- Extract a substring from a string in Python (position, regex)
- Extract a substring by specifying the position and number of characters
- Extract a character by index
- Extract a substring by slicing
- Extract based on the number of characters
- Extract a substring with regular expressions: re.search() , re.findall()
- Regex pattern examples
- Wildcard-like patterns
- Greedy and non-greedy
- Extract part of the pattern with parentheses
- Match any single character
- Match the start/end of the string
- Extract by multiple patterns
- Case-insensitive
- Python Extract Substring Using Regex
- Method 1: Python Extract Substring Using Regex in “re.search()” Method
- Syntax
- Example 1: Extracting Text-based Substring Using “re.search()” Method
- Example 2: Extracting Numeric Substring Using “re.search()” Method
- Method 2: Python Extract Substring Using Regex in “re.match()” Method
- Syntax
- Example
- Output
- Method 3: Python Extract Substring Using Regex in “re.findall()” Method
- Syntax
- Example
- Output
- Method 4: Python Extract Substring Using Regex in “re.finditer()” Method
- Syntax
- Example
- Output
- Conclusion
- About the author
- Abdul Mannan
Extract a substring from a string in Python (position, regex)
This article explains how to extract a substring from a string in Python. You can extract a substring by specifying its position and length, or by using regular expression patterns.
- Extract a substring by specifying the position and number of characters
- Extract a character by index
- Extract a substring by slicing
- Extract based on the number of characters
- Wildcard-like patterns
- Greedy and non-greedy
- Extract part of the pattern with parentheses
- Match any single character
- Match the start/end of the string
- Extract by multiple patterns
- Case-insensitive
To search a string to get the position of a given substring or replace a substring in a string with another string, see the following articles.
If you want to extract from a text file, read the file as a string.
Extract a substring by specifying the position and number of characters
Extract a character by index
You can get a character at the desired position by specifying an index in [] . Indexes start at 0 (zero-based indexing).
s = 'abcde' print(s[0]) # a print(s[4]) # eYou can specify a backward position with negative values. -1 represents the last character.
An error is raised if the non-existent index is specified.
# print(s[5]) # IndexError: string index out of range # print(s[-6]) # IndexError: string index out of rangeExtract a substring by slicing
s = 'abcde' print(s[1:3]) # bc print(s[:3]) # abc print(s[1:]) # bcdeYou can also use negative values.
print(s[-4:-2]) # bc print(s[:-2]) # abc print(s[-4:]) # bcdeIf start > end , no error is raised, and an empty string » is extracted.
print(s[3:1]) # print(s[3:1] == '') # TrueOut-of-range values are ignored.
In addition to the start position start and end position stop , you can also specify an increment step using the syntax [start:stop:step] . If step is negative, the substring will be extracted in reverse order.
print(s[1:4:2]) # bd print(s[::2]) # ace print(s[::3]) # ad print(s[::-1]) # edcba print(s[::-2]) # ecaFor more information on slicing, see the following article.
Extract based on the number of characters
The built-in function len() returns the number of characters in a string. You can use this to get the central character or extract the first or second half of the string using slicing.
Note that you can specify only integer int values for index [] and slice [:] . Division by / raises an error because the result is a floating-point number float .
The following example uses integer division // which truncates the decimal part of the result.
s = 'abcdefghi' print(len(s)) # 9 # print(s[len(s) / 2]) # TypeError: string indices must be integers print(s[len(s) // 2]) # e print(s[:len(s) // 2]) # abcd print(s[len(s) // 2:]) # efghiExtract a substring with regular expressions: re.search() , re.findall()
You can use regular expressions with the re module of the standard library.
Use re.search() to extract a substring matching a regular expression pattern. Specify the regular expression pattern as the first parameter and the target string as the second parameter.
import re s = '012-3456-7890' print(re.search(r'\d+', s)) #In regular expressions, \d matches a digit character, while + matches one or more repetitions of the preceding pattern. Therefore, \d+ matches one or more consecutive digits.
Since backslash \ is used in regular expression special sequences such as \d , it is convenient to use a raw string by adding r before » or «» .
When a string matches the pattern, re.search() returns a match object. You can get the matched part as a string str by the group() method of the match object.
m = re.search(r'\d+', s) print(m.group()) # 012 print(type(m.group())) #For more information on regular expression match objects, see the following article.
As shown in the example above, re.search() returns the match object for the first occurrence only, even if there are multiple matching parts in the string.
re.findall() returns a list of all matching substrings.
print(re.findall(r'\d+', s)) # ['012', '3456', '7890']Regex pattern examples
This section provides examples of regular expression patterns using metacharacters and special sequences.
Wildcard-like patterns
. matches any single character except a newline, and * matches zero or more repetitions of the preceding pattern.
For example, a.*b matches the string starting with a and ending with b . Since * matches zero repetitions, it also matches ab .
print(re.findall('a.*b', 'axyzb')) # ['axyzb'] print(re.findall('a.*b', 'a---b')) # ['a---b'] print(re.findall('a.*b', 'aあいうえおb')) # ['aあいうえおb'] print(re.findall('a.*b', 'ab')) # ['ab']+ matches one or more repetitions of the preceding pattern. a.+b does not match ab .
print(re.findall('a.+b', 'ab')) # [] print(re.findall('a.+b', 'axb')) # ['axb'] print(re.findall('a.+b', 'axxxxxxb')) # ['axxxxxxb']? matches zero or one preceding pattern. In the case of a.?b , it matches ab and the string with only one character between a and b .
print(re.findall('a.?b', 'ab')) # ['ab'] print(re.findall('a.?b', 'axb')) # ['axb'] print(re.findall('a.?b', 'axxb')) # []Greedy and non-greedy
* , + , and ? are greedy matches, matching as much text as possible. In contrast, *? , +? , and ?? are non-greedy, minimal matches, matching as few characters as possible.
s = 'axb-axxxxxxb' print(re.findall('a.*b', s)) # ['axb-axxxxxxb'] print(re.findall('a.*?b', s)) # ['axb', 'axxxxxxb']Extract part of the pattern with parentheses
If you enclose part of a regular expression pattern in parentheses () , you can extract a substring in that part.
print(re.findall('a(.*)b', 'axyzb')) # ['xyz']If you want to match parentheses () as characters, escape them with backslash \ .
print(re.findall(r'\(.+\)', 'abc(def)ghi')) # ['(def)'] print(re.findall(r'\((.+)\)', 'abc(def)ghi')) # ['def']Match any single character
Using square brackets [] in a pattern matches any single character from the enclosed string.
Using a hyphen — between consecutive Unicode code points, like [a-z] , creates a character range. For example, [a-z] matches any single lowercase alphabetical character.
print(re.findall('[abc]x', 'ax-bx-cx')) # ['ax', 'bx', 'cx'] print(re.findall('[abc]+', 'abc-aaa-cba')) # ['abc', 'aaa', 'cba'] print(re.findall('[a-z]+', 'abc-xyz')) # ['abc', 'xyz']Match the start/end of the string
^ matches the start of the string, and $ matches the end of the string.
s = 'abc-def-ghi' print(re.findall('[a-z]+', s)) # ['abc', 'def', 'ghi'] print(re.findall('^[a-z]+', s)) # ['abc'] print(re.findall('[a-z]+$', s)) # ['ghi']Extract by multiple patterns
Use | to match a substring that conforms to any of the specified patterns. For example, to match substrings that follow either pattern A or pattern B , use A|B .
s = 'axxxb-012' print(re.findall('a.*b', s)) # ['axxxb'] print(re.findall(r'\d+', s)) # ['012'] print(re.findall(r'a.*b|\d+', s)) # ['axxxb', '012']Case-insensitive
The re module is case-sensitive by default. Set the flags argument to re.IGNORECASE to perform case-insensitive.
s = 'abc-Abc-ABC' print(re.findall('[a-z]+', s)) # ['abc', 'bc'] print(re.findall('[A-Z]+', s)) # ['A', 'ABC'] print(re.findall('[a-z]+', s, flags=re.IGNORECASE)) # ['abc', 'Abc', 'ABC']Python Extract Substring Using Regex

There can be several case scenarios where it is required to extract a substring from a string in Python. For instance, while working on large datasets, you may need to get specific data from the text fields or match a particular pattern in a string, such as an email address or phone number. Moreover, the substring extraction operation also assists in text processing and analysis.
This post will cover the following approaches:
Method 1: Python Extract Substring Using Regex in “re.search()” Method
The Python “re.search()” method looks for the first occurrence of the instance of the added pattern within a string and outputs a “Match” object. It can be invoked when you want to locate a specific substring inside a longer string but have no idea how frequently it occurs.
Syntax
To use the re.search() method, follow the given syntax:
- “pattern” represents the regex that you want to search.
- “string” refers to the specified string in which you want to search.
- “flags” represents the optional parameters, such as multi-line mode, case sensitivity, etc.
Example 1: Extracting Text-based Substring Using “re.search()” Method
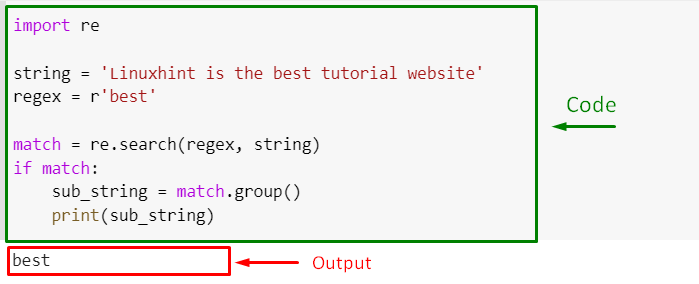
For utilizing the “re.search()” method to extract a substring, firstly import the “re” module. This module offers support for regex:
Define the string from which you want to retrieve a substring:
Then, specify the regex. Here, “r” indicates that it is a raw string to treat backlashes as the literal characters, and “best” is the defined regular expression or regex:
Pass the created “regex” and “string” to the re.search() method and store the resultant object in the “match”:
Now, add the given condition to extracts the matched substring from the “match” object returned by the re.search() method, and display it to the console:
It can be observed that the substring “best” has been extracted by utilizing the “group()” method of the match object:
Example 2: Extracting Numeric Substring Using “re.search()” Method
Now, define a numeric string and search for the first occurrence of one or more digits in it by passing the “\d+” as the regex to “re.search()” method:
- “\” is utilized for escaping the letter “d” (digit character).
- “+” signifies one or match digits in a row:
As you can see, the matched object has been returned by the “re.search()” method.
Method 2: Python Extract Substring Using Regex in “re.match()” Method
“re.match()” only searches for the regex at the start of the strings and outputs a Match object in case of a successful search. This method can be utilized when you know that the substring only occurs at the start of the given string.
Syntax
To invoke the re.match() method, follow the given syntax:
Example
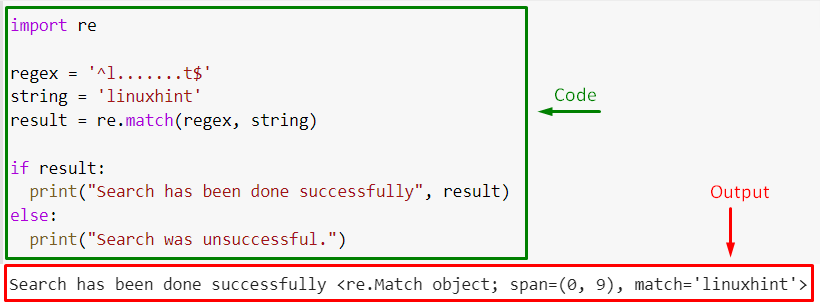
Firstly, define the regular expression as “‘^l…….t$‘”. This regex matches the strings that begin with “l”, end with “t”, and have exactly 8 characters.
Then, declare the string. Pass it to the re.match() method, along with the regex as arguments:
Add the “if-else” condition and specify the respective print statements for the cases if “Match” object has been returned or not:
if result:
print ( «Search has been done successfully» , result )
else :
print ( «Search was unsuccessful.» )Output
Method 3: Python Extract Substring Using Regex in “re.findall()” Method
The “re.findall()” Python method searches for every instance of a pattern within the given strings and outputs a list of extracted substrings. This method is used in those case scenarios where it is required to retrieve multiple substrings without any particular order.
Syntax
To invoke the re.findall() method, check out the given syntax:
Example
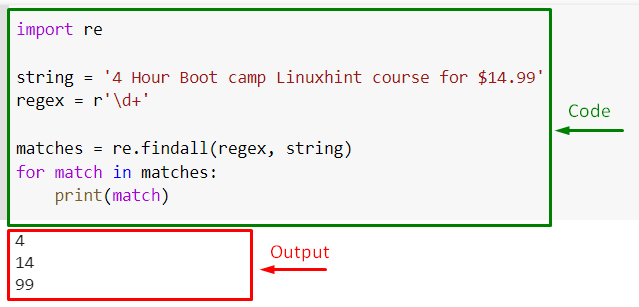
Define a string comprising numeric values. Then, specify the regex pattern as “r’\d+‘” to match one or more digits:
Then, call the “re.findall()” method and pass the defined regex and the string as arguments
Now, iterate over the returned “Match” object stored in the matches variable and print the elements on the console:
Output
Method 4: Python Extract Substring Using Regex in “re.finditer()” Method
The “re.finditer()” method works the same as the re.findall() method. However, it returns an iterator rather than a list of substrings. In Python, this method can be utilized when there exists a large data set and it does not need to store all matches at once. More specifically, the re.finditer() method processes the extracted substring one at a time.
Syntax
To invoke the re.finditer() method, follow the given syntax:
Example
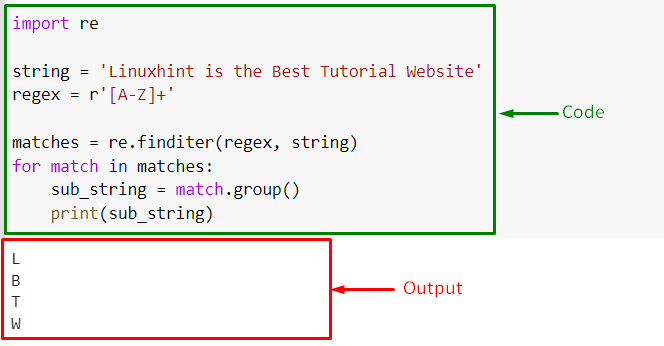
First, create a string. Then, define a regex pattern as “r'[A-Z]+’” that matches one or more uppercase letters:
Pass the regex and the string as arguments to the “re.finditer()” method and store the resultant Match object in “matches”:
Lastly, iterate over the matches object elements, extract the substring with the help of the “group()” method and print out on the console:
Output
We have compiled essential approaches related to extracting substring in Python.
Conclusion
To extract substring using regex in Python, use the “re.search()”, “re.match()”, “re.findall()”, or the “re.finditer()” methods. Depending on your requirements, utilize “re.search()” method when it is required to extract only the first instance of the regex, “re.match()” extracts the substring present the start of a string, “re.findall()” retrieves multiple substrings according to the pattern, and lastly “re.finditer()” process the multiple strings one at a time. This blog covered the methods for extracting substring in Python.
About the author
Abdul Mannan
I am curious about technology and writing and exploring it is my passion. I am interested in learning new skills and improving my knowledge and I hold a bachelor’s degree in computer science.