- Python Regex findall()
- Introduction to the Python regex findall() function
- Python regex findall() function examples
- 1) Using the Python regex findall() to get a list of matched strings
- 2) Using the findall() function with a pattern that has a single group
- 3) Using the findall() function with a pattern that has multiple groups
- 4) Using the findall() function with a regular expression flag
- Summary
- Python Regex Find All Matches using findall() and finditer()
- Table of contents
- How to use re.findall()
- Example to find all matches to a regex pattern
- Finditer method
- finditer example
- Regex find all word starting with specific letters
- Regex to find all word that starts and ends with a specific letter
- Regex to find all words containing a certain letter
- Regex findall repeated characters
Python Regex findall()
Summary: in this tutorial, you’ll learn how to use the Python regex findall() function to find all matches of a pattern in a string.
Introduction to the Python regex findall() function
The findall() is a built-in function in the re module that handles regular expressions. The findall() function has the following syntax:
re.findall(pattern, string, flags=0)Code language: Python (python)- pattern is a regular expression that you want to match.
- string is the input string
- flags is one or more regular expression flags that modify the standard behavior of the pattern.
The findall() function scans the string from left to right and finds all the matches of the pattern in the string .
The result of the findall() function depends on the pattern:
- If the pattern has no capturing groups, the findall() function returns a list of strings that match the whole pattern.
- If the pattern has one capturing group, the findall() function returns a list of strings that match the group.
- If the pattern has multiple capturing groups, the findall() function returns the tuples of strings that match the groups.
It’s important to note that the non-capturing groups do not affect the form of the return result.
Python regex findall() function examples
Let’s take some examples of using the findall() function.
1) Using the Python regex findall() to get a list of matched strings
The following example uses the findall() function to get a list of color names that start with the literal string bl :
import re s = "black, blue and brown" pattern = r'bl\w+' matches = re.findall(pattern,s) print(matches)Code language: Python (python)['black', 'blue']Code language: Python (python)The following pattern matches a literal string bl followed by one or more word characters specified by the \w+ rule:
'bl\w+'Code language: Python (python)Therefore, the findall() function returns a list of strings that match the whole pattern.
2) Using the findall() function with a pattern that has a single group
The following example uses the findall() function to get a list of strings that match a group:
import re s = "black, blue and brown" pattern = r'bl(\w+)' matches = re.findall(pattern,s) print(matches)Code language: Python (python)['ack', 'ue']Code language: Python (python)This example uses the regular expression r’bl(\w+)’ that has one capturing group (\w+) . Therefore, the findall() function returns a list of strings that match the group.
3) Using the findall() function with a pattern that has multiple groups
The following example uses the findall() functions to get tuples of strings that match the groups in the pattern:
import re s = "black, blue and brown" pattern = r'(bl(\w+))' matches = re.findall(pattern,s) print(matches)Code language: Python (python)[('black', 'ack'), ('blue', 'ue')]Code language: Python (python)In this example, the pattern r'(bl(\w+))’ has two capturing groups:
4) Using the findall() function with a regular expression flag
The following example uses the findall() function with the re.IGNORECASE flag:
import re s = "Black, blue and brown" pattern = r'(bl(\w+))' matches = re.findall(pattern, s, re.IGNORECASE) print(matches)Code language: Python (python)[('Black', 'ack'), ('blue', 'ue')]Code language: Python (python)In this example, we use the re.IGNORECASE flag in the findall() function that ignores the character cases of the matched strings. Therefore, the output includes both Black and blue .
Summary
Python Regex Find All Matches using findall() and finditer()
In this article, we will learn how to find all matches to the regular expression in Python. The RE module’s re.findall() method scans the regex pattern through the entire target string and returns all the matches that were found in the form of a list.
Table of contents
How to use re.findall()
Before moving further, let’s see the syntax of the re.findall() method.
re.findall(pattern, string, flags=0)- pattern : regular expression pattern we want to find in the string or text
- string : It is the variable pointing to the target string (In which we want to look for occurrences of the pattern).
- Flags : It refers to optional regex flags. by default, no flags are applied. For example, the re.I flag is used for performing case-insensitive findings.
The regular expression pattern and target string are the mandatory arguments, and flags are optional.
Return Value
The re.findall() scans the target string from left to right as per the regular expression pattern and returns all matches in the order they were found.
It returns None if it fails to locate the occurrences of the pattern or such a pattern doesn’t exist in a target string.

Example to find all matches to a regex pattern
In this example, we will find all numbers present inside the target string. To achieve this, let’s write a regex pattern.
What does this pattern mean?
- The \d is a special regex sequence that matches any digit from 0 to 9 in a target string.
- The + metacharacter indicates number can contain at minimum one or maximum any number of digits.
In simple words, it means to match any number inside the following target string.
target_string = "Emma is a basketball player who was born on June 17, 1993. She played 112 matches with scoring average 26.12 points per game. Her weight is 51 kg."As we can see in the above string ’17’, ‘1993’, ‘112’, ’26’, ’12’, ’51’ number are present, so we should get all those numbers in the output.
import re target_string = "Emma is a basketball player who was born on June 17, 1993. She played 112 matches with scoring average 26.12 points per game. Her weight is 51 kg." result = re.findall(r"\d+", target_string) # print all matches print("Found following matches") print(result) # Output ['17', '1993', '112', '26', '12', '51']First of all, I used a raw string to specify the regular expression pattern i.e r»\d+» . As you may already know, the backslash has a special meaning in some cases because it may indicate an escape character or escape sequence to avoid that we must use raw string.
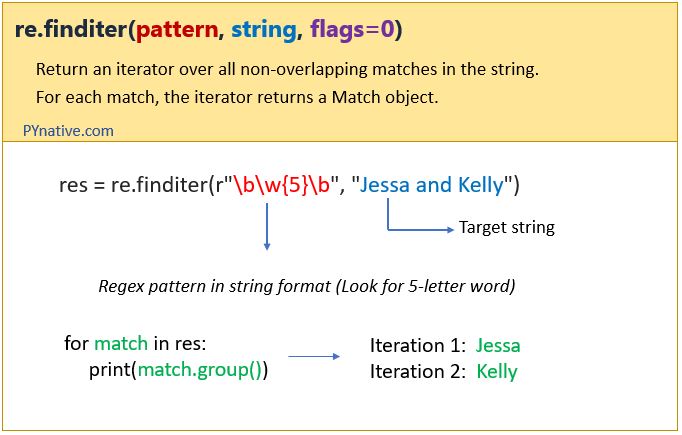
Finditer method
The re.finditer() works exactly the same as the re.findall() method except it returns an iterator yielding match objects matching the regex pattern in a string instead of a list.
It scans the string from left to right, and matches are returned in the iterator form. Later, we can use this iterator object to extract all matches.
In simple words, finditer() returns an iterator over MatchObject objects.
But why use finditer() ?
In some scenarios, the number of matches is high, and you could risk filling up your memory by loading them all using findall() . Instead of that using the finditer() , you can get all possible matches in the form of an iterator object, which will improve performance.
It means, finditer() returns a callable object which will load results in memory when called. Please refer to this Stackoverflow answer to get to know the performance benefits of iterators.
finditer example
Now, Let’s see the example to find all two consecutive digits inside the target string.
import re target_string = "Emma is a basketball player who was born on June 17, 1993. She played 112 matches with a scoring average of 26.12 points per game. Her weight is 51 kg." # finditer() with regex pattern and target string # \d to match two consecutive digits result = re.finditer(r"\d", target_string) # print all match object for match_obj in result: # print each re.Match object print(match_obj) # extract each matching number print(match_obj.group())re.Match object; span=(49, 51), match='17' 17 re.Match object; span=(53, 55), match='19' 19 re.Match object; span=(55, 57), match='93' 93 re.Match object; span=(70, 72), match='11' 11 re.Match object; span=(103, 105), match='26' 26 re.Match object; span=(106, 108), match='12' 12 re.Match object; span=(140, 142), match='51' 51
- Use finditer to find the indexes of all regex matches
- Regex findall special symbols from a string
Regex find all word starting with specific letters
In this example, we will see solve following 2 scenarios
- find all words that start with a specific letter/character
- find all words that start with a specific substring
Now, let’s assume you have the following string:
target_string = "Jessa is a Python developer. She also gives Python programming training"Now let’s find all word that starts with letter p. Also, find all words that start with substring ‘py‘
Pattern: \b[p]\w+\b
- The \b is a word boundary, then p in square bracket [] means the word must start with the letter ‘p‘.
- Next, \w+ means one or more alphanumerical characters after a letter ‘p’
- In the end, we used \b to indicate word boundary i.e. end of the word.
import re target_string = "Jessa is a Python developer. She also gives Python programming training" # all word starts with letter 'p' print(re.findall(r'\b[p]\w+\b', target_string, re.I)) # output ['Python', 'Python', 'programming'] # all word starts with substring 'Py' print(re.findall(r'\bpy\w+\b', target_string, re.I)) # output ['Python', 'Python']Regex to find all word that starts and ends with a specific letter
In this example, we will see solve following 2 scenarios
- find all words that start and ends with a specific letter
- find all words that start and ends with a specific substring
import re target_string = "Jessa is a Python developer. She also gives Python programming training" # all word starts with letter 'p' and ends with letter 'g' print(re.findall(r'\b[p]\w+[g]\b', target_string, re.I)) # output 'programming' # all word starts with letter 'p' or 't' and ends with letter 'g' print(re.findall(r'\b[pt]\w+[g]\b', target_string, re.I)) # output ['programming', 'training'] target_string = "Jessa loves mango and orange" # all word starts with substring 'ma' and ends with substring 'go' print(re.findall(r'\bma\w+go\b', target_string, re.I)) # output 'mango' target_string = "Kelly loves banana and apple" # all word starts or ends with letter 'a' print(re.findall(r'\b[a]\w+\b|\w+[a]\b', target_string, re.I)) # output ['banana', 'and', 'apple']Regex to find all words containing a certain letter
In this example, we will see how to find words that contain the letter ‘i’.
import re target_string = "Jessa is a knows testing and machine learning" # find all word that contain letter 'i' print(re.findall(r'\b\w*[i]\w*\b', target_string, re.I)) # found ['is', 'testing', 'machine', 'learning'] # find all word which contain substring 'ing' print(re.findall(r'\b\w*ing\w*\b', target_string, re.I)) # found ['testing', 'learning']Regex findall repeated characters
For example, you have a string: «»Jessa Erriika»»
As the result you want to have the following matches: (J, e, ss, a, E, rr, ii, k, a)
import re target_string = "Jessa Erriika" # This '\w' matches any single character # and then its repetitions (\1*) if any. matcher = re.compile(r"(\w)\1*") for match in matcher.finditer(target_string): print(match.group(), end=", ") # output J, e, ss, a, E, rr, ii, k, a,