- Read Large Text file in Python
- 2 Answers 2
- How to read large text files in Python?
- Problem with readline() method to read large text files
- Read large text files in Python using iterate
- How to Read Large Text Files in Python
- Reading Large Text Files in Python
- What if the Large File doesn’t have lines?
- Process very large (>20GB) text file line by line
Read Large Text file in Python
This process is taking a lot of time, How can I process this to read all the contents in about 2 hours ?
its not exactly process_lines. Each line consists of «word,word1,word2» I ‘m splitting these three words (.split(«,»)) and writing them to 3 separate files using f.write()
If processing each line is independent, this problem can be modelled under divide and conquer. First split the large file into smaller files using Linux split command. Later, run the same program on the split files, preferably in parallel.
2 Answers 2
The bottleneck of the performance of your script likely comes from the fact that it is writing to 3 files at the same time, causing massive fragmentation between the files and hence lots of overhead.
So instead of writing to 3 files at the same time as you read through the lines, you can buffer up a million lines (which should take less than 1GB of memory), before you write the 3 million words to the output files one file at a time, so that it will produce much less file fragmentation:
def write_words(words, *files): for i, file in enumerate(files): for word in words: file.write(word[i] + '\n') words = [] with open('input.txt', 'r') as f, open('words1.txt', 'w') as out1, open('words2.txt', 'w') as out2, open('words3.txt', 'w') as out3: for count, line in enumerate(f, 1): words.append(line.rstrip().split(',')) if count % 1000000 == 0: write_words(words, out1, out2, out3) words = [] write_words(words, out1, out2, out3) How to read large text files in Python?
In this article, we will try to understand how to read a large text file using the fastest way, with less memory usage using Python.
To read large text files in Python, we can use the file object as an iterator to iterate over the file and perform the required task. Since the iterator just iterates over the entire file and does not require any additional data structure for data storage, the memory consumed is less comparatively. Also, the iterator does not perform expensive operations like appending hence it is time-efficient as well. Files are iterable in Python hence it is advisable to use iterators.
Problem with readline() method to read large text files
In Python, files are read by using the readlines() method. The readlines() method returns a list where each item of the list is a complete sentence in the file. This method is useful when the file size is small. Since readlines() method appends each line to the list and then returns the entire list it will be time-consuming if the file size is extremely large say in GB. Also, the list will consume a large chunk of the memory which can cause memory leakage if sufficient memory is unavailable.
Read large text files in Python using iterate
In this method, we will import fileinput module. The input() method of fileinput module can be used to read large files. This method takes a list of filenames and if no parameter is passed it accepts input from the stdin, and returns an iterator that returns individual lines from the text file being scanned.
Note: We will also use it to calculate the time taken to read the file using Python time.
How to Read Large Text Files in Python

While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Python File object provides various ways to read a text file. The popular way is to use the readlines() method that returns a list of all the lines in the file. However, it’s not suitable to read a large text file because the whole file content will be loaded into the memory.
Reading Large Text Files in Python
We can use the file object as an iterator. The iterator will return each line one by one, which can be processed. This will not read the whole file into memory and it’s suitable to read large files in Python. Here is the code snippet to read large file in Python by treating it as an iterator.
import resource import os file_name = "/Users/pankaj/abcdef.txt" print(f'File Size is MB') txt_file = open(file_name) count = 0 for line in txt_file: # we can process file line by line here, for simplicity I am taking count of lines count += 1 txt_file.close() print(f'Number of Lines in the file is ') print('Peak Memory Usage =', resource.getrusage(resource.RUSAGE_SELF).ru_maxrss) print('User Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_utime) print('System Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_stime) File Size is 257.4920654296875 MB Number of Lines in the file is 60000000 Peak Memory Usage = 5840896 User Mode Time = 11.46692 System Mode Time = 0.09655899999999999 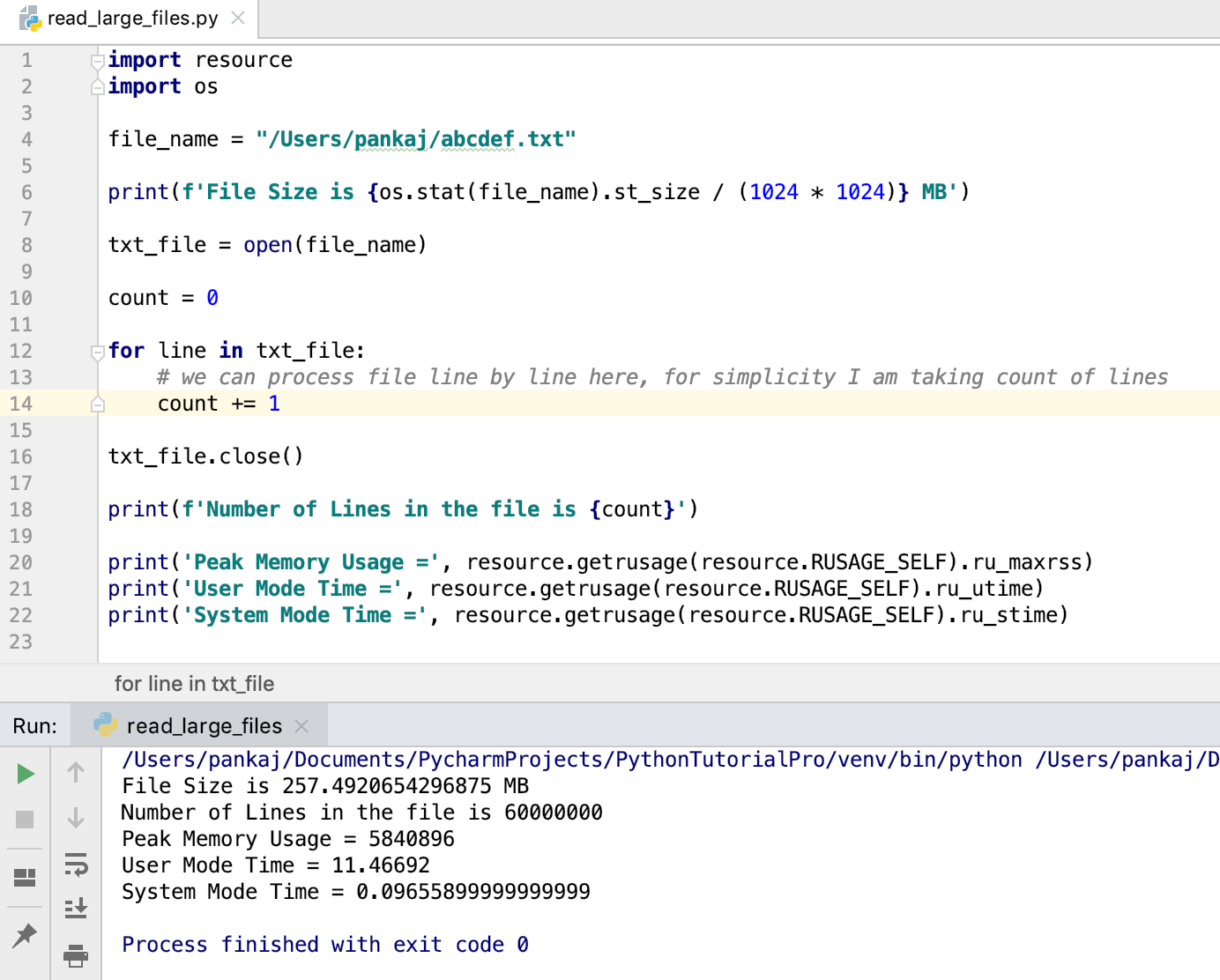
- I am using os module to print the size of the file.
- The resource module is used to check the memory and CPU time usage of the program.
We can also use with statement to open the file. In this case, we don’t have to explicitly close the file object.
with open(file_name) as txt_file: for line in txt_file: # process the line pass What if the Large File doesn’t have lines?
The above code will work great when the large file content is divided into many lines. But, if there is a large amount of data in a single line then it will use a lot of memory. In that case, we can read the file content into a buffer and process it.
with open(file_name) as f: while True: data = f.read(1024) if not data: break print(data) The above code will read file data into a buffer of 1024 bytes. Then we are printing it to the console. When the whole file is read, the data will become empty and the break statement will terminate the while loop. This method is also useful in reading a binary file such as images, PDF, word documents, etc. Here is a simple code snippet to make a copy of the file.
with open(destination_file_name, 'w') as out_file: with open(source_file_name) as in_file: for line in in_file: out_file.write(line) Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Process very large (>20GB) text file line by line
I have a number of very large text files which I need to process, the largest being about 60GB. Each line has 54 characters in seven fields and I want to remove the last three characters from each of the first three fields — which should reduce the file size by about 20%. I am brand new to Python and have a code which will do what I want to do at about 3.4 GB per hour, but to be a worthwhile exercise I really need to be getting at least 10 GB/hr — is there any way to speed this up? This code doesn’t come close to challenging my processor, so I am making an uneducated guess that it is limited by the read and write speed to the internal hard drive?
def ProcessLargeTextFile(): r = open("filepath", "r") w = open("filepath", "w") l = r.readline() while l: x = l.split(' ')[0] y = l.split(' ')[1] z = l.split(' ')[2] w.write(l.replace(x,x[:-3]).replace(y,y[:-3]).replace(z,z[:-3])) l = r.readline() r.close() w.close() Any help would be really appreciated. I am using the IDLE Python GUI on Windows 7 and have 16GB of memory — perhaps a different OS would be more efficient?. Edit: Here is an extract of the file to be processed.
70700.642014 31207.277115 -0.054123 -1585 255 255 255 70512.301468 31227.990799 -0.255600 -1655 155 158 158 70515.727097 31223.828659 -0.066727 -1734 191 187 180 70566.756699 31217.065598 -0.205673 -1727 254 255 255 70566.695938 31218.030807 -0.047928 -1689 249 251 249 70536.117874 31227.837662 -0.033096 -1548 251 252 252 70536.773270 31212.970322 -0.115891 -1434 155 158 163 70533.530777 31215.270828 -0.154770 -1550 148 152 156 70533.555923 31215.341599 -0.138809 -1480 150 154 158