Регулярное выражение для удаления тегов HTML
Я использую следующее регулярное выражение для удаления тегов html из строки. Он работает, за исключением того, что я оставляю закрывающий тег. Если я попытаюсь удалить: blah , он оставляет . Я вообще не знаю синтаксиса регулярного выражения и пробовал это. Может кто-то с знаниями RegEx, пожалуйста, предоставьте мне образец, который будет работать. Вот мой код:
string sPattern = @"]*>"; Regex rgx = new Regex(sPattern); Match m = rgx.Match(sSummary); string sResult = ""; if (m.Success) sResult = rgx.Replace(sSummary, "", 1); «Я использую . Регулярное выражение для удаления HTML-тегов» есть ваша проблема. Вместо этого используйте HTML-парсер.
Возможные дубликаты RegEx совпадают с открытыми тегами, за исключением автономных тегов XHTML — несмотря на заголовок, это является точной копией. Promise.
Поскольку другие люди не видят возможного варианта использования для этого, вот мое . а) работа в изолированной программной среде кода (Salesforce), где трудно, если не невозможно, включить и поддерживать стороннюю библиотеку б) только пытаясь убрать теги из тела письма для более чистого описания письма к делу (т. е. без проблем с безопасностью) c) метод stripHtmlTags () не сделал достаточной работы по удалению лишних тегов
13 ответов
Использование регулярного выражения для синтаксического анализа HTML чревато ошибками. HTML не является регулярным языком и, следовательно, не может быть на 100% корректно обработан регулярным выражением. Это всего лишь одна из многих проблем, с которыми вы столкнетесь. Лучший подход — использовать парсер HTML/XML, чтобы сделать это для вас.
Вот ссылка на сообщение в блоге, которое я написал некоторое время назад, в котором содержится подробная информация об этой проблеме.
Говоря это, вот решение, которое должно исправить эту конкретную проблему. Однако это не идеальное решение.
Джаред, это похоже на исключение, когда я пытаюсь это сделать. Кроме того, это удалит текст между тегами? По сути, я хочу удалить первые строки тегов a, p и img из строки.
Вам нужно заменить теги пробелами:
и уменьшите любые повторяющиеся пробелы в одиночные пробелы:
затем обрезать передние и конечные пробелы с помощью:
Смысл, что ваша функция удаления тега выглядит следующим образом:
function removeTags(string)< return string.replace(/<[^>]*>/g, ' ') .replace(/\s/g, ' ') .trim(); > это отличный ответ, как бы вы изменили его, если бы вы хотели удалить все теги, включая текстовое содержимое тегов? просто оставить позади текст, который не был внутри тегов?
аааа, я понял это, я придумал: function removeTags (string)
 ]+>\s+(?=<)|<[^>]+>"; inputHTML = WebUtility.HtmlDecode(inputHTML).Trim(); string noHTML = Regex.Replace(inputHTML, HTML_MARKUP_REGEX_PATTERN, string.Empty); return noHTML; >
]+>\s+(?=<)|<[^>]+>"; inputHTML = WebUtility.HtmlDecode(inputHTML).Trim(); string noHTML = Regex.Replace(inputHTML, HTML_MARKUP_REGEX_PATTERN, string.Empty); return noHTML; >
Итак, для следующего ввода:
test text
test 1
test 2
test 3
Выход будет только текстом без пробелов между тегами html или пробелом до или после html: «Тест тестового теста 1 тест 2 тест 3».
Обратите внимание, что пробелы перед test text находятся из test text html, а пробел после test 3 — из test 3
html.
Итак, парсер HTML, о котором все говорят, Html Agility Pack.
Если это чистый XHTML, вы также можете использовать System.Xml.Linq.XDocument или System.Xml.XmlDocument .
Regex.Replace(source, "<[^>]*>", string.Empty); Вы можете использовать уже существующие библиотеки, чтобы отключить теги html. Один хороший Chilkat С# Library.
Если вам нужно найти только открывающие теги, вы можете использовать следующее регулярное выражение, в котором тип тега будет записан как $ 1 (a или img), а содержимое (включая закрывающий тег, если он есть) — как $ 2:
В случае, если у вас также есть закрывающий тег, вы должны использовать следующее регулярное выражение, которое будет захватывать тип тега как $ 1 (a или img), а содержимое как $ 2:
В основном вам просто нужно использовать функцию замены в одном из приведенных выше регулярных выражений и вернуть $ 2, чтобы получить то, что вы хотели.
Краткое объяснение о запросе:
- ( ) — используется для захвата всего, что соответствует регулярному выражению в скобках. Порядок захвата составляет порядка $ 1, $ 2 и т.д.
- ?: — используется после открывающей скобки «(«, чтобы не захватывать содержимое внутри скобок.
- \1 — копирует захват номер 1, который является типом тега. Мне нужно было захватить тип тега, чтобы закрывающий тег соответствовал открывающему, а не как: .
- \s — это пробел, поэтому после открытия тега ).
- [^>]* — ищет что-либо, кроме символов внутри, что в данном случае означает > , а * означает неограниченное количество раз.
- ?! — ищет что-нибудь, кроме строки внутри, вроде как [^>] только для строки вместо одиночных символов.
Пример использования с закрывающим тегом: https://regex101.com/r/MGmzrh/1
Пример использования без закрывающего тега: https://regex101.com/r/MGmzrh/2
У Regex101 также есть объяснение тому, что я сделал 🙂
Регулярные выражения для удаления тегов
Подборка регулярных выражений для удаления HTML тегов и атрибутов.
Удаление тегов
$text = 'Текст текст
'; echo preg_replace('/\s?]*?>.*?\s?/si', ' ', $text); Результат:
По аналогии удаление тегов
, и :
echo preg_replace('/\s?]*?>.*?\s?/si', ' ', $text); echo preg_replace('/\s?]*?>.*?\s?/si', ' ', $text); echo preg_replace('/\s?]*?>.*?\s?/si', ' ', $text); Удаление атрибутов
Результат:
Удалить все атрибуты у тегов:
Результат:
Удалить атрибуты только у определенных HTML тегов:
$text = preg_replace("/()/i", '\\1\\2', $text); $text = preg_replace("/()/i", '\\1\\2', $text); Удаление тегов в ячейках таблицы
Регулярные выражения удаляют теги
и , но оставляет их содержание.
$text = ' text 1 text 2
text 3
'; // Удаление $text = preg_replace('/(]*>)(.*)(]*>)(.*)()(.*)()/i', '\\1\\2\\4\\6\\7', $text); // Удаление $text = preg_replace('/(]*>)(.*)(]*>)(.*)()(.*)()/i', '\\1\\2\\4\\6\\7', $text); print_r($text);
Результат:
Комментарии
Другие публикации


Протокол FTP – предназначен для передачи файлов на удаленный хост. В PHP функции для работы с FTP как правило всегда доступны и не требуется установка дополнительного расширения.
Если добавить атрибут contenteditable к элементу, его содержимое становится доступно для редактирования пользователю, а.
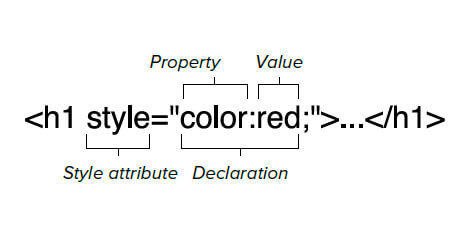
Данный вопрос возникает при верстке писем т.к. стили прописанные в head в почтовых сервисах и программах не работают, а.

Задача: появилась необходимость сделать якорное меню у ранее опубликованных статей, статей много, вручную дополнять их.
Как удалить все HTML-теги регулярным выражением?
Есть регулярное выражение (\<(/?[^>]+)>), которое оставляет HTML-тэги. Как наоборот удалить все тэги, оставив только текст?
Ответы (6 шт):
Так собственно её и можно использовать для чистки тегов, скормив в sub .
>>> import re >>> re.sub(r'(\<(/?[^>]+)>)', '', 'Текст с
тегами') 'Текст с тегами'
>>> console.log('Текст с
тегами'.replace(/(\<(\/?[^>]+)>)/g, '')) "Текст с тегами"
Только надо обязательно помнить, что никакое регулярное выражение не сможет правильно обработать сломанный html:
>>> line = ' >>>2 + 3 < 6
True тарий -->>> re.sub(r'(\<(/?[^>]+)>)', '', line) ' >>>2 + 3 True тарий -->
И для такого дела лучше применять полноценные html-парсеры, а регулярки к html-коду не подпускать вообще.
На данный момент, наиболее близкая к браузерной версия:
function textByBrowser(html) < var div = document.createElement("div"); div.innerHTML = html; return div.textContent; >function textByRegex(html) < return html.replace(//g, "").replace(/]*(>|$)/gi, ""); > var tests = [ '2+3alert("XSS!")', ' >>>2 + 3 < 6
True тарий -->>alert(1)>', '123\n' ]; tests.map(textByBrowser) + "" == tests.map(textByRegex) // true
Наличие угловых скобок в аттрибутах обрабатывается некорректно:
textByBrowser('123') // 123 textByRegex('123') // 1">23
И с мнемониками надо разобраться по своему усмотрению:
Обращаю внимание, что ни один из способов получения текста не является защитой от XSS-атак. При выводе пользовательского текста на странице всегда надо применять экранирование.
PS: Более ранняя версия ответа с другим кодом доступна в истории.
В php есть функция strip_tags - удаляет HTML и PHP тэги из строки
Как по мне, более точное определение тега будет таким
var htmlTage = "Hello world
"; var regExp = /(<.*?>)/g var result = htmlTage.replace(regExp, " "); console.log(result);
удалить html теги js
Чтобы решить задачу по удалению HTML тегов из строки в JavaScript можно использовать регулярное выражение и метод replace() . Вот пример:
const stringWithTags = 'Это текст с HTML тегами
'; const stringWithoutTags = stringWithTags.replace(/(([^>]+)>)/gi, ''); console.log(stringWithoutTags); // "Это текст с HTML тегами"
В этом примере мы используем регулярное выражение /(<([^>]+)>)/gi , которое ищет все HTML теги в строке и заменяет их на пустую строку. Затем мы выводим результат в консоль.