How to convert JSON into a Pandas DataFrame
Reading data is the first step in any data science project. Often, you’ll work with data in JSON format and run into problems at the very beginning. In this article, you’ll learn how to use the Pandas built-in functions read_json() and json_normalize() to deal with the following common problems:
- Reading simple JSON from a local file
- Reading simple JSON from a URL
- Flattening nested list from JSON object
- Flattening nested list and dict from JSON object
- Extracting a value from deeply nested JSON
Please check out Notebook for the source code.
1. Reading simple JSON from a local file
Let’s begin with a simple example.
[
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
>,
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
>,
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
>
] To read a JSON file via Pandas, we can use the read_json() method.
df = pd.read_json('data/simple.json') The result looks great. Let’s take a look at the data types with df.info() . By default, columns that are numerical are cast to numeric types, for example, the math, physics, and chemistry columns have been cast to int64.
>>> df.info()
RangeIndex: 3 entries, 0 to 2
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 3 non-null object
1 name 3 non-null object
2 math 3 non-null int64
3 physics 3 non-null int64
4 chemistry 3 non-null int64
dtypes: int64(3), object(2)
memory usage: 248.0+ bytes
2. Reading simple JSON from a URL
pandas.read_json#
pandas. read_json ( path_or_buf , * , orient = None , typ = ‘frame’ , dtype = None , convert_axes = None , convert_dates = True , keep_default_dates = True , precise_float = False , date_unit = None , encoding = None , encoding_errors = ‘strict’ , lines = False , chunksize = None , compression = ‘infer’ , nrows = None , storage_options = None , dtype_backend = _NoDefault.no_default , engine = ‘ujson’ ) [source] #
Convert a JSON string to pandas object.
Parameters path_or_buf a valid JSON str, path object or file-like object
Any valid string path is acceptable. The string could be a URL. Valid URL schemes include http, ftp, s3, and file. For file URLs, a host is expected. A local file could be: file://localhost/path/to/table.json .
If you want to pass in a path object, pandas accepts any os.PathLike .
By file-like object, we refer to objects with a read() method, such as a file handle (e.g. via builtin open function) or StringIO .
orient str, optional
Indication of expected JSON string format. Compatible JSON strings can be produced by to_json() with a corresponding orient value. The set of possible orients is:
- ‘split’ : dict like [index], columns -> [columns], data -> [values]>
- ‘records’ : list like [ value>, . , value>]
- ‘index’ : dict like value>>
- ‘columns’ : dict like value>>
- ‘values’ : just the values array
The allowed and default values depend on the value of the typ parameter.
- when typ == ‘series’ ,
- allowed orients are
- default is ‘index’
- The Series index must be unique for orient ‘index’ .
- allowed orients are
- default is ‘columns’
- The DataFrame index must be unique for orients ‘index’ and ‘columns’ .
- The DataFrame columns must be unique for orients ‘index’ , ‘columns’ , and ‘records’ .
The type of object to recover.
dtype bool or dict, default None
If True, infer dtypes; if a dict of column to dtype, then use those; if False, then don’t infer dtypes at all, applies only to the data.
For all orient values except ‘table’ , default is True.
convert_axes bool, default None
Try to convert the axes to the proper dtypes.
For all orient values except ‘table’ , default is True.
convert_dates bool or list of str, default True
If True then default datelike columns may be converted (depending on keep_default_dates). If False, no dates will be converted. If a list of column names, then those columns will be converted and default datelike columns may also be converted (depending on keep_default_dates).
keep_default_dates bool, default True
If parsing dates (convert_dates is not False), then try to parse the default datelike columns. A column label is datelike if
- it ends with ‘_at’ ,
- it ends with ‘_time’ ,
- it begins with ‘timestamp’ ,
- it is ‘modified’ , or
- it is ‘date’ .
Set to enable usage of higher precision (strtod) function when decoding string to double values. Default (False) is to use fast but less precise builtin functionality.
date_unit str, default None
The timestamp unit to detect if converting dates. The default behaviour is to try and detect the correct precision, but if this is not desired then pass one of ‘s’, ‘ms’, ‘us’ or ‘ns’ to force parsing only seconds, milliseconds, microseconds or nanoseconds respectively.
encoding str, default is ‘utf-8’
The encoding to use to decode py3 bytes.
encoding_errors str, optional, default “strict”
How encoding errors are treated. List of possible values .
Read the file as a json object per line.
chunksize int, optional
Return JsonReader object for iteration. See the line-delimited json docs for more information on chunksize . This can only be passed if lines=True . If this is None, the file will be read into memory all at once.
Changed in version 1.2: JsonReader is a context manager.
For on-the-fly decompression of on-disk data. If ‘infer’ and ‘path_or_buf’ is path-like, then detect compression from the following extensions: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ or ‘.tar.bz2’ (otherwise no compression). If using ‘zip’ or ‘tar’, the ZIP file must contain only one data file to be read in. Set to None for no decompression. Can also be a dict with key ‘method’ set to one of < 'zip' , 'gzip' , 'bz2' , 'zstd' , 'tar' >and other key-value pairs are forwarded to zipfile.ZipFile , gzip.GzipFile , bz2.BZ2File , zstandard.ZstdDecompressor or tarfile.TarFile , respectively. As an example, the following could be passed for Zstandard decompression using a custom compression dictionary: compression= .
New in version 1.5.0: Added support for .tar files.
Changed in version 1.4.0: Zstandard support.
The number of lines from the line-delimited jsonfile that has to be read. This can only be passed if lines=True . If this is None, all the rows will be returned.
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
Which dtype_backend to use, e.g. whether a DataFrame should have NumPy arrays, nullable dtypes are used for all dtypes that have a nullable implementation when “numpy_nullable” is set, pyarrow is used for all dtypes if “pyarrow” is set.
The dtype_backends are still experimential.
Parser engine to use. The «pyarrow» engine is only available when lines=True .
The type returned depends on the value of typ .
Convert a DataFrame to a JSON string.
Convert a Series to a JSON string.
Normalize semi-structured JSON data into a flat table.
Specific to orient=’table’ , if a DataFrame with a literal Index name of index gets written with to_json() , the subsequent read operation will incorrectly set the Index name to None . This is because index is also used by DataFrame.to_json() to denote a missing Index name, and the subsequent read_json() operation cannot distinguish between the two. The same limitation is encountered with a MultiIndex and any names beginning with ‘level_’ .
>>> df = pd.DataFrame([['a', 'b'], ['c', 'd']], . index=['row 1', 'row 2'], . columns=['col 1', 'col 2'])
Encoding/decoding a Dataframe using ‘split’ formatted JSON:
>>> df.to_json(orient='split') '<"columns":["col 1","col 2"],"index":["row 1","row 2"],"data":[["a","b"],["c","d"]]>' >>> pd.read_json(_, orient='split') col 1 col 2 row 1 a b row 2 c d
Encoding/decoding a Dataframe using ‘index’ formatted JSON:
>>> df.to_json(orient='index') ',"row 2":>'
>>> pd.read_json(_, orient='index') col 1 col 2 row 1 a b row 2 c d
Encoding/decoding a Dataframe using ‘records’ formatted JSON. Note that index labels are not preserved with this encoding.
>>> df.to_json(orient='records') '[,]' >>> pd.read_json(_, orient='records') col 1 col 2 0 a b 1 c d
Encoding with Table Schema
>>> df.to_json(orient='table') '<"schema":<"fields":[<"name":"index","type":"string">,,],"primaryKey":["index"],"pandas_version":"1.4.0">,"data":[,]>'
JSON with Python Pandas
Read json string files in pandas read_json() . You can do this for URLS, files, compressed files and anything that’s in json format. In this post, you will learn how to do that with Python.
First load the json data with Pandas read_json method, then it’s loaded into a Pandas DataFrame.
Read JSON
What is JSON?
JSON is shorthand for JavaScript Object Notation. This is a text format that is often used to exchange data on the web.
The format looks like this:

In practice, this data is often on one line, like so:
Any type of data can be stored in this format (string, integer, float etc).
It’s common for a web server to return and accept json format. This is often how the frontend communicates with the backend.
pandas.read_json
The example below parses a JSON string and converts it to a Pandas DataFrame.
# load pandas and json modules
import pandas as pd
import json# json string
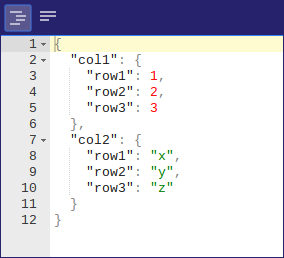
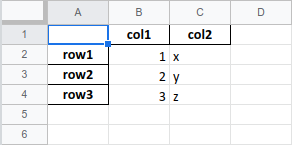
s = ‘{«col1»:{«row1″:1,»row2″:2,»row3″:3},»col2»:{«row1″:»x»,»row2″:»y»,»row3″:»z»}}’# read json to data frame
df = pd.read_json(s)
print(df)You can run it to see the output:
Load JSON from URL
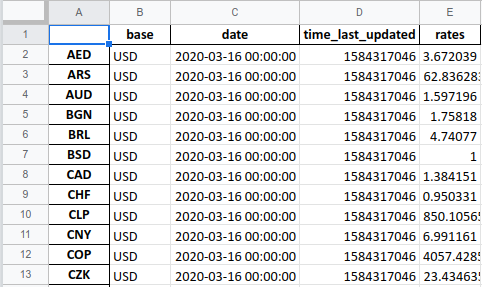
To load JSON from an URL (API), you can use this code:
import requests
from pandas.io.json import json_normalize
import pandas as pdurl = «https://api.exchangerate-api.com/v4/latest/USD»
df = pd.read_json(url)
print(df)Save to JSON file
A DataFrame can be saved as a json file. To do so, use the method to_json(filename) .
If you want to save to a json file, you can do the following:import pandas as pd
import json
df = pd.DataFrame([1,2,3])
df.to_json(‘example.json’)For a dataframe with several columns:
import pandas as pd
import json
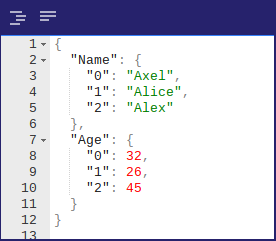
data = [[‘Axel’,32], [‘Alice’, 26], [‘Alex’, 45]]
df = pd.DataFrame(data,columns=[‘Name’,‘Age’])
df.to_json(‘example.json’)Load JSON from File
If the json data is stored in a file, you can load it into a DataFrame.
You can use the example above to create a json file, then use this example to load it into a dataframe.
df_f = pd.read_json(‘files/sample_file.json’)
For a compressed file .gz use:
df_gzip = pd.read_json(‘sample_file.gz’, compression=‘infer’)
If the extension is .gz , .bz2 , .zip , and .xz , the corresponding compression method is automatically selected.
Pandas to JSON example
In the next example, you load data from a csv file into a dataframe, that you can then save as json file.
You can load a csv file as a pandas dataframe:
Then save the DataFrame to JSON format:
# save a dataframe to json format:
df.to_json(«data.json»)This also works for Excel files.