- Decision Tree Regression¶
- Регрессия дерева решений, объясненная реализацией в Python
- Что такое дерево решений?
- Как работает дерево решений?
- Регрессия дерева решений в Python
- 1. Импорт необходимых библиотек
- 2. Импорт набора данных
- 3. Разделение функций и целевой переменной
- 4. Разделение данных на набор поездов и тестовый набор
- 5. Подгонка модели к обучающему набору данных
- 6. Расчет потерь после тренировки
- 7. Визуализация дерева решений
- Собираем все вместе
Decision Tree Regression¶
The decision trees is used to fit a sine curve with addition noisy observation. As a result, it learns local linear regressions approximating the sine curve.
We can see that if the maximum depth of the tree (controlled by the max_depth parameter) is set too high, the decision trees learn too fine details of the training data and learn from the noise, i.e. they overfit.
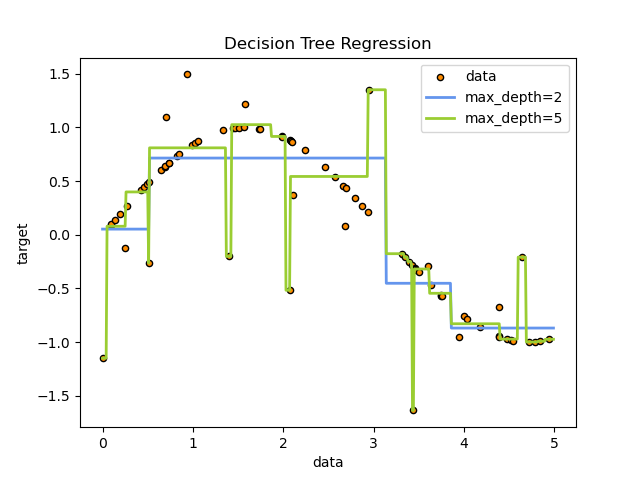
# Import the necessary modules and libraries import matplotlib.pyplot as plt import numpy as np from sklearn.tree import DecisionTreeRegressor # Create a random dataset rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axis=0) y = np.sin(X).ravel() y[::5] += 3 * (0.5 - rng.rand(16)) # Fit regression model regr_1 = DecisionTreeRegressor(max_depth=2) regr_2 = DecisionTreeRegressor(max_depth=5) regr_1.fit(X, y) regr_2.fit(X, y) # Predict X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] y_1 = regr_1.predict(X_test) y_2 = regr_2.predict(X_test) # Plot the results plt.figure() plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data") plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2) plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2) plt.xlabel("data") plt.ylabel("target") plt.title("Decision Tree Regression") plt.legend() plt.show()
Total running time of the script: ( 0 minutes 0.088 seconds)
Регрессия дерева решений, объясненная реализацией в Python
На этом уроке вы познакомитесь с другим типом алгоритма машинного обучения, который называется регрессией дерева решений.
Что такое дерево решений?
Дерево решений — это один из наиболее часто используемых алгоритмов машинного обучения для решения задач регрессии, а также задач классификации. Как следует из названия, алгоритм использует древовидную модель решений либо для прогнозирования целевого значения (регрессия), либо для прогнозирования целевого класса (классификация). Прежде чем углубиться в то, как работают деревья решений, сначала давайте познакомимся с основными терминами дерева решений:

- Корневой узел. Это самый верхний узел дерева, представляющий все точки данных.
- Разделение. Это относится к разделению узла на два или более подузлов.
- Узел принятия решения. Это узлы, которые в дальнейшем делятся на подузлы, т. е. этот разделенный узел называется узлом принятия решения.
- Листовой/конечный узел. Узлы, которые не разделяются, называются конечными или конечными узлами. Эти узлы часто являются конечным результатом дерева.
- Ветвь/Поддерево. Подраздел всего дерева называется ветвью или поддеревом.
- Родительский и дочерний узел.Узел, который разделен на подузлы, называется родительским узлом подузлов, тогда как подузлы являются дочерними по отношению к родительскому узлу. На рисунке выше узел принятия решений является родителем терминальных узлов (дочерним).
- Сокращение. Удаление подузлов узла принятия решений называется сокращением. Обрезка часто выполняется в деревьях решений, чтобы предотвратить переоснащение.
Как работает дерево решений?
Процесс разделения начинается в корневом узле, за ним следует разветвленное дерево, которое, наконец, приводит к конечному узлу (конечному узлу), содержащему прогноз или окончательный результат алгоритма. Построение деревьев решений обычно работает сверху вниз, выбирая переменную на каждом шаге, которая лучше всего разделяет набор элементов. Каждое поддерево модели дерева решений может быть представлено как бинарное дерево, в котором узел решения разбивается на два узла в зависимости от условий.
Деревья решений, в которых целевая переменная или конечный узел могут принимать непрерывные значения (обычно действительные числа), называются деревьями регрессии и будут обсуждаться в этом уроке. Если целевая переменная может принимать дискретный набор значений, эти деревья называются деревьями классификации.
Регрессия дерева решений в Python
Теперь мы рассмотрим пошаговую реализацию Python алгоритма регрессии дерева решений, который мы только что обсуждали.
1. Импорт необходимых библиотек
Во-первых, давайте импортируем некоторые необходимые библиотеки Python.
# Importing the libraries import numpy as np # for array operations import pandas as pd # for working with DataFrames import requests, io # for HTTP requests and I/O commands import matplotlib.pyplot as plt # for data visualization %matplotlib inline # scikit-learn modules from sklearn.model_selection import train_test_split # for splitting the data from sklearn.metrics import mean_squared_error # for calculating the cost function from sklearn.tree import DecisionTreeRegressor # for building the model
2. Импорт набора данных
Для этой задачи мы будем загружать набор данных CSV через HTTP-запрос (вы также можете скачать набор данных здесь).
Набор данных состоит из данных о потреблении бензина (в миллионах галлонов) в 48 штатах США. Это значение основано на нескольких характеристиках, таких как налог на бензин (в центах), средний доход (в долларах), дороги с твердым покрытием (в милях) и доля населения с водительскими правами. Мы будем загружать набор данных с помощью функции read_csv() из модуля pandas и хранить его как объект pandas DataFrame.
# Importing the dataset from the url of the dataset url = "https://drive.google.com/u/0/uc?id=1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_&export=download" data = requests.get(url).content # Reading the data dataset = pd.read_csv(io.StringIO(data.decode('utf-8'))) dataset.head() 
3. Разделение функций и целевой переменной
После загрузки набора данных независимая переменная и зависимая переменная должны быть разделены. Наша задача — смоделировать отношения между функциями (налог_на бензин, средний_доход и т. д.) и целевой переменной (потребление_бензина) в наборе данных.
x = dataset.drop('Petrol_Consumption', axis = 1) # Features y = dataset['Petrol_Consumption'] # Target 4. Разделение данных на набор поездов и тестовый набор
Мы используем модуль scikit-learn train_test_split () для разделения данных на набор поездов и набор тестов. Мы будем использовать 20% доступных данных в качестве набора для тестирования, а оставшиеся данные — в качестве набора для обучения.
# Splitting the dataset into training and testing set (80/20) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 28)
5. Подгонка модели к обучающему набору данных
После разделения данных давайте инициализируем модель регрессора дерева решений и подгоним ее к обучающим данным. Это делается с помощью модуля scikit-learn DecisionTreeRegressor().
# Initializing the Decision Tree Regression model model = DecisionTreeRegressor(random_state = 0) # Fitting the Decision Tree Regression model to the data model.fit(x_train, y_train)
6. Расчет потерь после тренировки
Давайте теперь рассчитаем потерю между фактическими целевыми значениями в тестовом наборе и значениями, предсказанными моделью, с использованием функции стоимости, называемой среднеквадратичной ошибкой (RMSE).

RMSE модели определяет абсолютное соответствие модели данным. Другими словами, он указывает, насколько близки фактические точки данных к прогнозируемым значениям модели. Низкое значение RMSE указывает на лучшее соответствие и является хорошей мерой для определения точности прогнозов модели.
# Predicting the target values of the test set y_pred = model.predict(x_test) # RMSE (Root Mean Square Error) rmse = float(format(np.sqrt(mean_squared_error(y_test, y_pred)), '.3f')) print("\nRMSE: ", rmse) OUTPUT: RMSE: 133.351 7. Визуализация дерева решений
После построения и выполнения модели мы также можем просмотреть древовидную структуру модели, созданной с помощью инструмента WebGraphviz. Мы будем копировать содержимое файла tree_structure.dot, сохраненного в локальный рабочий каталог, в область ввода инструмента WebGraphviz, который затем создаст визуализированную структуру нашего дерева решений.
from sklearn.tree import export_graphviz # export the decision tree model to a tree_structure.dot file # paste the contents of the file to webgraphviz.com export_graphviz(model, out_file ='tree_structure.dot', feature_names =['Petrol_tax', 'Average_income', 'Paved_Highways', 'Population_Driver_licence(%)'])

Это пример подветви того, как выглядит наше дерево решений.
Собираем все вместе
Окончательный код для реализации регрессии дерева решений в Python выглядит следующим образом.
# Importing the libraries import numpy as np # for array operations import pandas as pd # for working with DataFrames import requests, io # for HTTP requests and I/O commands import matplotlib.pyplot as plt # for data visualization %matplotlib inline # scikit-learn modules from sklearn.model_selection import train_test_split # for splitting the data from sklearn.metrics import mean_squared_error # for calculating the cost function from sklearn.tree import DecisionTreeRegressor # for building the model # Importing the dataset from the url of the data set url = "https://drive.google.com/u/0/uc?id=1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_&export=download" data = requests.get(url).content # Reading the data dataset = pd.read_csv(io.StringIO(data.decode('utf-8'))) dataset.head() x = dataset.drop('Petrol_Consumption', axis = 1) # Features y = dataset['Petrol_Consumption'] # Target # Splitting the dataset into training and testing set (80/20) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 28) # Initializing the Decision Tree Regression model model = DecisionTreeRegressor(random_state = 0) # Fitting the Decision Tree Regression model to the data model.fit(x_train, y_train) # Predicting the target values of the test set y_pred = model.predict(x_test) # RMSE (Root Mean Square Error) rmse = float(format(np.sqrt(mean_squared_error(y_test, y_pred)),'.3f')) print("\nRMSE:",rmse) # Visualizing the decision tree structure from sklearn.tree import export_graphviz # export the decision tree model to a tree_structure.dot file # paste the contents of the file to webgraphviz.com export_graphviz(model, out_file ='tree_structure.dot', feature_names = ['Petrol_tax', 'Average_income', 'Paved_Highways', 'Population_Driver_licence(%)']) В этом уроке мы обсудили работу регрессии дерева решений и ее реализацию в Python.

Вы хотите изучать Python, науку о данных и машинное обучение во время получения сертификата? Вот несколько самых продаваемых курсов Udemy, на которые мы рекомендуем вам записаться:
- 2021 Complete Python Bootcamp From Zero to Hero in Python — уже зачислено более 1 000 000 студентов!
- Python для Data Science and Machine Learning Bootcamp — уже зачислено более 400 000 студентов!
- Полное руководство по TensorFlow для глубокого обучения с помощью Python — уже зачислено более 90 000 студентов!
- Учебный курс по науке о данных и машинному обучению с R — уже зачислено более 70 000 студентов!
- Полный курс SQL Bootcamp 2021: от нуля до героя — уже зачислено более 400 000 студентов!
Отказ от ответственности. Когда вы совершаете покупку по приведенным выше ссылкам, мы можем получать комиссию в качестве партнера.