- Parsing HTML Tables in Python with pandas
- Reading excel file with pandas¶
- Parsing HTML Tables¶
- Parsing raw string¶
- Parsing a http URL¶
- Parsing HTML Tables in Python with BeautifulSoup and pandas
- Writing a Table Scraper
- Parsing a Table in BeautifulSoup
- Using Requests to Access a Web Content
- The Parser Object
- Usage Example
- Final Thoughts
Parsing HTML Tables in Python with pandas
Not long ago, I needed to parse some HTML tables from our confluence website at work. I first thought: I’m gonna need requests and BeautifulSoup. As HTML tables are well defined, I did some quick googling to see if there was some recipe or lib to parse them and I found a link to pandas. What? Can pandas do that too?
I have been using pandas for quite some time and have used read_csv, read_excel, even read_sql, but I had missed read_html!
Reading excel file with pandas¶
Before to look at HTML tables, I want to show a quick example on how to read an excel file with pandas. The API is really nice. If I have to look at some excel data, I go directly to pandas.
So let’s download a sample file file:
import io import requests import pandas as pd from zipfile import ZipFile
r = requests.get('http://www.contextures.com/SampleData.zip') ZipFile(io.BytesIO(r.content)).extractall()
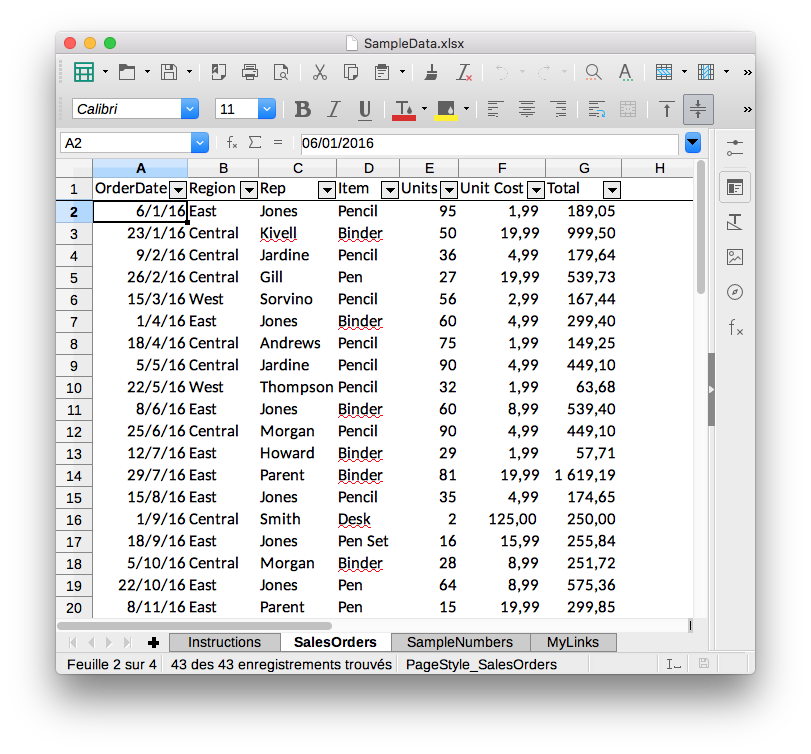
This created the SampleData.xlsx file that includes four sheets: Instructions, SalesOrders, SampleNumbers and MyLinks. Only the SalesOrders sheet includes tabular data: So let’s read it.
df = pd.read_excel('SampleData.xlsx', sheet_name='SalesOrders')
| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | |
|---|---|---|---|---|---|---|---|
| 0 | 2016-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 |
| 1 | 2016-01-23 | Central | Kivell | Binder | 50 | 19.99 | 999.50 |
| 2 | 2016-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 |
| 3 | 2016-02-26 | Central | Gill | Pen | 27 | 19.99 | 539.73 |
| 4 | 2016-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 |
That’s it. One line and you have your data in a DataFrame that you can easily manipulate, filter, convert and display in a jupyter notebook. Can it be easier than that?
Parsing HTML Tables¶
So let’s go back to HTML tables and look at pandas.read_html.
A URL, a file-like object, or a raw string containing HTML.
Let’s start with a basic HTML table in a raw string.
Parsing raw string¶
html_string = """Programming Language Creator Year C Dennis Ritchie 1972 Python Guido Van Rossum 1989 Ruby Yukihiro Matsumoto 1995 """
We can render the table using IPython display_html function:
from IPython.display import display_html display_html(html_string, raw=True)
| Programming Language | Creator | Year |
|---|---|---|
| C | Dennis Ritchie | 1972 |
| Python | Guido Van Rossum | 1989 |
| Ruby | Yukihiro Matsumoto | 1995 |
Let’s import this HTML table in a DataFrame. Note that the function read_html always returns a list of DataFrame objects:
dfs = pd.read_html(html_string) dfs
[ Programming Language Creator Year 0 C Dennis Ritchie 1972 1 Python Guido Van Rossum 1989 2 Ruby Yukihiro Matsumoto 1995]
| Programming Language | Creator | Year | |
|---|---|---|---|
| 0 | C | Dennis Ritchie | 1972 |
| 1 | Python | Guido Van Rossum | 1989 |
| 2 | Ruby | Yukihiro Matsumoto | 1995 |
This looks quite similar to the raw string we rendered above, but we are printing a pandas DataFrame object here! We can apply any operation we want.
Pandas automatically found the header to use thanks to the tag. It is not mandatory to define a table and is actually often missing on the web. So what happens if it’s not present?
html_string = """Programming Language Creator Year C Dennis Ritchie 1972 Python Guido Van Rossum 1989 Ruby Yukihiro Matsumoto 1995 """
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Programming Language | Creator | Year |
| 1 | C | Dennis Ritchie | 1972 |
| 2 | Python | Guido Van Rossum | 1989 |
| 3 | Ruby | Yukihiro Matsumoto | 1995 |
In this case, we need to pass the row number to use as header.
pd.read_html(html_string, header=0)[0]
| Programming Language | Creator | Year | |
|---|---|---|---|
| 0 | C | Dennis Ritchie | 1972 |
| 1 | Python | Guido Van Rossum | 1989 |
| 2 | Ruby | Yukihiro Matsumoto | 1995 |
Parsing a http URL¶
The same data we read in our excel file is available in a table at the following address: http://www.contextures.com/xlSampleData01.html
Let’s pass this url to read_html :
dfs = pd.read_html('http://www.contextures.com/xlSampleData01.html')
[ 0 1 2 3 4 5 6 0 OrderDate Region Rep Item Units UnitCost Total 1 1/6/2016 East Jones Pencil 95 1.99 189.05 2 1/23/2016 Central Kivell Binder 50 19.99 999.50 3 2/9/2016 Central Jardine Pencil 36 4.99 179.64 4 2/26/2016 Central Gill Pen 27 19.99 539.73 5 3/15/2016 West Sorvino Pencil 56 2.99 167.44 6 4/1/2016 East Jones Binder 60 4.99 299.40 7 4/18/2016 Central Andrews Pencil 75 1.99 149.25 8 5/5/2016 Central Jardine Pencil 90 4.99 449.10 9 5/22/2016 West Thompson Pencil 32 1.99 63.68 10 6/8/2016 East Jones Binder 60 8.99 539.40 11 6/25/2016 Central Morgan Pencil 90 4.99 449.10 12 7/12/2016 East Howard Binder 29 1.99 57.71 13 7/29/2016 East Parent Binder 81 19.99 1619.19 14 8/15/2016 East Jones Pencil 35 4.99 174.65 15 9/1/2016 Central Smith Desk 2 125.00 250.00 16 9/18/2016 East Jones Pen Set 16 15.99 255.84 17 10/5/2016 Central Morgan Binder 28 8.99 251.72 18 10/22/2016 East Jones Pen 64 8.99 575.36 19 11/8/2016 East Parent Pen 15 19.99 299.85 20 11/25/2016 Central Kivell Pen Set 96 4.99 479.04 21 12/12/2016 Central Smith Pencil 67 1.29 86.43 22 12/29/2016 East Parent Pen Set 74 15.99 1183.26 23 1/15/2017 Central Gill Binder 46 8.99 413.54 24 2/1/2017 Central Smith Binder 87 15.00 1305.00 25 2/18/2017 East Jones Binder 4 4.99 19.96 26 3/7/2017 West Sorvino Binder 7 19.99 139.93 27 3/24/2017 Central Jardine Pen Set 50 4.99 249.50 28 4/10/2017 Central Andrews Pencil 66 1.99 131.34 29 4/27/2017 East Howard Pen 96 4.99 479.04 30 5/14/2017 Central Gill Pencil 53 1.29 68.37 31 5/31/2017 Central Gill Binder 80 8.99 719.20 32 6/17/2017 Central Kivell Desk 5 125.00 625.00 33 7/4/2017 East Jones Pen Set 62 4.99 309.38 34 7/21/2017 Central Morgan Pen Set 55 12.49 686.95 35 8/7/2017 Central Kivell Pen Set 42 23.95 1005.90 36 8/24/2017 West Sorvino Desk 3 275.00 825.00 37 9/10/2017 Central Gill Pencil 7 1.29 9.03 38 9/27/2017 West Sorvino Pen 76 1.99 151.24 39 10/14/2017 West Thompson Binder 57 19.99 1139.43 40 10/31/2017 Central Andrews Pencil 14 1.29 18.06 41 11/17/2017 Central Jardine Binder 11 4.99 54.89 42 12/4/2017 Central Jardine Binder 94 19.99 1879.06 43 12/21/2017 Central Andrews Binder 28 4.99 139.72]
We have one table and can see that we need to pass the row number to use as header (because is not present).
dfs = pd.read_html('http://www.contextures.com/xlSampleData01.html', header=0) dfs[0].head()
| OrderDate | Region | Rep | Item | Units | UnitCost | Total | |
|---|---|---|---|---|---|---|---|
| 0 | 1/6/2016 | East | Jones | Pencil | 95 | 1.99 | 189.05 |
| 1 | 1/23/2016 | Central | Kivell | Binder | 50 | 19.99 | 999.50 |
| 2 | 2/9/2016 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 |
| 3 | 2/26/2016 | Central | Gill | Pen | 27 | 19.99 | 539.73 |
| 4 | 3/15/2016 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 |
Parsing HTML Tables in Python with BeautifulSoup and pandas
Something that seems daunting at first when switching from R to Python is replacing all the ready-made functions R has. For example, R has a nice CSV reader out of the box. Python users will eventually find pandas, but what about other R libraries like their HTML Table Reader from the xml package? That’s very helpful for scraping web pages, but in Python it might take a little more work. So in this post, we’re going to write a brief but robust HTML table parser.
Writing a Table Scraper
Our parser is going to be built on top of the Python package BeautifulSoup. It’s a convenient package and easy to use. Our use will focus on the “find_all” function, but before we start parsing, you need to understand the basics of HTML terminology.
An HTML object consists of a few fundamental pieces: a tag. The format that defines a tag is
and it could have attributes which consistes of a property and a value. A tag we are interested in is the table tag, which defined a table in a website. This table tag has many elements. An element is a component of the page which typically contains content. For a table in HTML, they consist of rows designated by elements within the tr tags, and then column content inside the td tags. A typical example is
It turns out that most sites keep data you’d like to scrape in tables, and so we’re going to learn to parse them.
Parsing a Table in BeautifulSoup
To parse the table, we are going to use the Python library BeautifulSoup. It constructs a tree from the HTML and gives you an API to access different elements of the webpage.
Let’s say we already have our table object returned from BeautifulSoup. To parse the table, we’d like to grab a row, take the data from its columns, and then move on to the next row ad nauseam. In the next bit of code, we define a website that is simply the HTML for a table. We load it into BeautifulSoup and parse it, returning a pandas data frame of the contents.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27import pandas as pd from bs4 import BeautifulSoup html_string = '''''' soup = BeautifulSoup(html_string, 'lxml') # Parse the HTML as a string table = soup.find_all('table')[0] # Grab the first table new_table = pd.DataFrame(columns=range(0,2), index = [0]) # I know the size row_marker = 0 for row in table.find_all('tr'): column_marker = 0 columns = row.find_all('td') for column in columns: new_table.iat[row_marker,column_marker] = column.get_text() column_marker += 1 new_table
Hello! Table As you can see, we grab all the tr elements from the table, followed by grabbing the td elements one at a time. We use the “get_text()” method from the td element (called a column in each iteration) and put it into our python object representing a table (it will eventually be a pandas dataframe).
Using Requests to Access a Web Content
Now, that we have our plan to parse a table, we probably need to figure out how to get to that point. That’s actually easier! We’re going to use the requests package in Python.
import requests url = "https://www.fantasypros.com/nfl/reports/leaders/qb.php?year=2015" response = requests.get(url) response.text[:100] # Access the HTML with the text property'\r\n \n lang="en">\n\n \n Fantasy Football Leaders Weeks 1 to 17 - QB'The Parser Object
So, now we can define our HTML table parser object. You’ll notice we added more bells and whistles to the html table parser. To summarize the functionality outside of basic parsing:
1. We take th elements and use them as column names. 2. We cast any column with numbers to float. 3. We also return a list of tuples for each table in the page.The tuples we return are in the form (table id, parsed table) for every table in the document.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60import requests import pandas as pd from bs4 import BeautifulSoup class HTMLTableParser: def parse_url(self, url): response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') return [(table['id'],self.parse_html_table(table))\ for table in soup.find_all('table')] def parse_html_table(self, table): n_columns = 0 n_rows=0 column_names = [] # Find number of rows and columns # we also find the column titles if we can for row in table.find_all('tr'): # Determine the number of rows in the table td_tags = row.find_all('td') if len(td_tags) > 0: n_rows+=1 if n_columns == 0: # Set the number of columns for our table n_columns = len(td_tags) # Handle column names if we find them th_tags = row.find_all('th') if len(th_tags) > 0 and len(column_names) == 0: for th in th_tags: column_names.append(th.get_text()) # Safeguard on Column Titles if len(column_names) > 0 and len(column_names) != n_columns: raise Exception("Column titles do not match the number of columns") columns = column_names if len(column_names) > 0 else range(0,n_columns) df = pd.DataFrame(columns = columns, index= range(0,n_rows)) row_marker = 0 for row in table.find_all('tr'): column_marker = 0 columns = row.find_all('td') for column in columns: df.iat[row_marker,column_marker] = column.get_text() column_marker += 1 if len(columns) > 0: row_marker += 1 # Convert to float if possible for col in df: try: df[col] = df[col].astype(float) except ValueError: pass return dfUsage Example
Let’s do an example where we scrape a table from a website. We initialize the parser object and grab the table using our code above:
hp = HTMLTableParser() table = hp.parse_url(url)[0][1] # Grabbing the table from the tuple table.head()
| Rank | Player | Team | Points | Games | Avg | |
|---|---|---|---|---|---|---|
| 0 | 1 | Cam Newton | CAR | 389.1 | 16 | 24.3 |
| 1 | 2 | Tom Brady | NE | 343.7 | 16 | 21.5 |
| 2 | 3 | Russell Wilson | SEA | 336.4 | 16 | 21.0 |
| 3 | 4 | Blake Bortles | JAC | 316.1 | 16 | 19.8 |
| 4 | 5 | Carson Palmer | ARI | 309.2 | 16 | 19.3 |
If you had looked at the URL above, you’d have seen that we were parsing QB stats from the 2015 season off of FantasyPros.com. Our data has been prepared in such a way that we can immediately start an analysis.
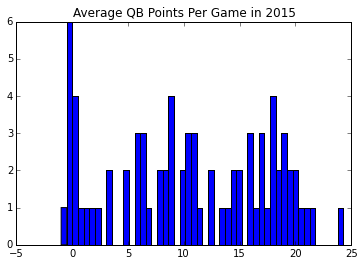
%matplotlib inline import matplotlib.pyplot as plt plt.figure() avg=table['Avg'].values plt.hist(avg, bins = 50) plt.title('Average QB Points Per Game in 2015')
Final Thoughts
As you can see, this code may find it’s way into some scraper scripts once Football season starts again, but it’s perfectly capable of scraping any page with an HTML table. The code actually will scrape every table on a page, and you can just select the one you want from the resulting list. Happy scraping!