- Saved searches
- Use saved searches to filter your results more quickly
- License
- iamjeffx/Snake-Q-Learning
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- About
- Как я учил змейку играть в себя с помощью Q-Network
- Обучение с подкреплением
- DQN
- Реализация змейки
- Состояние
- Награда
- Итог
- Saved searches
- Use saved searches to filter your results more quickly
- License
- kingyiusuen/snake
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Q-learning algorithm that trains a model to play snake. Uses a pre-made snake game file in a repository linked here.
License
iamjeffx/Snake-Q-Learning
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Q-learning algorithm that trains a model to play snake. Uses a pre-made snake game file in a repository linked here.
Q-learning is an algorithm based on the ideas of a Markovian-Decision-Process which derives from a simple Markov chain. Basically, the client has many states and each state has multiple actions that the client can take to get to another state. This model can be represented by a finite automata, where the nodes represent states and the directed-weighted edges represent actions.
The Q-Score is way of numerically representing how well the client is doing in the game and the idea is to take actions that have an optimized Q-Score. This application uses the Bellman equation of learning:

Clone the git repository to your local machine.
git clone https://github.com/iamjeffx/Snake-Q-Learning.git
To run the game, simply execute the driver.
For the Q-learning driver, run the training model.
Hyperparameters are adjustable at the top of the training model driver. Learning rate, discount rate and max iterations per game during training are labelled at the top. Rewards for each policy is at the very top of the training model. Snake block size and the size of the board can also be adjusted; Board dimension(supports square boards) is equal to canvas width/height minus double the canvas buffer all divided by the snake block size. Default values for the buffer and block size are 50 and 25 respectively.
About
Q-learning algorithm that trains a model to play snake. Uses a pre-made snake game file in a repository linked here.
Как я учил змейку играть в себя с помощью Q-Network
Однажды, исследуя глубины интернета, я наткнулся на видео, где человек обучает змейку с помощью генетического алгоритма. И мне захотелось так же. Но просто взять все то же самое и написать на python было бы не интересно. И я решил использовать более современный подход для обучения агентных систем, а именно Q-network. Но начнем с начала.
Обучение с подкреплением
В машинном обучении RL(Reinforcement Learning) достаточно сильно отличается от других направлений. Отличие состоит в том, что классический ML алгоритм обучается уже на готовых данных, в то время как RL, так сказать, сам создает себе эти данные. Идея RL состоит в том, что помимо самого алгоритма, который называют агентом, существует среда(environment), в которую этот агент и помещается. На каждом этапе агент должен совершать какое-то действие(action), а среда отвечает на это наградой(reward) и своим состоянием(state), на основе которого агент и совершает действие.
DQN
Здесь должно быть объяснение того, как алгоритм работает, но я оставлю ссылку на то, где это объясняют умные люди.
Реализация змейки
После того, как мы разобрались c rl, надо создать среду, в которую будем помещать агента. К счастью, изобретать велосипед не требуется, тк такая компания как open-ai уже написала библиотеку gym, с помощью которой можно писать свои энвайронменты. В библиотеке их уже имеется в большом количестве. От простых atari игр до сложных 3d моделей. Но среди всего этого нет змейки. Поэтому приступим к ее созданию.
Я не буду описывать все моменты создания энвайронмента в gym, а покажу только основной класс, в котором требуется реализовать несколько функций.
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """Функции подается выбранное агентом действие. Возвращает состояние после действия, награду и информацию об окончании эпизода""" def reset(self): """Сбрасывает среду к стартовому состоянию и возвращает стартовое состояние""" def render(self, mode='human'): """Рендерит среду"""Но для реализации этих функций надо придумать систему наград и в каком виде мы будем отдавать информацию о среде.
Состояние
В видео человек подавал змейке расстояние до стены, змейки и яблока в 8 направлениях. Те 24 числа. Я же решил уменьшить количество данных, но немного усложнить их. Во первых, я совмещу расстояние до стен с расстоянием до змейки. Проще говоря будем говорить ей расстояние до ближайшего объекта, который может убить при столкновении. Во вторых, направлений будет всего 3 и они будут зависеть от направления движения змейки. Например при старте змейка смотрит вверх, значит мы сообщим ей расстояние до верхней, левой и правой стенки. Но когда голова змейки повернется направо, то мы уже будем сообщать расстояние до правой, верхней и нижней стенки. Для пущей простоты приведу картинку.

С яблоком я тоже решил поиграться. Информацию о нем мы будем представлять в виде (x,y) координаты в системе координат, которая берет начало у головы змейки. Система координат также будет менять свою ориентацию за головой змейки. После картинки, думаю, точно должно стать понятно.
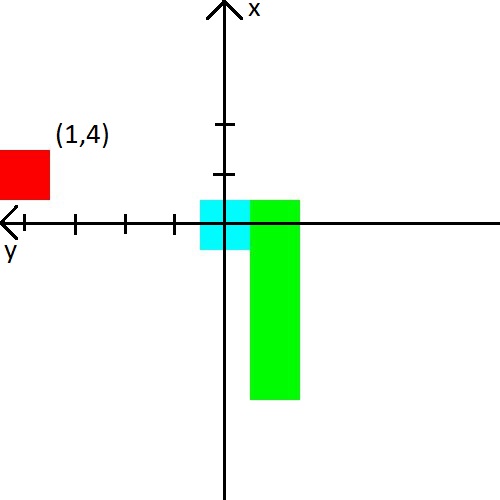
Награда
Если с состоянием можно придумать какие-то фичи и понадеяться, что нейросеть разберется, то с наградой все сложнее. От нее зависит будет ли агент учиться и будет ли он учиться тому, чего мы хотим.
Я сразу приведу систему награды, с которой я добился стабильного обучения.
- При каждом шаге награда равна -0.25.
- При смерти -10.
- При смерти до 15 шагов -100.
- При съедании яблока sqrt(количество съеденных яблок) * 3.5.
А так же приведу примеры к чему приводит плохая система наград.
- Если давать не достаточно маленькую награду за смерть в первые несколько шагов, то змейка предпочтет убиваться об стенку. Ведь так проще, чем искать яблоки 🙂
- Если давать положительную награду за шаги, то змейка начнет бесконечно крутиться. Потому что по ее мнению это будет выгоднее, чем искать яблоки.
- И множество других случаев, когда змейка просто не будет учиться.
Итог
Основным интересом при написании змейки было увидеть, как змейка обучится зная так мало о своей среде. И обучилась она неплохо, тк средний показатель съеденных яблок достиг 23, что, мне кажется, очень не дурно. Поэтому эксперимент можно считать удачным.
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Teach an AI to play snake using Q-learning
License
kingyiusuen/snake
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Playing Snake with Reinforcement Learning
A snake game controlled by an AI agent.
The game is developed using pygame. The goal for the snake is to eat as much as food as possible before it eats itself or hits one of the four borders. The agent is able to score over 50 after 500 episodes of training (which takes less than 15 seconds).
The agent is trained using the Q-learning algorithm. The agent receives a reward of +50 when the the food is eaten, and a penalty of -30 when the snake eats itself or hits a wall. To discourage any redundant step, the agent receives a penalty of -1 for each step it has taken.
A navie state space would use the exact positions of the snake and food. In an n^2 board, each square has four possible conditions: empty, occupied by the food, occupied by the head of the snake, or occupied by the body of the snake. In this approach, the number of possible states is (n^2)^4, which makes training difficult. The state space used in this algorithm only considers
- whether the snake is going to hit an object (food, snake’s body, or a wall) if it goes straight, left and right, and
- whether the food is in front of/behind the snake and to the left/right of the snake.
The size of the state space is, therefore, reduced to 3^3 x 2^2. However, since the agent can only read one step ahead, it does have a tendency to trap itself into a location where it doesn’t have sufficient space to get itself out.
$ git clone https://github.com/kingyiusuen/snake.git
To run the game, type the following command in the terminal:
$ python play.py --display --retrain --num_episodes=500
—display: (Optional) display the game view or not
—retrain: (Optional) retrain the agent from scratch or continue training the policy stored in q.pickle
—num_episodes: (Optional) number of episodes to run in this training session (default=500)
Turning off the game display will speed up the training. The action-value function after 500 episodes of training is stored in q.pickle . The file will automatically be loaded when the script is run, and the training will continue. If you want to re-train the agent, simply add the —retrain argument.
The Stanford students who developed this project — For the idea of using the relative position of the food, instead of the exact position.