Предварительная обработка данных с помощью библиотеки Pandas (Задача)
В современном мире большинство бизнес-процессов связаны с обработкой больших объемов данных, получаемых от различных источников. Часто эти данные содержат ошибки, дубликаты и пропуски, что может привести к неверным выводам и решениям. Одним из инструментов, которые позволяют очистить и преобразовать данные, является библиотека pandas для языка программирования Python.
Я собираюсь рассмотреть задачу по очистке данных с помощью pandas. Для этого возьмем данные, содержащие дубликаты строк, неправильные типы данных, пропуски и отрицательные значения. Затем я буду использовать функциональные возможности pandas для очистки и преобразования этих данных в форму, пригодную для дальнейшего анализа.
Предположим, у вас есть набор данных, содержащий информацию о продажах компании за последние несколько лет. Но данные не очень чистые, и вы заметили, что есть некоторые проблемы с форматированием и некоторые строки содержат ошибки.
Задача: Необходимо очистить данные о продажах компании за последние несколько лет с помощью библиотеки Pandas.
- Файл CSV, содержащий информацию о продажах компании за последние несколько лет.
- Файл содержит следующие столбцы: дата продажи, название продукта, количество проданного товара, цена за единицу, общая стоимость продажи, имя продавца и регион продажи.
- В некоторых строках присутствуют ошибки, например, неправильный формат даты или отсутствие цены за единицу.
Задачи, которые необходимо выполнить:
- Загрузить исходные данные из файла в Pandas DataFrame.
- Удалить строки, которые содержат ошибки в данных.
- Привести столбец с датами к формату datetime .
- Привести столбцы с числами к числовому формату (float или int).
- Определить и удалить дубликаты строк.
- Сохранить очищенные данные в новый файл CSV.
- date — дата продажи, в формате «YYYY-MM-DD»;
- product_name — название продукта
- quantity — количество продукта
- unit_price — цена за единицу продукта
- total_price — общая стоимость продукта, равная произведению количества и цены за единицу
- seller_name — имя продавца
- region — регион продажи
Загрузка данных
Чтобы загрузить данные в pandas, можно использовать метод read_csv() для загрузки данных из файла CSV или read_excel() для загрузки данных из файла Excel . В нашем случае у нас csv файл.
Импортируем необходимые библиотеки и загружаем данные.
import pandas as pd import re df = pd.read_csv('data_with_errors.csv')
На первый взгляд в данных видно наличие отрицательных значений и пропусков. Однако, в нашем задании сказано, что после загрузки мы должны удалить строки, в которых есть ошибки. Мы поступим немного по-другому. Сначала мы проверим типы столбцов, и если обнаружится, что какие-то столбцы не соответствуют данным, которые в них находятся, мы изменим тип на соответствующий. При возникновении проблем в ходе выполнения этой задачи, мы будем исправлять то, что будет необходимо.
Обработка данных
Для начала посмотрим на то, какие типы имеют наши столбцы. Для этого нам поможет команда info() .
Мы получаем информацию о нашем DataFrame, которая говорит нам о наличии пропусков в столбце total_price . Также мы видим, что столбец с датами имеет строковый тип, также как и столбцы quantity и unit_price , которые содержат числовые данные. Нам необходимо это исправить.

Попробуем сразу привести столбец date к типу datetime . Для этого нам понадобится следующий код:
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')К сожалению, этот код не сработает, так как в столбце с данными присутствуют значения, которые не позволяют сразу привести столбец к нужному нам типу. В результате работы выражения будет выведено сообщение об ошибке.

Существует множество способов решения данной проблемы, один из них представлен ниже. Так как даты в нашем столбце date указаны в формате «YYYY-MM-DD», мы можем использовать регулярное выражение для поиска всех значений столбца, которые не соответствуют данному формату. Для этого мы создадим лямбда-функцию, которая будет применена к столбцу методом map() . Регулярное выражение будет выглядеть следующим образом: `\d-\d-\d`.
search = lambda x: x if re.search(r"\d-\d-\d", x) else 'not found'Применяем лямбда-функцию к столбцу date .
df.query('date == "not found"').count()Мы видим, что в 53 строках данные не соответствуют формату..

Посмотрим на эти строки, чтобы понять, с чем мы имеем дело.
df.query('date == "not found"').head(5)
Мы замечаем отсутствие даты, а также латинские буквы вместо чисел в столбце количества quantity . Кроме того, столбец total_price содержит множество пропусков, а unit_price имеет много повторяющихся значений. В таком виде данные не представляют ценности для анализа, и мы должны удалить строки, содержащие ошибки, как указано в задании.
df = df.drop(df.query('date == "not found"').index) df.query('date == "not found"').count()
Приведем столбец date к нужному нам типу данных.
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')Видим что столбец date теперь имеет тип datetime.

Для того чтобы привести столбец quantity к числовому формату, мы можем использовать метод to_numeric() с параметром errors=’coerce’ , который преобразует значения в числа, а нечисловые значения заменяет на NaN.
df['quantity'] = pd.to_numeric(df['quantity'], errors='coerce')Тоже самое мы делаем с unit_price.
df['unit_price'] = pd.to_numeric(df['unit_price'], errors='coerce')Для продолжения, мы сфокусируемся на отрицательных значениях в указанных столбцах и выведем их на экран.
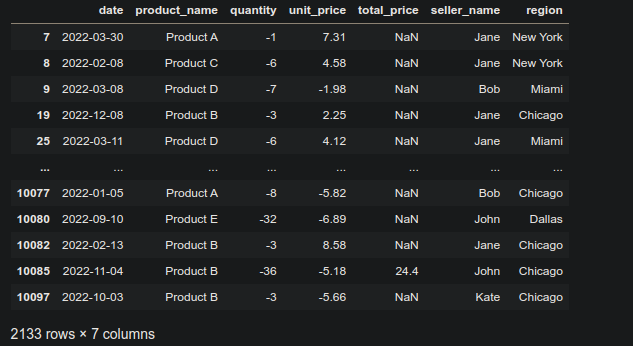
Эти значения будут преобразованы с помощью функции abc() , чтобы преобразовать отрицательные значения в столбцах. Это позволит получить абсолютные значения и избавиться от знака минус.
Таким же образом мы поступим unit_price.

Заменяем отрицательные значения на положительные.
Обработаем столбец total_price . В задаче указано, что total_price представляет собой общую стоимость продукта, которая равна произведению количества и цены за единицу. Значит, мы можем заполнить пустые значения в этом столбце, умножив значение quantity на значение unit_price . Так и поступим.
df.loc[df['total_price'].isna(), 'total_price'] = df['quantity'] * df['unit_price']Данные содержат некоторое количество дубликатов, которые необходимо удалить в соответствии с заданием.

df = df.drop(df[df.duplicated()].index)Проверим категориальные переменные.



Все значения категориальных переменных в порядке. Осталось только сохранить данные в csv. В этом нам поможет функция to_csv() .
df.to_csv('processed_data.csv',index=False, header=True)В результате мы получим файл processed_data.csv .
Заключение
Такое задание позволяет закрепить навыки работы с pandas, например, загрузка данных из файла, очистка данных от дубликатов и пропусков, изменение типов данных столбцов и обработка пропущенных значений. Задание также поможет новичкам овладеть принципами анализа данных, включая методы pandas для анализа данных.
В скором времени я планирую выложить разбор реальной задачи для продуктового аналитика, который поможет вам лучше понять, как применять знания и навыки, полученные в процессе изучения данной темы. Я надеюсь, что этот материал будет интересен и полезен для вас, и вы сможете успешно применить полученные знания на практике. Буду благодарен за ваши комментарии! Спасибо!