- Understanding Sampling With and Without Replacement (Python)
- What is Sampling with Replacement
- Sampling with Replacement using NumPy
- Sampling with Replacement using Pandas
- How many duplicate samples/rows should you expect when sampling with replacement to create a bootstrapped dataset?
- What is Sampling without Replacement
- Sampling without Replacement using NumPy
- Examples of Sampling without Replacement in Data Science
- Conclusion
- Understanding random sampling with and without replacement (with python code)
- Sampling without replacement
- Sampling with replacement
- Enhance your skills with courses on machine learning
- Share on
- You may also enjoy
- Two-Way ANOVA in R: How to Analyze and Interpret Results
- How to Perform One-Way ANOVA in R (With Example Dataset)
- What is Nextflow and How to Use it?
- How to Convert FASTQ to FASTA Format (With Example Dataset)
Understanding Sampling With and Without Replacement (Python)
The reason why the sampling unit is returned to the population before the next sampling unit is drawn is to make sure the probability of selecting any particular sampling unit remains the same in future draws. There are many applications of sampling with replacement throughout data science. Many of these applications use bootstrapping which is a statistical procedure that uses sampling with replacement on a dataset to create many simulated samples. Datasets that are created with sampling with replacement so that they have the same number of samples as the original dataset are called bootstrapped datasets. Bootstrapped data is used in machine learning algorithms like bagged trees and random forests as well as in statistical methods like bootstrapped confidence intervals, and more.
This tutorial will dive into sampling with and without replacement and will touch on some common applications of these concepts in data science. As always, the code used in this tutorial is available on my GitHub. With that, let’s get started!
What is Sampling with Replacement
Sampling with replacement can be defined as random sampling that allows sampling units to occur more than once. Sampling with replacement consists of
- A sampling unit (like a glass bead or a row of data) being randomly drawn from a population (like a jar of beads or a dataset).
- Recording which sampling unit was drawn.
- Returning the sampling unit to the population.
Imagine you have a jar of 12 unique glass beads like in the image above. If you are sampling with replacement from the jar, the chance of randomly selecting any 1 of the glass beads is 1/12. After selecting a bead, return it to the jar so that the probability of selecting any of the 12 beads in future sampling doesn’t change (1/12). This means that if you repeat the process it is entirely possible you could randomly take out the same bead (1/12 chance in this case).
This remaining parts of this section go over how sampling with replacement can be done using the Python libraries NumPy and Pandas and will go over related concepts like bootstrapped datasets and how many duplicate samples should you expect when sampling with replacement to create a bootstrapped dataset.
Sampling with Replacement using NumPy
In order to better understand sample with replacement, let’s now simulate this process with Python. The code below loads NumPy and samples with replacement 12 times from a NumPy array containing unique numbers from 0 to 11.
import numpy as np
np.random.seed(3)# a parameter: generate a list of unique random numbers (from 0 to 11)
# size parameter: how many samples we want (12)
# replace = True: sample with replacement
np.random.choice(a=12, size=12, replace=True)
The reason why we sampled 12 times in the code above is because the original jar (dataset) we are sampling from has 12 beads (sampling units) in it. The 12 marbles we selected are now part of a bootstrapped dataset which is a dataset that is created with sampling with replacement that has the same number of values as the original dataset.
Sampling with Replacement using Pandas
Since most people aren’t interested in the application of sampling beads out of a jar, it is important to mention a sampling unit can also be something like an entire row of data. The code below creates a bootstrapped dataset using Kaggle’s King County dataset which contains the price at which houses were sold for in King County, which includes Seattle between May 2014 and May 2015. You can download the dataset from Kaggle or load it from my GitHub.
# Import libraries
import numpy as np
import pandas as pd# Load dataset
url = 'https://raw.githubusercontent.com/mGalarnyk/Tutorial_Data/master/King_County/kingCountyHouseData.csv'
df = pd.read_csv(url)
# Selecting columns I am interested in
columns= ['bedrooms','bathrooms','sqft_living','sqft_lot','floors','price']
df = df.loc[:, columns]# Only want to use 15 rows of the dataset for illustrative purposes.
df = df.head(15)# Notice how we have 3 rows with the index label 8
df.sample(n = 15, replace = True, random_state=2)
How many duplicate samples/rows should you expect when sampling with replacement to create a bootstrapped dataset?
It is important to note that when you do sample with replacement to generate data you will likely get duplicate samples/rows. In practice, the average bootstrapped dataset contains about 63.2% of the original rows. This means that for any particular row of data in the original dataset, 36.8% of the bootstrapped datasets will not contain it.
This subsection briefly shows how you can derive these numbers statistically and as well as get close to them by experiment using the Python library pandas.
Basic Statistics
Let’s start by deriving how for any particular row of data in the original dataset, 36.8% of the bootstrapped datasets will not contain that row.
Assume there are N rows of data in the original dataset. If you want to create a bootstrapped dataset, you need to sample with replacement N times.
For a SINGLE sample with replacement, the probability that a particular row of data is not randomly sampled with replacement from the dataset is
Since a bootstrapped dataset is obtained by sampling N times from a dataset of size N, we need to sample N times to find the probability that a particular row is not chosen in a given bootstrapped dataset.
If we take the limit as N goes to infinity , we find that the probability is .368.
The probability that any particular row of data from the original dataset would be in the bootstrapped dataset is just 1 — 𝑒^-1 = .63213. Note that in real life, the larger your dataset is (the larger N is), the more likely you will get close to these numbers.
Using pandas
The code below uses pandas to show that a bootstrapped dataset will contain about 63.2% of the original rows.
# Import libraries
import numpy as np
import pandas as pd# Load dataset
url = 'https://raw.githubusercontent.com/mGalarnyk/Tutorial_Data/master/King_County/kingCountyHouseData.csv'
df = pd.read_csv(url)
# Selecting columns I am interested in
columns= ['bedrooms','bathrooms','sqft_living','sqft_lot','floors','price']
df = df.loc[:, columns]"""
Generate Bootstrapped Dataset (dataset generated with sample with replacement which has the same number of values as original dataset)
% of original rows will vary depending on random_state
"""
bootstrappedDataset = df.sample(frac = 1, replace = True, random_state = 2)
In the bootstrap sample below, note that it contains about 63.2% of the original samples/rows. This is because the sample size was large (len(df) is 21613). This also means that each bootstrapped dataset will not include about 36.8% of the rows from the original dataset.
len(bootstrappedDataset.index.unique()) / len(df) What is Sampling without Replacement
Sampling without replacement can be defined as random sampling that DOES NOT allow sampling units to occur more than once. Let’s now go over a quick example of how sampling without replacement works.
Imagine you have a jar of 12 unique glass beads like in the image above. If you are sampling without replacement from the jar, the chance of randomly selecting any 1 of the glass beads is 1/12. After selecting a bead, it is NOT returned to the jar so that the probability of selecting any of the remaining 11 beads in future sampling is now (1/11). This means that for each additional sample drawn, there are less and less beads in the jar until eventually there are no more beads to sample (after 12 samplings).
Sampling without Replacement using NumPy
In order to ingrain this knowledge, let’s now simulate this process with Python. The code below loads NumPy and samples without replacement 12 times from a NumPy array containing unique numbers from 0 to 11
import numpy as np
np.random.seed(3)# a parameter: generate a list of unique random numbers (from 0 to 11)
# size parameter: how many samples we want (12)
# replace = False: sample without replacement
np.random.choice(a=12, size=12, replace=False)
Note that if you try to generate a sample using sampling WITHOUT replacement that is longer than the original sample (12 in this case), you will get an error. Going to back to the jar of beads example, you can’t sample more beads than there are in the jar.
np.random.seed(3)
np.random.choice(a=12, size=20, replace=False) Examples of Sampling without Replacement in Data Science
Sampling without replacement is used throughout data science. One very common use is in model validation procedures like train test split and cross validation. In short, each of these procedures allows you to simulate how a machine learning model would perform on new/unseen data.
The image below shows the train test split procedure which consists of splitting a dataset into two pieces: a training set and a testing set. This consists of randomly sampling WITHOUT replacement about 75% (you can vary this) of the rows and putting them into your training set and putting the remaining 25% to your test set. Note that the colors in “Features” and “Target” indicate where their data will go (“X_train”, “X_test”, “y_train”, “y_test”) for a particular train test split.
If you would like to learn more about train test split, you can check out my blog post Understanding Train Test Split.
Conclusion
Understanding the concept of sampling with and without replacement is important in statistics and data science. Bootstrapped data is used in machine learning algorithms like bagged trees and random forests as well as in statistical methods like bootstrapped confidence intervals, and more.
A future tutorials will take some of this knowledge and go over how it is applied to understanding bagged trees and random forests. If you have any questions or thoughts on the tutorial, feel free to reach out in the comments below or through Twitter.
Understanding random sampling with and without replacement (with python code)
Statistics and machine learning rely heavily on random sampling (or simple random sampling). Basically, random sampling refers to the selection of observations from a large dataset (population) at random, where each observation has an equal chance of being chosen.
For example, in a bag of 100 balls, if we select any 10 balls and every ball has an equal chance of selection, then it is called a random sample.
Simple Random sampling can be divided into sampling without replacement and sampling with replacement based on the method of selection.
Sampling without replacement
In sampling without replacement method, the samples are selected randomly from the original dataset (population) without any replacement. That is if one sample is selected, it will not be selected again.
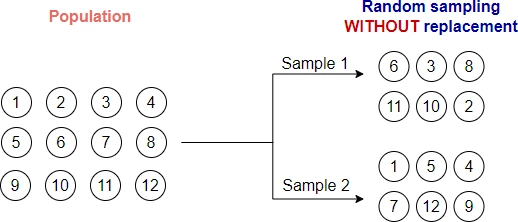
For example, in a bag of 10 balls, we can have two random samples of 5 balls. Every ball has an equal chance of selection.
Let’s perform random sampling without replacement using random.sample() function in Python
In the above example, you can see sample of size 5 drawn randomly without replacement from a bag of 10 balls. Sampling with replacement
In the sampling with replacement method, the samples are selected randomly from the original dataset (population) with possible replacement. That is if one sample is selected, it may be selected again.
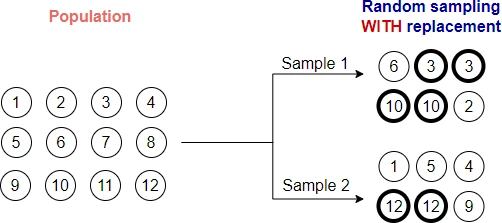
For example, in bag of 10 balls, we can select one ball randomly and make a record of it. Then put that back again in the bag and select second ball. Repeat the process until required size of sample. In this sampling, there is chance that same ball can be selected multiple times.
Let’s perform random sampling without replacement using random.choices() function in Python
In the above example, you can see a sample of size 5 drawn randomly with replacement (some balls are repetitive) from a bag of 10 balls. Enhance your skills with courses on machine learning
If you have any questions, comments or recommendations, please email me at reneshbe@gmail.com
If you enhanced your knowledge and practical skills from this article, consider supporting me on

Some of the links on this page may be affiliate links, which means we may get an affiliate commission on a valid purchase. The retailer will pay the commission at no additional cost to you.
Updated: January 15, 2023
Share on
You may also enjoy
Two-Way ANOVA in R: How to Analyze and Interpret Results
Renesh Bedre 2 minute read
This article explains how to perform two-way ANOVA in R
How to Perform One-Way ANOVA in R (With Example Dataset)
Renesh Bedre 1 minute read
This article explains how to perform one-way ANOVA in R
What is Nextflow and How to Use it?
Renesh Bedre 1 minute read
Learn what is Nextflow and how to use it for running bioinformatics pipeline

How to Convert FASTQ to FASTA Format (With Example Dataset)
Renesh Bedre 1 minute read
List of Bioinformatics tools to convert FASTQ file into FASTA format
© 2023 Data science blog. Powered by Jekyll& Minimal Mistakes.