- Распознавание речи на python с помощью pocketsphinx или как я пытался сделать голосового ассистента
- Установка Pocketsphinx
- Распознавание речи при помощи pocketsphinx
- Русская языковая и акустическая модель
- JSGF
- Создаем свой словарь
- Использование pocketsphinx через speech_recognition
- Итог
- Распознавание и анализ речи с помощью библиотеки SPEECH RECOGNITION, PYAUDIO и LIBROSA
Распознавание речи на python с помощью pocketsphinx или как я пытался сделать голосового ассистента
Это туториал по использованию библиотеки pocketsphinx на Python. Надеюсь он поможет вам
побыстрее разобраться с этой библиотекой и не наступать на мои грабли.
Началось все с того, что захотел я сделать себе голосового ассистента на python. Изначально для распознавания решено было использовать библиотеку speech_recognition. Как оказалось, я не один такой. Для распознавания я использовал Google Speech Recognition, так как он единственный не требовал никаких ключей, паролей и т.д. Для синтеза речи был взят gTTS. В общем получился почти клон этого ассистента, из-за чего я не мог успокоиться.
Правда, успокоиться я не мог не только из-за этого: ответа приходилось ждать долго (запись заканчивалась не сразу, отправка речи на сервер для распознавания и текста для синтеза занимала немало времени), речь не всегда распознавалась правильно, дальше полуметра от микрофона приходилось кричать, говорить нужно было четко, синтезированная гуглом речь звучала ужасно, не было активационной фразы, то есть звуки постоянно записывались и передавались на сервер.
Первым усовершенствованием был синтез речи при помощи yandex speechkit cloud:
URL = 'https://tts.voicetech.yandex.net/generate?text='+text+'&format=wav&lang=ru-RU&speaker=ermil&key='+key+'&speed=1&emotion=good' response=requests.get(URL) if response.status_code==200: with open(speech_file_name,'wb') as file: file.write(response.content)Затем настала очередь распознавания. Меня сразу заинтересовала надпись «CMU Sphinx (works offline)» на странице библиотеки. Я не буду рассказывать об основных понятиях pocketsphinx, т.к. до меня это сделал chubakur(за что ему большое спасибо) в этом посте.
Установка Pocketsphinx
Сразу скажу, так просто pocketsphinx установить не получится(по крайней мере у меня не получилось), поэтому pip install pocketsphinx не сработает, упадет с ошибкой, будет ругаться на wheel. Установка через pip будет работать только если у вас стоит swig. В противном случае чтобы установить pocketsphinx нужно перейти вот сюда и скачать установщик(msi). Обратите внимание: установщик есть только для версии 3.5!
Распознавание речи при помощи pocketsphinx
Pocketsphinx может распознавать речь как с микрофона, так и из файла. Также он может искать горячие фразы(у меня не очень получилось, почему-то код, который должен выполняться когда находится горячее слово выполняется несколько раз, хотя произносил его я только один). От облачных решений pocketsphinx отличается тем, что работает оффлайн и может работать по ограниченному словарю, вследствие чего повышается точность. Если интересно, на странице библиотеки есть примеры. Обратите внимание на пункт «Default config».
Русская языковая и акустическая модель
Изначально pocketsphinx идет с английской языковой и акустической моделями и словарем. Скачать русские можно по этой ссылке. Архив нужно распаковать. Затем надо папку /zero_ru_cont_8k_v3/zero_ru.cd_cont_4000 переместить в папку C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model , где это папка в которую вы распаковали архив. Перемещенная папка — это акустическая модель. Такую же процедуру надо проделать с файлами ru.lm и ru.dic из папки /zero_ru_cont_8k_v3/ . Файл ru.lm это языковая модель, а ru.dic это словарь. Если вы все сделали правильно, то следующий код должен работать.
import os from pocketsphinx import LiveSpeech, get_model_path model_path = get_model_path() speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=os.path.join(model_path, 'ru.lm'), dic=os.path.join(model_path, 'ru.dic') ) print("Say something!") for phrase in speech: print(phrase)Предварительно проверьте чтобы микрофон был подключен и работал. Если долго не появляется надпись Say something! — это нормально. Большую часть этого времени занимает создание экземпляра LiveSpeech , который создается так долго потому, что русская языковая модель весит более 500(!) мб. У меня экземпляр LiveSpeech создается около 2 минут.
Этот код должен распознавать почти любые произнесенные вами фразы. Согласитесь, точность отвратительная. Но это можно исправить. И увеличить скорость создания LiveSpeech тоже можно.
JSGF
Вместо языковой модели можно заставить pocketsphinx работать по упрощенной грамматике. Для этого используется jsgf файл. Его использование ускоряет создание экземпляра LiveSpeech . О том как создавать файлы граматики написано здесь. Если языковая модель есть, то jsgf файл будет игнорироваться, поэтому если вы хотите использовать собственный файл грамматики, то нужно писать так:
speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=False, jsgf=os.path.join(model_path, 'grammar.jsgf'), dic=os.path.join(model_path, 'ru.dic') )Естественно файл с грамматикой надо создать в папке C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model . И еще: при использовании jsgf придется четче говорить и разделять слова.
Создаем свой словарь
Словарь — это набор слов и их транскрипций, чем он меньше, тем выше точность распознавания. Для создания словаря с русскими словами нужно воспользоваться проектом ru4sphinx. Качаем, распаковываем. Затем открываем блокнот и пишем слова, которые должны быть в словаре, каждое с новой строки, затем сохраняем файл как my_dictionary.txt в папке text2dict , в кодировке UTF-8. Затем открываем консоль и пишем: C:\Users\tutam\Downloads\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt . Открываем my_dictionary_out.txt , копируем содержимое. Открываем блокнот, вставляем скопированный текст и сохраняем файл как my_dict.dic (вместо «текстовый файл» выберите «все файлы»), в кодировке UTF-8.
speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=os.path.join(model_path, 'ru.lm'), dic=os.path.join(model_path, 'my_dict.dic') )Некоторые транскрипции может быть нужно подправить.
Использование pocketsphinx через speech_recognition
Использовать pocketsphinx через speech_recognition имеет смысл только если вы распознаете английскую речь. В speech_recognition нельзя указать пустую языковую модель и использовать jsgf, а следовательно для распознавания каждого фрагмента придется ждать 2 минуты. Проверенно.
Итог
Угробив несколько вечеров я понял, что потратил время впустую. В словаре из двух слов(да и нет) сфинкс умудряется ошибаться, причем часто. Отъедает 30-40% celeron’а, а с языковой моделью еще и жирный кусок памяти. А Яндекс почти любую речь распознает безошибочно, при том не ест память и процессор. Так что думайте сами, стоит ли за это браться вообще.
P.S.: это мой первый пост, так что жду советы по оформлению и содержанию статьи.
Распознавание и анализ речи с помощью библиотеки SPEECH RECOGNITION, PYAUDIO и LIBROSA
В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами скрытую марковскую модель можно объяснить на примере.

Допустим, есть два человека, которые каждый вечер созваниваются и обсуждают свои действия в течение дня. Выбор одного из друзей: ходил за покупками; гулял в парке; занимался домашними делами. При выборе активности, он полагался лишь на погоду. Второй же знал о погоде, которая была на тот момент в месте первого и, основываясь на выборе первого, мог догадаться, какая погода была в какой-то момент.
То есть, допустим, мы делим сигнал на фрагменты скажем в 10 миллисекунд и выделяем кепстральные коэффициенты, которые, по сути, являются графиком зависимости мощности от частоты сигнала отображающегося на векторе действительных чисел. Результатом скрытой марковской модели является последовательность этих векторов.
В последствии мы сопоставляем фонемы и эти векторы, а так как звук фонемы изменяется от источника к источнику, то процесс сопоставления требует обучения.
Для python существует несколько пакетов которые используются в данной сфере речи, такие как apiai, assemblyai и другие, но Speech Recognition выделяется среди них довольно высокой простотой использования.
Библиотека Speech Recognition — это, инструмент для передачи речевых API от компаний (google, microsoft, sound hound, ibm, а также pocketsphinx), который в отличие от остальных имеет возможность работы офлайн.
Для демонстрации работы в данной статье я буду использовать дефолтный Google Speech API.
Также для работы с инструментами потребуется библиотека pyAudio.
Установим библиотеку для распознавания речи:
pip install SpeechRecognition Для работы с инструментами звукозаписи
Бываю некие сложности с установкой pyaudio через pip, поэтому альтернативный вариант — установка pipwin или conda
Для анализа звуковых данных
Для работы с wave файлами
import speech_recognition as speech_r import pyaudio import waveДля начала нужно выставить параметры записи звука:
CHUNK = 1024 # определяет форму ауди сигнала FRT = pyaudio.paInt16 # шестнадцатибитный формат задает значение амплитуды CHAN = 1 # канал записи звука RT = 44100 # частота REC_SEC = 5 #длина записи OUTPUT = "output.wav"Далее нужно создать объект для обращения к устройству звукозаписи:
и открыть поток для записи звука:
stream = p.open(format=FRT,channels=CHAN,rate=RT,input=True,frames_per_buffer=CHUNK) # открываем поток для записи print("rec") frames = [] # формируем выборку данных фреймов for i in range(0, int(RT / CHUNK * REC_SEC)): data = stream.read(CHUNK) frames.append(data) print("done") и закрываем поток stream.stop_stream() # останавливаем и закрываем поток stream.close() p.terminate()Дальше нам нужно записать оцифрованную звуковую дорожку в файл.
Для этого нам и пригодится библиотека wave:
w = wave.open(OUTPUT, 'wb') w.setnchannels(CHAN) w.setsampwidth(p.get_sample_size(FRT)) w.setframerate(RT) w.writeframes(b''.join(frames)) w.close()В итоге мы получаем готовую звуковую дорожку записанную с микрофона устройства и готовую к распознаванию для этого нам потребуется библиотека Speech Recognition:
sample = speech_r.WavFile('C:\\Users\\User\\Desktop\\1\\pythonProject\\output.wav')Непосредственно для распознавания текста нам потребуется класс Recognizer он имеет множество функций, а также определяет каким API мы будем пользоваться:
Открываем записанный файл.
Для расшифровки сигнала мы будем использовать метод recognize_google().
Для использования данного метода необходим объект AudioData и для дальнейшей работы требуется преобразовать сигнал в объект модуля Speech_recognition для этого существует метод record():
with sample as audio: content = r.record(audio)но, перед тем как передать сигнал на расшифровку, нужно очистить его от шумов. У библиотеки speech_recognition есть для этого метод adjust_for_ambient_noise()
with sample as audio: content = r.record(audio) r.adjust_for_ambient_noise(audio)Так как выбранный нами Api поддерживает русский язык мы можем им воспользоваться:
print(r.recognize_google(audio, language="ru-RU"))Распознаватель возвращает: «Привет»
Таким образом у нас получается небольшой распознаватель речи буквально в пару строк кода. В момент, когда речь прекращается он автоматически переводит ее в текст.
Далее можно приступить к получению аналитических данных с помощью библиотеки librosa. Для начала загружаем наш файл:
A_Data = 'C:\\Users\\User\\Desktop\\1\\pythonProject\\output.wav' y , sf = librosa.load(A_Data)в данном случае мы получаем значения временного ряда звука в качестве массива с частотой дискретизации.
Далее мы можем вернуть график массива нашей звуковой дорожки. Для работы с графиком импортируем pyplot из библиотеки matplotlib и используем librosa.display.waveplot() для построения графика массива:
import matplotlib.pyplot as plt import librosa.display plt.figure(figsize=(14, 5)) librosa.display.waveplot(y, sr=sf)
В самом начале я упоминал про кепстральные коэффициенты, они обычно используются для определения тембральных аспектов музыкального инструмента или голоса и мы можем построить их тепловую карту и хроматограмму.
fcc = librosa.feature.mfcc(y=y, sr=sf, hop_length=8192, n_mfcc=12) import seaborn as sns from matplotlib import pyplot as plt fcc_delta = librosa.feature.delta(fcc) sns.heatmap(fcc_delta) plt.show()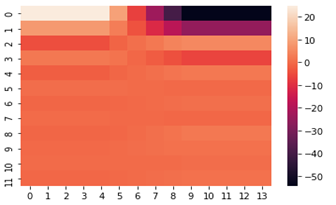
chromo = librosa.feature.chroma_cqt(y=y, sr=sf) sns.heatmap(chromo) plt.show()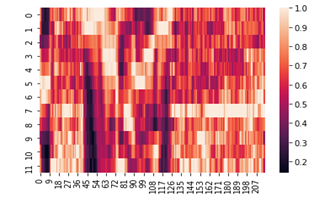
Надеюсь, что данный материал будет полезен при решении задач по распознаванию речи.