]*)?$%iu
PHP (with validate filter)
if (filter_var($url, FILTER_VALIDATE_URL) !== false).
Python
Javascript
HTML5
Below is the regex used in type=”url” from RFC3986:
Perl
^(((ht|f)tp(s?))\://)?(www.|[a-zA-Z].)[a-zA-Z0-9\-\.]+\.(com|edu|gov|mil|net|org|biz|info|name|museum|us|ca|uk)(\:9+)*(/($|[a-zA-Z0-9\.\,\;\?\'\\\+&%\$#\=~_\-]+))*$
Ruby
/\A(?:(?:https?|ftp):\/\/)(?:\S+(. \S*)?@)?(?:(?!10(?:\.\d))(?!127(?:\.\d))(?!169\.254(?:\.\d))(?!192\.168(?:\.\d))(?!172\.(?:16|2\d|31)(?:\.\d))(?:4\d?|1\d\d|2[01]\d|221)(?:\.(?:1?\d|21\d|251))(?:\.(?:8\d?|1\d\d|24\d|253))|(?:(?:[a-z\u00a1-\uffff0-9]+-?)*[a-z\u00a1-\uffff0-9]+)(?:\.(?:[a-z\u00a1-\uffff0-9]+-?)*[a-z\u00a1-\uffff0-9]+)*(?:\.(?:[a-z\u00a1-\uffff])))(. \d)?(?:\/[^\s]*)?\z/i
Go (use the govalidator IsURL())
package main import ( "fmt" "github.com/asaskevich/govalidator" ) func main() < str := "https://www.urlregex.com" validURL := govalidator.IsURL(str) fmt.Printf("%s is a valid URL : %v \n", str, validURL) > Objective-C
Swift
func canOpenURL(string: String?) -> Bool < let regEx = "((https|http)://)((\\w|-)+)(([.]|[/])((\\w|-)+))+" let predicate = NSPredicate(format:"SELF MATCHES %@", argumentArray:[regEx]) return predicate.evaluateWithObject(string) >
if canOpenURL(«https://www.urlregex.com») < print("valid url.") >else
Swift (use canOpenURL)
UIApplication.sharedApplication().canOpenURL(urlString)
Java
^(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|. ;]*[-a-zA-Z0-9+&@#/%=~_|]
VB.NET
C#
^(ht|f)tp(s?)\:\/\/[0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*(:(0-9)*)*(\/?)([a-zA-Z0-9\-\.\?\,\'\/\\\+&%\$#_]*)?$
MySQL
SELECT field FROM table WHERE field REGEXP «^(https?://|www\\.)[\.A-Za-z0-9\-]+\\.[a-zA-Z]
Bonus: What does the following regex do?
Regex Cheat Sheet
Modifiers:
Brackets:
| [abc] | Match a single character a, b, or c |
| [^abc] | Match any character except a, b, or c |
| [A-z] | Match any character from uppercase A to lowercase z |
| (ab|cd|ef) | Match either ab, cd, or ef |
| (…) | Capture anything enclosed |
Metacharacters
| ^ | Start of line |
| $ | End of line |
| . | Match any character |
| \w | Match a word chracter |
| \W | Match a non-word character |
| \d | Match a digit |
| \D | Match any non-digit character |
| \s | Match a whitespace character |
| \S | Match a non-whitespace character |
| \b | Match character at the beginning or end of a word |
| \B | Match a character not at beginning or end of a word |
| \0 | Match a NUL character |
| \t | Match a tab character |
| \xxx | Match a character specified by octal number xxx |
| \xdd | Match a character specified by hexadecimal number dd |
| \uxxxx | Match a Unicode character specified by hexadecimal number xxxx |
Quantifiers
| n+ | Match at least one n |
| n* | Match zero or more n’s |
| n? | Match zero or one n |
| n | Match sequence of X n’s |
| n | Match sequence of X to Y n’s |
| n | Match sequence of X or more n’s |
JavaScript | Регулярное выражение для извлечения HTML-ссылок из строки
В этой публикации мы рассматриваем HTML-элементы , которые имеют парные тэги:
Мы будем считать, что сами теги и последовательность символов внутри них считается, а также между ними считается HTML-ссылкой.
Что мы считаем адресом в HTML-ссылке из строки?
Из HTML-элемента нас будет интересовать его атрибут href, который после знака равенства должен содержать двойные кавычки.
Последовательность символов между первой двойной кавычкой и второй двойной кавычкой мы будем считать адресом.
Нюансы в решении задачи на извлечение HTML-ссылок
HTML — это гибкий язык. Это значит, что строковое оформление HTML-элементов допускает существование множественного числа пробелов. Например:
Также допускаются символы переносов строк:
Эти моменты накладывают дополнительные условия в создании регулярного выражения на JavaScript.
В общем между всеми нашими символами МЕНЬШЕ-БОЛЬШЕ могут встречаться только пробелы, которые не чувствительны к парсингу HTML.
Получение всех HTML-ссылок из строки
Мы подстрахуемся под все возможные ситуации, даже если сервер отдаёт совершенно некорректную ссылку с множественными пробелами:
Массив с индексами нахождения начала сопоставления:
Только последовательность с HTML-элементом