Как ускорить код на Python в тысячу раз

В любых соревнованиях по скорости выполнения программ Python обычно занимает последние места. Кто-то говорит, что это из-за того, что Python является интерпретируемым языком. Все интерпретируемые языки медленные. Но мы знаем, что Java тоже язык такого типа, её байткод интерпретируется JVM. Как показано, в этом бенчмарке, Java намного быстрее, чем Python.
Вот пример, способный показать медленность Python. Используем традиционный цикл for для получения обратных величин:
import numpy as np np.random.seed(0) values = np.random.randint(1, 100, size=1000000) def get_reciprocal(values): output = np.empty(len(values)) for i in range(len(values)): output[i] = 1.0/values[i] %timeit get_reciprocal(values)Ничего себе, на вычисление всего 1 000 000 обратных величин требуется 3,37 с. Та же логика на C выполняется за считанные мгновения: 9 мс; C# требуется 19 мс; Nodejs требуется 26 мс; Java требуется 5 мс(!), а Python требуется аж целых 3,37 СЕКУНДЫ. (Весь код тестов приведён в конце).
Первопричина такой медленности
Обычно мы называем Python языком программирования с динамической типизацией. В программе на Python всё представляет собой объекты; иными словами, каждый раз, когда код на Python обрабатывает данные, ему нужно распаковывать обёртку объекта. Внутри цикла for каждой итерации требуется распаковывать объекты, проверять тип и вычислять обратную величину. Все эти 3 секунды тратятся на проверку типов.
В отличие от традиционных языков наподобие C, где доступ к данным осуществляется напрямую, в Python множество тактов ЦП используется для проверки типа.

Даже простое присвоение числового значения — это долгий процесс.
Шаг 1. Задаём a->PyObject_HEAD->typecode тип integer
Подробнее о том, почему Python медленный, стоит прочитать в чудесной статье Джейка: Why Python is Slow: Looking Under the Hood
Итак, существует ли способ, позволяющий обойти проверку типов, а значит, и повысить производительность?
Решение: универсальные функции NumPy
В отличие list языка Python, массив NumPy — это объект, созданный на основе массива C. Доступ к элементу в NumPy не требует шагов для проверки типов. Это даёт нам намёк на решение, а именно на Universal Functions (универсальные функции) NumPy, или UFunc.

Если вкратце, благодаря UFunc мы можем проделывать арифметические операции непосредственно с целым массивом. Перепишем первый медленный пример на Python в версию на UFunc, она будет выглядеть так:
import numpy as np np.random.seed(0) values = np.random.randint(1, 100, size=1000000) %timeit result = 1.0/valuesЭто преобразование не только повышает скорость, но и укорачивает код. Отгадаете, сколько теперь времени занимает его выполнение? 2,7 мс — быстрее, чем все упомянутые выше языки:
2,71 мс ± 50,8 мкс на цикл (среднее значение ± стандартное отклонение после =7 прогонов по 100 циклов каждый)
Вернёмся к коду: самое важное здесь — это 1.0/values . values — это не число, а массив NumPy. Наряду с оператором деления есть множество других.
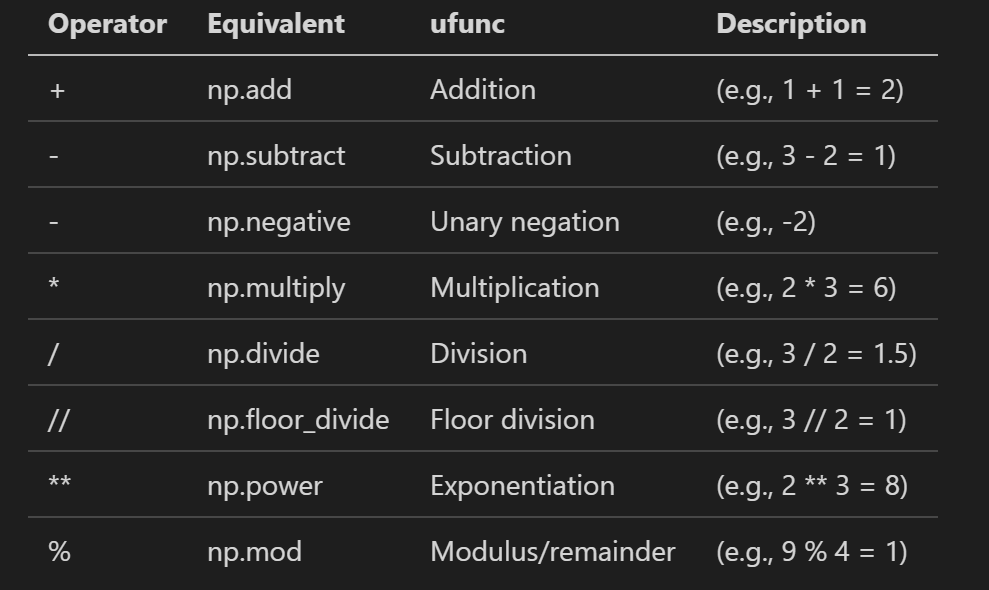
Здесь можно найти все операторы Ufunc.
Подводим итог
Если вы пользуетесь Python, то высока вероятность того, что вы работаете с данными и числами. Эти данные можно хранить в NumPy или DataFrame библиотеки Pandas, поскольку DataFrame реализован на основе NumPy. То есть с ним тоже работает Ufunc.
UFunc позволяет нам выполнять в Python повторяющиеся операции быстрее на порядки величин. Самый медленный Python может быть даже быстрее языка C. И это здорово.
Приложение — код тестов на C, C#, Java и NodeJS
#include #include #include int main() < struct timeval stop, start; int length = 1000000; int rand_array[length]; float output_array[length]; for(int i = 0; igettimeofday(&start, NULL); for(int i = 0; i gettimeofday(&stop, NULL); printf("took %lu us\n", (stop.tv_sec - start.tv_sec) * 1000000 + stop.tv_usec - start.tv_usec); printf("done\n"); return 0; >using System; namespace speed_test < class Program< static void Main(string[] args)< int length = 1000000; double[] rand_array =new double[length]; double[] output = new double[length]; var rand = new Random(); for(int i =0; ilong start = DateTimeOffset.Now.ToUnixTimeMilliseconds(); for(int i =0;i long end = DateTimeOffset.Now.ToUnixTimeMilliseconds(); Console.WriteLine(end - start); > > > import java.util.Random; public class speed_test < public static void main(String[] args)< int length = 1000000; long[] rand_array = new long[length]; double[] output = new double[length]; Random rand = new Random (); for(int i =0; ilong start = System.currentTimeMillis(); for(int i = 0;i long end = System.currentTimeMillis(); System.out.println(end - start); > >let length = 1000000; let rand_array = []; let output = []; for(var i=0;i let start = (new Date()).getMilliseconds(); for(var i=0;i let end = (new Date()).getMilliseconds(); console.log(end - start); На правах рекламы
Воплощайте любые идеи и проекты с помощью наших VDS с мгновенной активацией на Linux или Windows. Создавайте собственный конфиг в течение минуты!

Ускорение кода на Python средствами самого языка

Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и на Хабре.
- Использовать Psyco
- Переписать часть программы на С используя Python C Extensions
- Сменить
мозгиалгоритм
- «Порог вхождения» у C и Python/C API все же выше, чем у «голого» Python’a, что отсекает эту возможность для разработчиков, не знакомых с C
- Одной из ключевых особенностей Python является скорость разработки. Написание части программы на Си снижает ее, пропорционально части переписанного в Си кода к всей программе
Так что же делать?
Тогда, если для вашего проекта выше перечисленные методы не подошли, что делать? Менять Python на другой язык? Нет, сдаваться нельзя. Будем оптимизировать сам код. Примеры будут взяты из программы, строящей множество Мандельброта заданного размера с заданным числом итераций.
Время работы исходной версии при параметрах 600*600 пикселей, 100 итераций составляло 3.07 сек, эту величину мы возьмем за 100%
Скажу заранее, часть оптимизаций приведет к тому, что код станет менее pythonic, да простят меня адепты python-way.
Шаг 0. Вынос основного кода программы в отдельную
Данный шаг помогает интерпретатору python лучше проводить внутренние оптимизации про запуске, да и при использовании psyco данный шаг может сильно помочь, т.к. psyco оптимизирует лишь функции, не затрагивая основное тело программы.
Если раньше рассчетная часть исходной программы выглядела так:
for Y in xrange(height): for X in xrange(width): #проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций def mandelbrot(height, itt, width): for Y in xrange(height): for X in xrange(width): #проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций mandelbrot(height, itt, width) мы получили время 2.4 сек, т.е. 78% от исходного.
Шаг 1. Профилирование
Стандартная библиотека Python’a, это просто клондайк полезнейших модулей. Сейчас нас интересует модуль cProfile, благодаря которому, профилирование кода становится простым и, даже, интересным занятием.
Полную документацию по этому модулю можно найти здесь, нам же хватит пары простых команд.
python -m cProfile sample.py
Ключ интерпетатора -m позволяет запускать модули как отдельные программы, если сам модуль предоставляет такую возможность.
Результатом этой команды будет получение «профиля» программы — таблицы, вида
4613944 function calls (4613943 primitive calls) in 2.818 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
.
С её помощью, легко определить места, требующие оптимизации (строки с наибольшими значениями ncalls (кол-во вызовов функции), tottime и percall (время работы всех вызовов данной функции и каждого отдельного соответственно)).
Для удобства можно добавить ключ -s time , отсортировав вывод профилировщика по времени выполнения.
В моем случае интересной частью вывода было (время выполнение отличается от указанного выше, т.к. профилировщик добавляет свой «оверхед»):
4613944 function calls (4613943 primitive calls) in 2.818 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
3533224 0.296 0.000 0.296 0.000
360000 0.081 0.000 0.081 0.000
360000 0.044 0.000 0.044 0.000
360000 0.036 0.000 0.036 0.000
.
Итак, профиль получен, теперь займемся оптимизацией вплотную.
Шаг 2. Анализ профиля
Видим, что на первом месте по времени стоит наша основная функция mandelbrot, за ней идет системная функция abs, за ней несколько функций из модуля math, далее — одиночные вызовы функций, с минимальными временными затратами, они нам не интересны.
Итак, системные функции, «вылизаные» сообществом, нам врядли удастся улучшить, так что перейдем к нашему собственному коду:
Шаг 3. Математика
pix = img.load() #загрузим массив пикселей def mandelbrot(height, itt, width): step_x = (2 - width / 1.29) / (width / 2.6) - (1 - width / 1.29) / (width / 2.6) #шаг по оси х for Y in xrange(height): y = (Y - height / 2) / (width / 2.6) #для Y рассчет шага не так критичен как для Х, его отсутствие положительно повлияет на точность x = - (width / 1.29) / (width / 2.6) for X in xrange(width): x += step_x z = complex(x, y) phi = math.atan2(y, x - 0.25) p = math.sqrt((x - 0.25) ** 2 + y ** 2) pc = 0.5 - 0.5 * math.cos(phi) if p 2: color = (i * 255) // itt pix[X, Y] = (color, color, color) break else: pix[X, Y] = (255, 255, 255) print("\r%d/%d" % (Y, height)), Заметим, что оператор возведения в степень ** — довольно «общий», нам же необходимо лишь возведение во вторую степень, т.е. все конструкции вида x**2 можно заменить на х*х, выиграв таким образом еще немного времени. Посмотрим на время:
1.9 сек, или 62% изначального времени, достигнуто простой заменой двух строк:
p = math.sqrt((x - 0.25) ** 2 + y ** 2) . Z_i = Z_i **2 + z p = math.sqrt((x - 0.25) * (x - 0.25) + y * y) . Z_i = Z_i * Z_i + z Шажки 5, 6 и 7. Маленькие, но важные
Прописная истина, о которой знают все программисты на Python — работа с глобальными переменными медленней работы с локальными. Но часто забывается факт, что это верно не только для переменных но и вообще для всех объектов. В коде функции идут вызовы нескольких функций из модуля math. Так почему бы не импортировать их в самой функции? Сделано:
def mandelbrot(height, itt, width): from math import atan2, cos, sqrt pix = img.load() #загрузим массив пикселей Еще 0.1сек отвоевано.
Вспомним, что abs(x) вернет число типа float. Так что и сравнивать его стоит с float а не int:
if abs(Z_i) > 2: ------> if abs(Z_i) > 2.0: Еще 0.15сек. 53% от начального времени.
И, наконец, грязный хак.
В конкретно этой задаче, можно понять, что нижняя половина изображения, равна верхней, т.о. число вычислений можно сократить вдвое, получив в итоге 0.84сек или 27% от исходного времени.
Заключение
Профилируйте. Используйте timeit. Оптимизируйте. Python — мощный язык, и программы на нем будут работать со скоростью, пропорциональной вашему желанию разобраться и все отполировать:)
Цель данной статьи, показать, что за счет мелких и незначительных изменения, таких как замен ** на *, можно заставить зеленого змея ползать до двух раз быстрее, без применения тяжелой артиллерии в виде Си, или шаманств psyco.
Также, можно совместить разные средства, такие как вышеуказанные оптимизации и модуль psyco, хуже не станет:)
Спасибо всем кто дочитал до конца, буду рад выслушать ваши мнения и замечания в комментариях!
UPD Полезную ссылку в коментариях привел funca.