Поиск объектов на фото с помощью Python
В данной статье хочу рассказать про поиск объектов на изображении с помощью Python и OpenCV. В качестве изображения может быть использована как Captcha, так и любое другое изображение.
Полный код и все исходники можно найти на моем Github.
Для того, чтобы написать легковесное приложение для обнаружения объектов на изображении, установим необходимые библиотеки:
pip install opencv-python pip install numpyТакже для красивого вывода текста в консоль я добавил следующую библиотеку:
Теперь можем перейти к написанию самого приложения, которое будет находить объекты на изображении при помощи YOLO и отмечать их.
Скачаем с моего Github исходники и поместим в директорию Resources в проекте. Посмотрим, какие объекты сможет определять наша будущая программа:
'person', 'bicycle', 'car', 'motorbike', 'aeroplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'sofa', 'pottedplant', 'bed', 'diningtable', 'toilet', 'tvmonitor', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'Первым делом импортируем необходимые библиотеки:
import cv2 import numpy as np from art import tprintНапишем функции для применения YOLO. С ее помощью определяются самые вероятные классы объектов на изображении, а также координаты их границ, которые в дальнейшем будут использованы для отрисовки.
def apply_yolo_object_detection(image_to_process): """ Recognition and determination of the coordinates of objects on the image :param image_to_process: original image :return: image with marked objects and captions to them """ height, width, _ = image_to_process.shape blob = cv2.dnn.blobFromImage(image_to_process, 1 / 255, (608, 608), (0, 0, 0), swapRB=True, crop=False) net.setInput(blob) outs = net.forward(out_layers) class_indexes, class_scores, boxes = ([] for i in range(3)) objects_count = 0 # Starting a search for objects in an image for out in outs: for obj in out: scores = obj[5:] class_index = np.argmax(scores) class_score = scores[class_index] if class_score > 0: center_x = int(obj[0] * width) center_y = int(obj[1] * height) obj_width = int(obj[2] * width) obj_height = int(obj[3] * height) box = [center_x - obj_width // 2, center_y - obj_height // 2, obj_width, obj_height] boxes.append(box) class_indexes.append(class_index) class_scores.append(float(class_score)) # Selection chosen_boxes = cv2.dnn.NMSBoxes(boxes, class_scores, 0.0, 0.4) for box_index in chosen_boxes: box_index = box_index box = boxes[box_index] class_index = class_indexes[box_index] # For debugging, we draw objects included in the desired classes if classes[class_index] in classes_to_look_for: objects_count += 1 image_to_process = draw_object_bounding_box(image_to_process, class_index, box) final_image = draw_object_count(image_to_process, objects_count) return final_image Добавим функцию, которая обведет найденные на изображении объекты с помощью координат границ, полученных из функции apply_yolo_object_detection :
def draw_object_bounding_box(image_to_process, index, box): """ Drawing object borders with captions :param image_to_process: original image :param index: index of object class defined with YOLO :param box: coordinates of the area around the object :return: image with marked objects """ x, y, w, h = box start = (x, y) end = (x + w, y + h) color = (0, 255, 0) width = 2 final_image = cv2.rectangle(image_to_process, start, end, color, width) start = (x, y - 10) font_size = 1 font = cv2.FONT_HERSHEY_SIMPLEX width = 2 text = classes[index] final_image = cv2.putText(final_image, text, start, font, font_size, color, width, cv2.LINE_AA) return final_image Помимо отрисовки объектов, можно добавить вывод их количества. Напишем для этого еще одну функцию:
def draw_object_count(image_to_process, objects_count): """ Signature of the number of found objects in the image :param image_to_process: original image :param objects_count: the number of objects of the desired class :return: image with labeled number of found objects """ start = (10, 120) font_size = 1.5 font = cv2.FONT_HERSHEY_SIMPLEX width = 3 text = "Objects found: " + str(objects_count) # Text output with a stroke # (so that it can be seen in different lighting conditions of the picture) white_color = (255, 255, 255) black_outline_color = (0, 0, 0) final_image = cv2.putText(image_to_process, text, start, font, font_size, black_outline_color, width * 3, cv2.LINE_AA) final_image = cv2.putText(final_image, text, start, font, font_size, white_color, width, cv2.LINE_AA) return final_image Для получения результата будем выводить входное изображение, только с отрисованными объектами и их количеством:
def start_image_object_detection(img_path): """ Image analysis """ try: # Applying Object Recognition Techniques in an Image by YOLO image = cv2.imread(img_path) image = apply_yolo_object_detection(image) # Displaying the processed image on the screen cv2.imshow("Image", image) if cv2.waitKey(0): cv2.destroyAllWindows() except KeyboardInterrupt: pass Программа уже почти готова, осталось только написать функцию main , где будем передавать аргументы в функции.
Данный блок не является обязательным, но я захотел сделать красивый вывод текста в консоль:
# Logo tprint("Object detection") tprint("by") tprint("paveldat")Создадим функцию main , в которой настроим нашу сеть:
if __name__ == '__main__': # Loading YOLO scales from files and setting up the network net = cv2.dnn.readNetFromDarknet("Resources/yolov4-tiny.cfg", "Resources/yolov4-tiny.weights") layer_names = net.getLayerNames() out_layers_indexes = net.getUnconnectedOutLayers() out_layers = [layer_names[index - 1] for index in out_layers_indexes] # Loading from a file of object classes that YOLO can detect with open("Resources/coco.names.txt") as file: classes = file.read().split("\n") # Determining classes that will be prioritized for search in an image # The names are in the file coco.names.txt image = input("Path to image(recapcha): ") look_for = input("What we are looking for: ").split(',') # Delete spaces list_look_for = [] for look in look_for: list_look_for.append(look.strip()) classes_to_look_for = list_look_for start_image_object_detection(image) Программа будет запрашивать путь до изображения и объекты, которые хотим найти. Объекты должны перечисляться через запятую, если их несколько.
Запускаем программу и тестируем. Слева будет оригинальное изображение, а справа — обработанное.
Path to image(recapcha): Result\input\bus1.png What we are looking for: bus
Path to image(recapcha): Result\input\truck.jpg What we are looking for: truck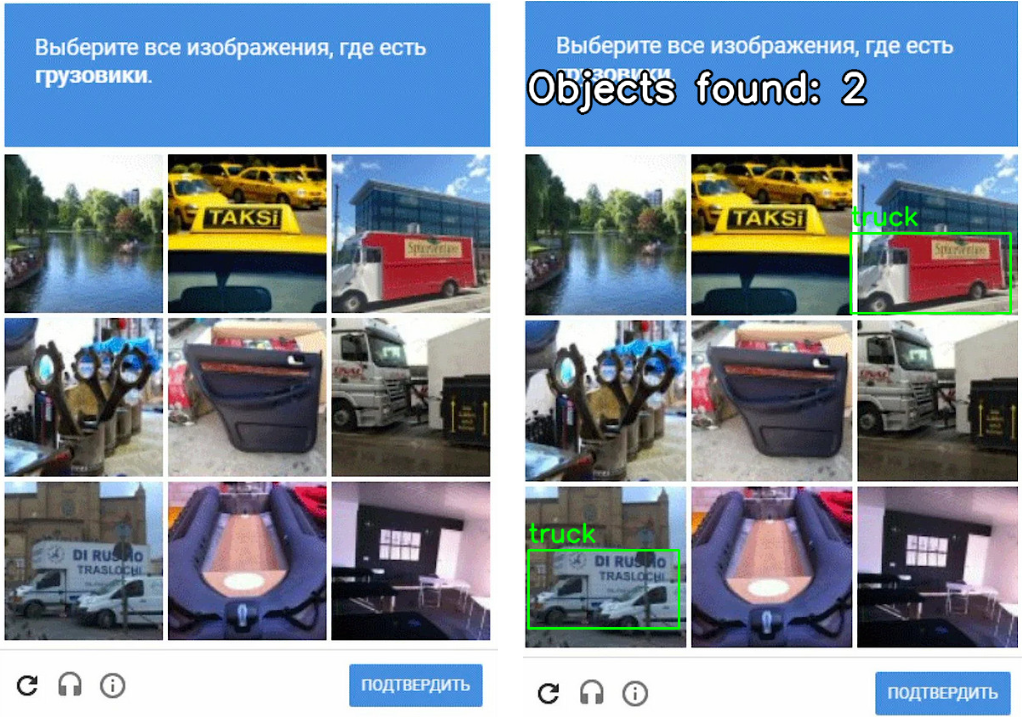
Path to image(recapcha): Result\input\city.png What we are looking for: car, person, traffic light
Мы проверили, как алгоритм YOLO справился с тестом. Погрешность все же есть, но в основном программа успешно находит необходимые объекты.