- 1 Тема и цель курсовой работы
- 2 Основы теории разработки компиляторов
- 2.1 Описание синтаксиса языка программирования
- Формальные грамматики
- Формы Бэкуса-Наура (бнф)
- 21.1. Синтаксис и семантика языков программирования
- 21.2. Структура языков программирования
- Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
- Немного теории
- Что тут происходит:
- 1) Lexer
- 2) Parser
- 3) Compiler
- Habrlang
1 Тема и цель курсовой работы
Тема курсовой работы: «Разработка компилятора модельного языка программирования».
- закрепление теоретических знаний в области теории формальных языков, грамматик, автоматов и методов трансляции;
- формирование практических умений и навыков разработки собственного компилятора модельного языка программирования;
- закрепление практических навыков самостоятельного решения инженерных задач, развитие творческих способностей студентов и умений пользоваться технической, нормативной и справочной литературой.
2 Основы теории разработки компиляторов
2.1 Описание синтаксиса языка программирования
Существуют три основных метода описания синтаксиса языков программирования: формальные грамматики, формы Бэкуса-Наура и диаграммы Вирта.
Формальные грамматики
Определение 2.1. Формальной грамматикой называется четверка вида:  , (1.1) где VN — конечное множество нетерминальных символов грамматики (обычно прописные латинские буквы); VT — множество терминальных символов грамматики (обычно строчные латинские буквы, цифры, и т.п.), VT VN =; Р – множество правил вывода грамматики, являющееся конечным подмножеством множества (VT VN) + (VT VN) * ; элемент (, ) множества Р называется правилом вывода и записывается в виде (читается: «из цепочки выводится цепочка »); S – начальный символ грамматики, S VN. Для записи правил вывода с одинаковыми левыми частями вида
, (1.1) где VN — конечное множество нетерминальных символов грамматики (обычно прописные латинские буквы); VT — множество терминальных символов грамматики (обычно строчные латинские буквы, цифры, и т.п.), VT VN =; Р – множество правил вывода грамматики, являющееся конечным подмножеством множества (VT VN) + (VT VN) * ; элемент (, ) множества Р называется правилом вывода и записывается в виде (читается: «из цепочки выводится цепочка »); S – начальный символ грамматики, S VN. Для записи правил вывода с одинаковыми левыми частями вида  используется сокращенная форма записи
используется сокращенная форма записи . Пример 2.1. Опишем с помощью формальных грамматик синтаксис паскалеподобного модельного языка М. Грамматика будет иметь правила вывода вида: P program D2 B. D2 var D1 D1 D | D1; D D I1: int | I1: bool I1 I | I1, I B begin S1 end S1 S | S1; S S begin S1 end | if E then S else S | while E do S | read(I) | write(E) E E1 | E1=E1 | E1>E1 | E1E1 El T | T+E1 | T—E1 | TEl T F | F*T | F/T | FT F I | N | L | F | (E) L true | false I C | IC | IR N R | NR C a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z R 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
. Пример 2.1. Опишем с помощью формальных грамматик синтаксис паскалеподобного модельного языка М. Грамматика будет иметь правила вывода вида: P program D2 B. D2 var D1 D1 D | D1; D D I1: int | I1: bool I1 I | I1, I B begin S1 end S1 S | S1; S S begin S1 end | if E then S else S | while E do S | read(I) | write(E) E E1 | E1=E1 | E1>E1 | E1E1 El T | T+E1 | T—E1 | TEl T F | F*T | F/T | FT F I | N | L | F | (E) L true | false I C | IC | IR N R | NR C a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z R 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Формы Бэкуса-Наура (бнф)
- символ «::=» отделяет левую часть правила от правой (читается: «определяется как»);
- нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «»;
- терминалы — это символы, используемые в описываемом языке;
- правило может определять порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|» (читается: «или»).
21.1. Синтаксис и семантика языков программирования
У каждого языка программирования, как и у любого естественного языка, есть свои синтаксис и семантика.
Синтаксис — совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря, это совокупность правил образования семантически значимых последовательностей символов в данном языке. Синтаксис задается с помощью правил, которые описывают понятия некоторого языка. Примерами понятий являются: переменная, выражение, оператор, процедура. Последовательность понятий и их допустимое использование в правилах определяет синтаксически правильные структуры, образующие программы. Именно иерархия объектов, а не то, как они взаимодействуют между собой, определяются через синтаксис. Например, оператор может встречаться только в процедуре, а выражение в операторе, переменная может состоять из имени и необязательных индексов и т.д. Синтаксис не связан с такими явлениями в программе, как «несоответствие типов» или «переменная с данным именем не определена». Этим занимается семантика.
Семантика — правила и условия, определяющие соотношения между элементами языка и их смысловыми значениями, а также интерпретацию содержательного значения синтаксических конструкций языка. Объекты языка программирования не только размещаются в тексте в соответствии с некоторой иерархией, но и дополнительно связаны между собой посредством других понятий, образующих разнообразные ассоциации. Например, переменная, для которой синтаксис определяет допустимое местоположение только в описаниях и некоторых операторах, обладает определенным типом, может использоваться с ограниченным множеством операций, имеет адрес, размер и должна быть описана до того, как будет использоваться в программе.
Текст исходной программы на языке высокого уровня представляет собой обычный тестовый файл. Для его «чтения» и превращения в последовательность машинных команд, прежде всего, выполняется синтаксический анализ текста программы.
Синтаксический анализатор — компонента компилятора, осуществляющая проверку исходных операторов на соответствие синтаксическим правилам и семантике данного языка программирования. Несмотря на название, анализатор занимается проверкой и синтаксиса, и семантики. Он состоит из нескольких блоков, каждый из которых решает свои задачи.
21.2. Структура языков программирования
Языки программирования достаточно сильно отличаются друг от друга по назначению, структуре, семантической сложности, методам реализации. Это накладывает свои специфические особенности на разработку конкретных трансляторов. Структура языка характеризует иерархические отношения между его понятиями, которые описываются синтаксическими правилами. Языки программирования могут сильно отличаться друг от друга по организации отдельных понятий и по отношениям между ними. Например, язык C++ допускает описание переменных в любой точке программы перед первым ее использованием, а в Паскале переменные должны быть определены в специальной области описания. В зависимости от принятого решения, транслятор может анализировать программу за один или несколько проходов, что влияет на скорость трансляции.
Семантика языков программирования изменяется в очень широких пределах. Они отличаются не только по особенностям реализации отдельных операций, но и по парадигмам программирования, определяющим принципиальные различия в методах разработки программ. Специфика реализации операций может касаться как структуры обрабатываемых данных, так и правил обработки одних и тех же типов данных. Даже при выполнении операции сложения двух целых чисел такие языки, как C и Паскаль, могут вести себя по-разному.
Один и тот же язык может быть реализован нескольким способами. Это связано с тем, что теория формальных грамматик допускает различные методы разбора одних и тех же предложений. В соответствии с этим трансляторы разными способами могут получать один и тот же результат (объектную программу) по первоначальному исходному тексту. Существует несколько компиляторов языка Паскаль: Turbo Pascal, MS Pascal, Pascal with Objects, Delphi, Builder. Вместе с тем, все языки программирования обладают рядом общих характеристик и параметров. Эта общность определяет и схожие для всех языков принципы организации трансляторов.
Для любого языка его создателями определяются:
- множество символов, которые можно использовать для записи правильных программ (алфавит);
- множество правильных программ (синтаксис);
- «смысл» каждой правильной программы (семантика).
Рассмотрим пример синтаксического разбора. Пусть в исходном тексте программы встретилась формула a + (b + c) * d. В большинстве языков программирования такая формула определяет иерархию программных объектов, которую можно отобразить в виде дерева (Рис. 21 .79). В кружках представлены символы, используемые в качестве элементарных конструкций, а в прямоугольниках задаются составные понятия, имеющие иерархическую и, возможно, рекурсивную структуру.
Синтаксическая структура, правильная для одного языка, может быть ошибочной для другого. Например, в языке Лисп приведенное выражение не будет распознано. Однако для этого языка корректным будет являться выражение ( * ( + a b c ) d ).
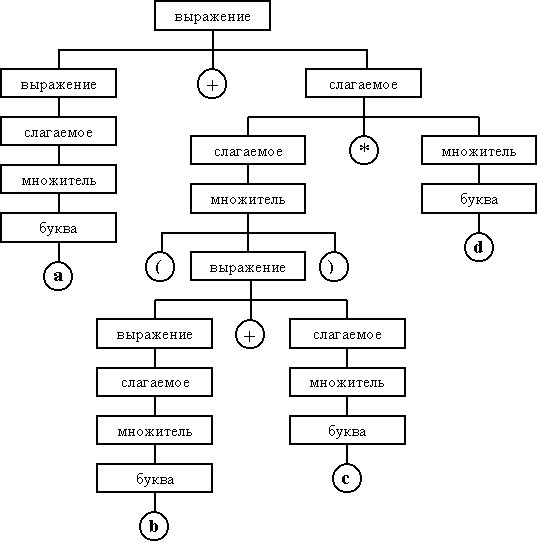
Рис. 21.79. Дерево синтаксического разбора.
Другой характерной особенностью всех языков является их семантика. Она определяет смысл операций языка, корректность операндов. Цепочки, имеющие одинаковую синтаксическую структуру в различных языках программирования, могут различаться по семантике (что, например, наблюдается в C++, Pascal, Basic для приведенного выше фрагмента арифметического выражения). Знание семантики языка позволяет отделить ее от его синтаксиса и использовать для преобразования в другой язык (осуществить генерацию кода). Описание семантики и распознавание ее корректности обычно является самой трудоемкой и объемной частью транслятора, так как необходимо осуществить перебор и анализ множества вариантов допустимых комбинаций операций и операндов.
Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель «убить» CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — «понять», так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой «лисп»/»питон»/»ваш абсолютно новый синтаксис» на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github’е. Тегами обозначены начало и концы статей для удобства.
Немного теории
Не углубляясь в википедийность, процесс трансляции исходного кода в конечный JS код протекает следующим образом:
source code -(Lexer)-> tokens -(Parser)-> AST -(Compiler)-> js codeЧто тут происходит:
1) Lexer
Исходный код нашей программы разбивается на лексемы. По-простому это нахождение в исходном тексте ключевых слов, литералов, символов, идентификаторов и т.д.
Т.е. на выходе из этого (CoffeeScript):
a = true if a console.log('Hello, lexer')Мы получаем это (сокращенная запись):
[IDENTIFIER:"a"] [ASSIGN:"="] [BOOLEAN:"true"] [NEWLINE:"\n"] [NEWLINE:"\n"] [KEYWORD:"if"] [IDENTIFIER:"a"] [NEWLINE:"\n"] [INDENT:" "] [IDENTIFIER:"console"] [DOT:"."] [IDENTIFIER:"log"] [ROUND_BRAKET_START:"("] [STRING:"'Hello, lexer'"] [ROUND_BRAKET_END:")"] [NEWLINE:"\n"] [OUTDENT:""] [EOF:"EOF"]Так-как CoffeeScript отступо-чувствительный и не имеет явного выделения блока скобками < и >, блоки отделяются отступами ( INDENT ом и OUTDENT ом), которые по сути заменяет скобки.
2) Parser
Парсер составляет AST из токенов (лексем). Он обходит весь массив и рекурсивно подбирает подходящие паттерны, основываясь на типи токена или их последовательности.
Из полученных токенов в пункте 1, parser составит, примерно такое дерево (сокращенная запись):
< type: 'ROOT', // Основная нода нешего дерава nodes: [< type: 'VARIABLE', // a = true id: < type: 'IDENTIFIER', value: 'a' >, init: < type: 'LITERAL', value: true >>, < type: 'IF_STATEMENT', // Условное выражение test: < type: 'IDENTIFIER', value: 'a' >, consequent: < type: 'BLOCK_STATEMENT', nodes: [< type: 'EXPRESSION_STATEMENT', // Вызов console.log expression: < type: 'CALL_EXPRESSION', callee: < type: 'MEMBER_EXPRESSION', object: < type: 'IDENTIFIER', value: 'console' >, property: < type: 'IDENTIFIER', value: 'log' >>, arguments: [< type: 'LITERAL', value: 'Hello, lexer' >] > >] > >] >Не стоит пугаться объема дерева, на деле он генерируется рекурсивно и его создание не вызывает трудностей.
3) Compiler
Построение конечного кода по AST. Этот пункт можно заменить на компиляцию в байткод, или даже рантайм, но в рамках данной серии статей мы рассмотрим реализацию транслятора в другой язык программирования.
Компилятор (читай транслятор) преобразует Абстрактно-Синтаксическое Дерево в JavaScript код:
Вот и все. Большинство компиляторов работают именно по такому принципу (с незначительными изменениями. Иногда добавляют процесс стримминга исходного текста в поток символов, иногда напротив объединяют парсинг и компиляцию в один этап, но не нам их судить).
Habrlang
Итак, разобравшись с теорией, нам предстоит собрать свой язык программирования, у которого будет примерно следующий синтаксис (что-бы не особо париться, мы будем делать смесь из Ruby, Python и CoffeeScript):
#!/bin/habrlang # Hello habrlang def hello В следующей главе вы реализуем все основные классы нашего транслятора, и научим его транслировать комментарии Habrlang'а в JavaScript.