Урок 4
Работа со строками
Учимся выполнять основные действия над строковым типом данных в Python: создание, экранирование, конкатенация и умножение, срезы, форматирование, строковые методы.

Курс «Программирование на Python»
Учимся выполнять основные действия над строковым типом данных в Python: создание, экранирование, конкатенация и умножение, срезы, форматирование, строковые методы.

Строки в Python — упорядоченные неизменяемые последовательности символов, используемые для хранения и представления текстовой информации, поэтому с помощью строк можно работать со всем, что может быть представлено в текстовой форме.
Последовательности в Python
Последовательность(Sequence Type) — итерируемый контейнер, к элементам которого есть эффективный доступ с использованием целочисленных индексов.
Последовательности могут быть как изменяемыми, так и неизменяемыми. Размерность и состав созданной однажды неизменяемой последовательности не может меняться, вместо этого обычно создаётся новая последовательность.
- Список (list) — изменяемая
- Кортеж (tuple) — неизменяемая
- Диапазон (range) — неизменяемая
- Строка (str, unicode) — неизменяемая
Строки можно создать несколькими способами:
1. С помощью одинарных и двойных кавычек.
Например:
first_string = 'Я текст в одинарных кавычках' second_string = "Я текст в двойных кавычках" Строки в одинарных и двойных кавычках — одно и то же. Причина наличия двух вариантов в том, чтобы позволить вставлять в строки символы кавычек, не используя экранирование. Например вот так(обратите внимание на кавычки внутри строки):
first_string = 'Слово "Python" обычно подразумевает змею' second_string = "I'm learning Python" 2. С помощью тройных кавычек.
Главное достоинство строк в тройных кавычках в том, что их можно использовать для записи многострочных блоков текста. Внутри такой строки возможно присутствие кавычек и апострофов, главное, чтобы не было трех кавычек подряд. Пример:
my_string = '''Это очень длинная строка, ей нужно много места''' 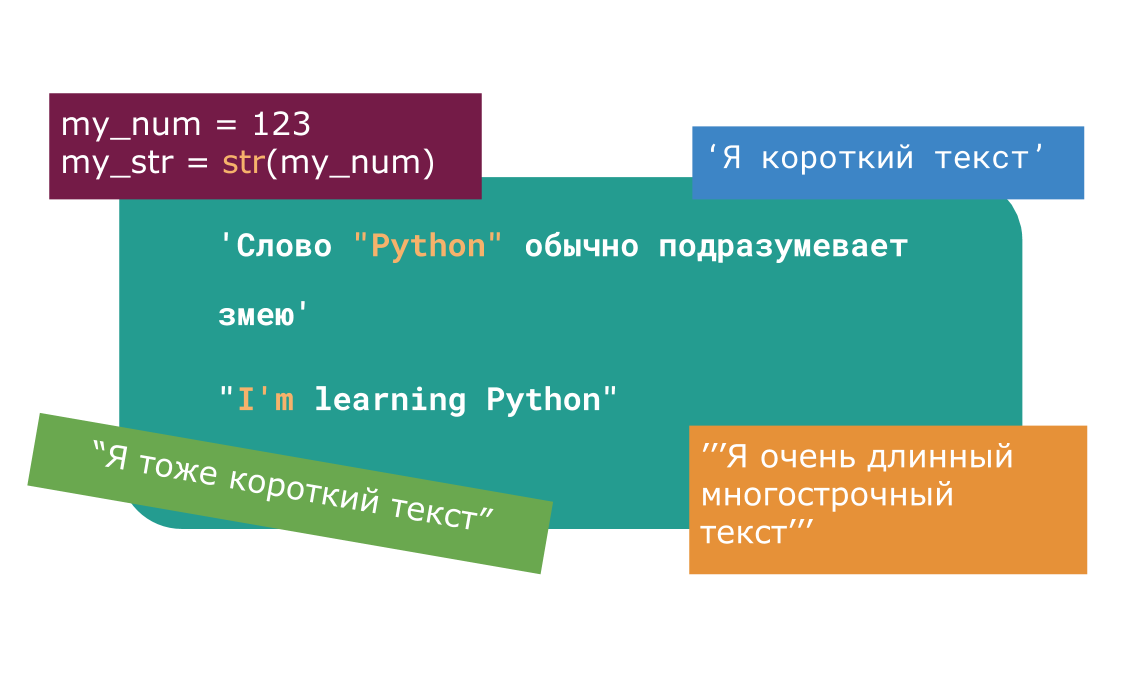
my_num = 12345 my_str = str(my_num) В данном случае мы создали новую строку путем конвертации переменной другого типа(например, int ).

Экранированные последовательности — это служебные наборы символов, которые позволяют вставить нестандартные символы, которые сложно ввести с клавиатуры.
В таблице перечислены самые часто используемые экранированные последовательности:
\n;Перевод строки \r; Возврат каретки \t; Горизонтальная табуляция \v;Вертикальная табуляция \uhhhh;16-битовый символ Юникода в 16-ричном представлении \x…;16-ричное значение \o…;8-ричное значение
# Обычная строка >>> str = 'Моя строка вот такая' >>> print(str) Моя строка вот такая # Добавим символ переноса строки >>> str = 'Моя строка\n вот такая' >>> print(str) Моя строка вот такая # А теперь добавим возврат каретки >>> str = 'Моя строка\n вот\r такая' >>> print(str) Моя строка такая # Горизонтальная табуляция(добавит отступ) >>> str = '\tМоя строка вот такая' >>> print(str) Моя строка вот такая # Вертикальная табуляция(добавит пустую строку) >>> str = '\vМоя строка вот такая' >>> print(str) Моя строка вот такая # Добавим китайский иероглиф в строку >>> str = 'Моя строка \u45b2 вот такая' >>> print(str) Моя строка 䖲 вот такая «Сырые строки»
Если перед открывающей кавычкой стоит символ ‘r’ (в любом регистре), то механизм экранирования отключается.
Это может быть нужно, например, в такой ситуации:
str = r’C:\new_file.txt’

Методов для работы со строками довольно много. Может возникнуть вопрос — а как же не запутаться в их многообразии? Ответ на него такой — необходимо структурировать и разбить методы по группам.
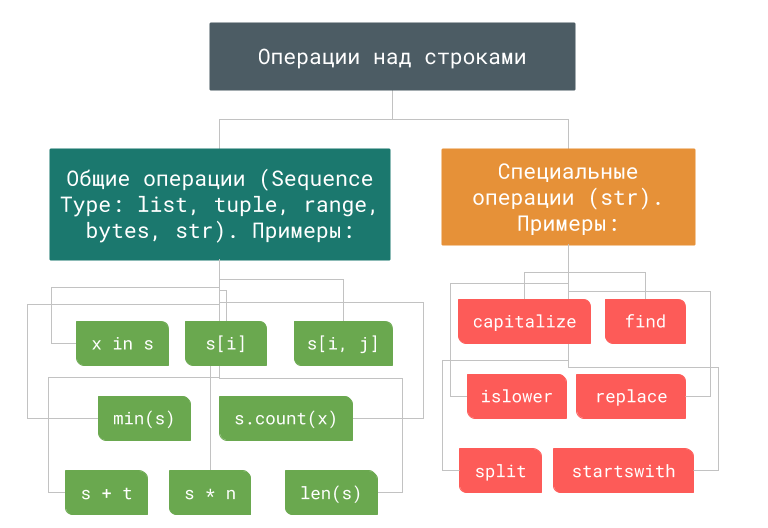
Итак, строки в Python поддерживают две группы методов:
- Списки( list )
- Кортежи( tuple )
- Диапазоны( range ).
- Обработки двоичных данных( binary data ) и
- Текстовых строк( str ).
x in s; Если элемент присутствует в последовательности, то возвращает True, иначе — False x not in s; Возвращает True, если элемент отсутствует в последовательности. s + t; Конкатенация(сложение) двух последовательностей s * n; Эквивалентно сложению последовательности s с собой n раз s[i]; Возвращает i-й элемент последовательности s[i, j]; Возвращает набор элементов последовательности с индексами из диапазона i
Подробнее об общих операциях для Sequence Type данных можно почитать в официальной документации по Python.
Подытожим
Строки в Python — представители Sequence Type данных. Это значит, что они(наряду со списками, кортежами и диапазонами) поддерживают все операции, приведенные в таблице выше.
Группа 2. Дополнительные методы, которые работают только со строками
Помимо общих операций, которые мы рассмотрели в таблице выше, существуют методы, которые могут быть использованы только для работы с типом str . В ходе урока рассмотрим самые важные и часто используемые из них.

Далее будем рассматривать базовые операции, которые можно выполнять со строками. Начнем со сложения и умножения строк. Они, как мы уже выяснили выше, относятся к группе общих операций над последовательностями. Итак:
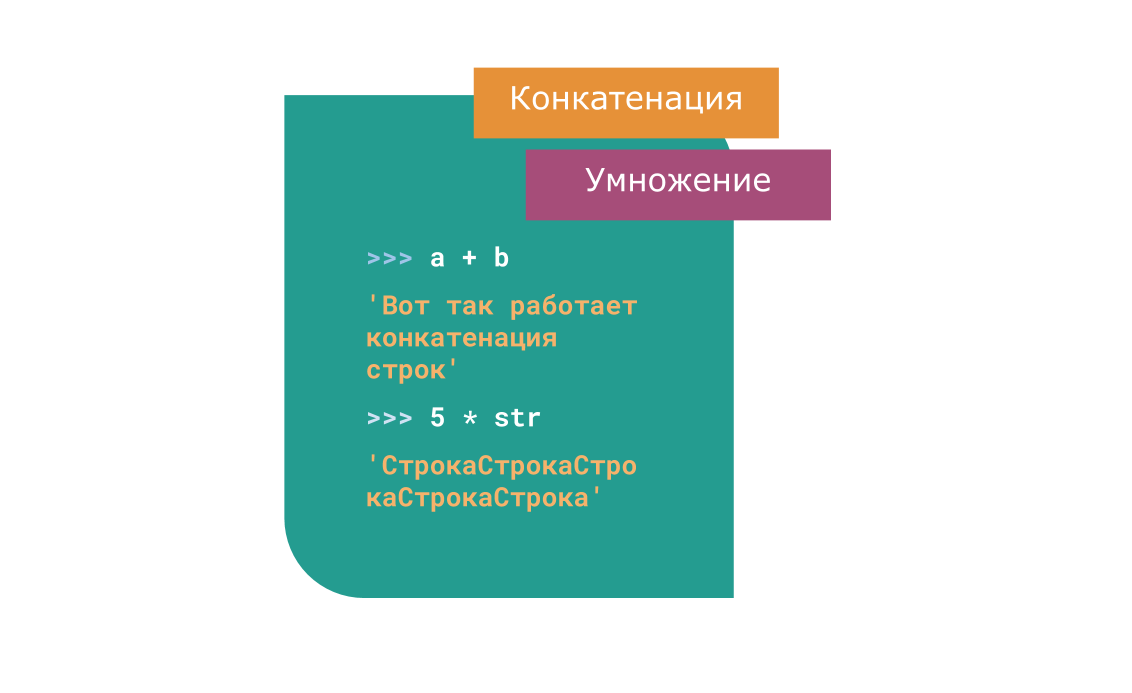
1. Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из совокупности других строк.
Например:
>>> a = 'Вот так работает' >>> b = ' конкатенация строк' >>> a + b 'Вот так работает конкатенация строк' 2. Оператор умножения строк *
* — оператор создает несколько копий строки. Если str это строка, а n целое число, то будет создано n копий строки str .
>>> str = 'Строка' >>> 5 * str 'СтрокаСтрокаСтрокаСтрокаСтрока' 
Срезы так же относятся к группе общих операций — они используются для всех последовательностей, а значит и для строковых переменных. Рассмотрим подробнее, что это такое и с чем его едят.
Срез (slice) — извлечение из данной строки одного символа или некоторого фрагмента подстроки или подпоследовательности.
Индекс — номер символа в строке (а также в других структурах данных: списках, кортежах). Обратите внимание, что нумерация начинается с 0 . Если указать отрицательное значение индекса, то номер будет отсчитываться с конца, начиная с номера -1 .
Есть три формы срезов:
1. Самая простая форма среза — взятие одного символа строки — S[i] , где S — строка, i — индекс. Пример:
>>> str = 'Hello' >>> str[0] 'H' >>> str[4] 'o' >>> str[-5] 'H' >>> str[6] Traceback (most recent call last): File "", line 1, in IndexError: string index out of range 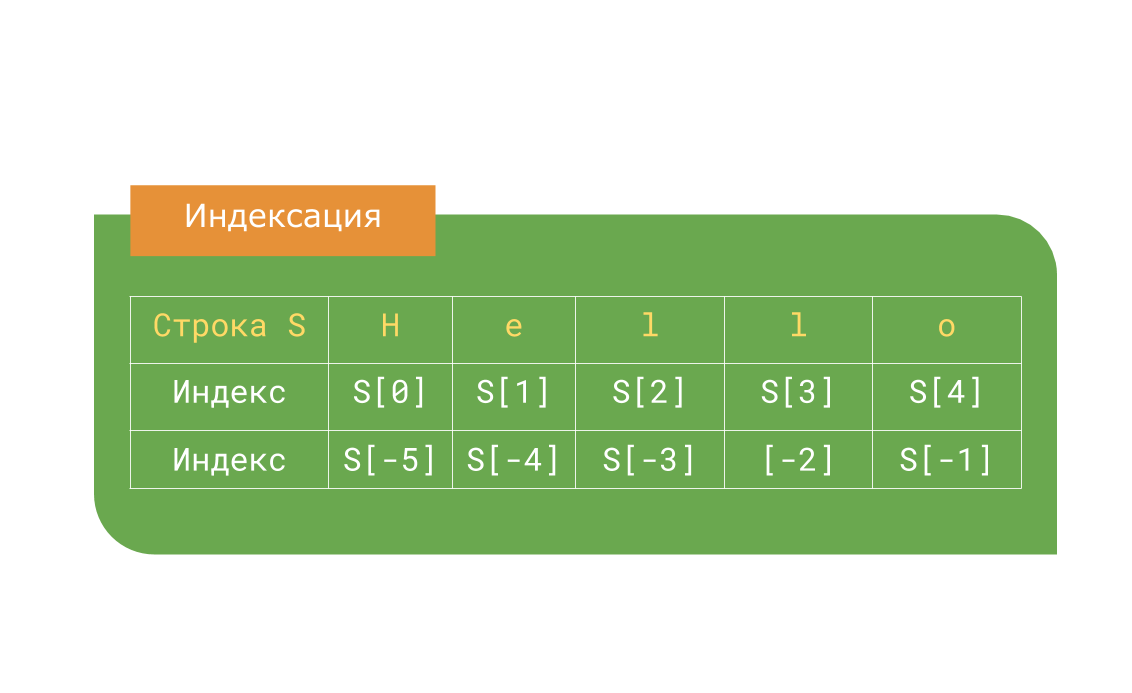
2. Второй тип — срез с двумя параметрами. Т. е. S[a:b] возвращает подстроку, начиная с символа c индексом a до символа с индексом b , не включая его. Если опустить второй параметр (но поставить двоеточие), то срез берется до конца строки. Пример:
>>> str = 'Hello' >>> str[0:4] 'Hell' >>> str[0:5] 'Hello' >>> str[1:3] 'el' >>> str[1:] 'ello' >>> str[0:] 'Hello' 3. Срез с тремя параметрами — S[a:b:d] . Третий параметр задает шаг(как в случае с функцией range ), то есть будут взяты символы с индексами a, a + d, a + 2 * d и т. д. Например, при задании значения третьего параметра, равному 2 , в срез попадет каждый второй символ:
>>> str = 'Hello' >>> str[0:5:1] 'Hello' >>> str[::1] 'Hello' >>> str[0:5:2] 'Hlo' >>> str[::2] 'Hlo' И еще разок: строки в Python — это неизменяемый тип данных!
Любые операции среза со строкой создают новые строки и никогда не меняют исходную строку. В Питоне строки вообще являются неизменяемыми, их невозможно изменить. Можно лишь в старую переменную присвоить новую строку.
Задачи по темам
Специфика типа данных словарь (dict) в Python, характеристики. Примеры использования словарей, задачи с решениями.
Строки как тип данных в Python. Основные методы и свойства строк. Примеры работы со строками, задачи с решениями.

Далее давайте рассмотрим методы второй группы, которые были созданы специально для работы с данными типа str . Полный и актуальный список методов можно посмотреть на странице официальной документации. И как вы сможете заметить, их там немало. Мы же с вами перечислим самые полезные из них и популярные, а так же рассмотрим несколько примеров их использования. Итак, список:
s.capitalize(); Преобразует первую букву первого слова строки s в букву в верхнем регистре, все остальные буквы преобразуются в буквы в нижнем регистре. s.title(); Преобразует первые буквы всех слов строки s в буквы верхнего регистра, все остальные буквы слов преобразует в буквы нижнего регистра. s.upper(); Преобразует все буквы строки s в буквы верхнего регистра. s.lower(); Преобразует все буквы строки s в буквы нижнего регистра. s.swapcase(); Преобразует все буквы верхнего регистра в буквы нижнего регистра, а буквы нижнего регистра преобразует в буквы верхнего регистра. s.isupper(); Возвращает True, если все символы строки, поддерживающие приведение к регистру, приведены к верхнему, иначе — False. s.islower(); Возвращает True, если все символы строки, поддерживающие приведение к регистру, приведены к нижнему, иначе — False. s.istitle();Определяет, начинаются ли слова строки с заглавной буквы. Возвращает True, когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Иначе — False.
Заголовок(Title): ‘Hello Everybody’ Строка с заглавной буквы(Capital): ‘Hello everybody’ Верхний регистр:(Upper) ‘HELLO EVERYBODY’ Нижний регистр(Lower): ‘hello everybody’ # Делаем строку заголовком >>> str.title('hello everybody') 'Hello Everybody' # Начинаем строку с заглавной буквы >>> str.capitalize('hello everybody') 'Hello everybody' # Переводим строку в верхний регистр >>> str.upper('hello everybody') 'HELLO EVERYBODY' # Переводим строку в нижний регистр >>> str.lower('Hello Everybody') 'hello everybody' # Инверсия регистра >>> str.swapcase('Hello Everybody') 'hELLO eVERYBODY' # Проверяем, являются ли строки заголовками >>> str.istitle('Hello everybody') False >>> str.istitle('HELLO EVERYBODY') False >>> str.istitle('Hello Everybody') True x.join(iterable); Возвращает строку, собранную из элементов указанного объекта, поддерживающего итерирование(например, список строк). s.split(x); Разбивает строку s на части, используя специальный разделитель x, и возвращает эти части в виде списка. s.partition(x); Принимает в качестве аргумента разделитель x (любой символ, букву или цифру). Слева-направо ищет в строке s первый встречающийся разделитель х и в месте разделителя разрезает строку на 3 части: 1) голову(часть строки до разделителя), 2) разделитель и 3) хвост(часть строки после разделителя). Метод возвращает кортеж(tuple), состоящий из трех элементов (голова, разделитель, хвост)