- Работа с библиотекой requests: Получение HTML-кода страницы
- Установка библиотеки requests
- Получение HTML-кода страницы
- Обработка ошибок
- Заключение
- Библиотека Requests: эффективные и простые HTTP-запросы в Python
- 1. Основные возможности библиотеки Requests
- Как получить полный html код страницы с помощью requests.get()?
Работа с библиотекой requests: Получение HTML-кода страницы
Библиотека requests — это библиотека языка Python, которая позволяет отправлять HTTP-запросы и получать ответы. Она может использоваться для взаимодействия с API, автоматизации браузеров и скачивания сайтов. В этой статье мы рассмотрим получение HTML-кода страницы с помощью библиотеки requests.
Установка библиотеки requests
Перед началом работы с библиотекой requests ее нужно установить. Для этого необходимо запустить команду:
Получение HTML-кода страницы
Для получения HTML-кода страницы с помощью библиотеки requests необходимо выполнить следующие шаги:
url = 'https://www.example.com' response = requests.get(url) Полный код получения HTML-кода страницы выглядит следующим образом:
import requests url = 'https://www.example.com' response = requests.get(url) html_code = response.text print(html_code) Обработка ошибок
При получении HTML-кода страницы с помощью библиотеки requests могут возникнуть ошибки. Например, страница может быть недоступна (ошибка 404), сервер может не ответить (ошибка 500) или запрос может превысить лимит времени (ошибка Timeout).
Для обработки ошибок можно использовать блок try/except:
import requests url = 'https://www.example.com' try: response = requests.get(url) except requests.exceptions.RequestException as e: print(e) sys.exit(1) html_code = response.text print(html_code) В этом случае, если при выполнении GET-запроса возникнет ошибка, программа выведет сообщение об ошибке и завершит свою работу.
Заключение
В этой статье мы рассмотрели, как получить HTML-код страницы с помощью библиотеки requests. Также мы рассмотрели, как обработать ошибки, которые могут возникнуть при получении HTML-кода. Библиотека requests является мощным инструментом для взаимодействия с интернет-ресурсами и может быть использована в широком спектре задач, связанных с автоматизацией браузеров и скачиванием сайтов.
Библиотека Requests:
эффективные и простые
HTTP-запросы в Python
Модуль Requests предоставляет возможность управления HTTP-запросами при помощи языка Python. Инструментарий библиотеки широкий и рассчитан на все случаи взаимодействия с web-приложениями. Код, написанный с применением Requests , не является громоздким, легко читается, а функции и методы наглядно настраиваются под специфические нужды.
Несмотря на то, что в Python встроен модуль urllib3 , обладающий сходным функционалом, практически все применяют Requests , что свидетельствует о его удобстве и простоте.
1. Основные возможности библиотеки Requests
Модуль разработан с учетом потребностей современных web-разработчиков и актуальных технологий. Многие операции автоматизированы, а ручные настройки сведены к минимуму.
Для понимания инструментария библиотеки перечислим ее основные возможности:
– поддержка постоянного HTTP-соединения и его повторное использование;
– применение международных и национальных доменов;
– использование Cookie : передача и получение значений в формате ключ: значение ;
– автоматическое декодирование контента;
– SSL верификация;
– аутентификация пользователей на большинстве ресурсов с сохранением;
– поддержка proxy при необходимости;
– загрузка и выгрузка файлов;
– стриминговые загрузки и фрагментированные запросы;
– задержки соединений;
– передача требуемых заголовков на web-ресурсы и др.
В целом, практически любая задача, которая возникает у разработчика, нашла свое отражение в коде библиотеки. Важно понимать, что Requests не предназначен для парсинга ответа сервера (для этого применяют другие модули, например, Beautiful Soup ).
Как получить полный html код страницы с помощью requests.get()?

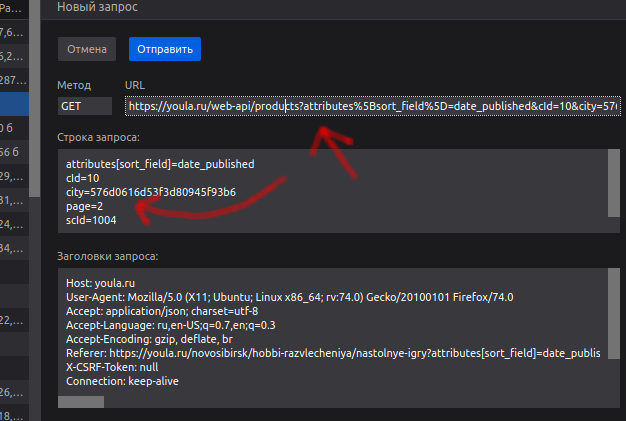
Откройте инструменты разработчика и полистайте страницу вниз. Обратите внимание на url и параметр page:
не могли бы показать полный скриншот или сделать похожий?
возникла проблема с парсингом страниц вида https://www.vfbank.ru/fizicheskim-licam/monety/pam.
'BX-ACTION-TYPE':'get_dynamic', 'BX-CACHE-MODE':'HTMLCACHE',на выходе получите что-то похожее на json. Эти данные я прогнал через online сервисы, они определили что это json, только с кучей ошибок. Я немного схитрил, и вырезал нужные мне данные и удалил из них не нужные символы.
import requests from bs4 import BeautifulSoup headers = url = 'https://www.vfbank.ru/fizicheskim-licam/monety/pamyatnye-monety/' def parsing(html): start = html.find('bxdynamic_moneti_inner') end = html.find("'HASH':'844584f9f4f7',") data = html[start:end].replace('\\n','').replace('\\','') soup = BeautifulSoup(data,"html.parser") coins = soup.find_all('div',class_='col col--lg-6') for coin in coins: title = coin.find('a').text.strip() _id = coin.find('a').get('data-id') print(title,_id) response = requests.get(url,headers=headers) parsing(response.text) 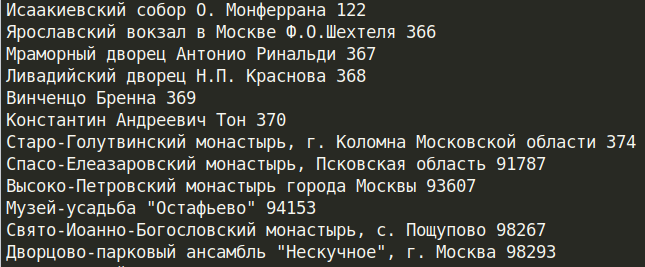
sunsexsurf, Теперь, зная id монеты, сможем узнать всю информацию о ней, просто передав get-запрос по адресу
https://www.vfbank.ru/local/ajax/moneta.php?ELEMENT_ID=import requests from bs4 import BeautifulSoup headers = url = 'https://www.vfbank.ru/local/ajax/moneta.php?ELEMENT_ID=' def parsing(_id): response = requests.get(url+_id,headers=headers) soup = BeautifulSoup(response.text,"html.parser") title = soup.find('h3').text.strip() full_content = soup.find('div',class_='coin-content__info coin-content-info coin-content-info--b-offset') contents = full_content.find_all('div',class_='coin-content-info__item coin-content-info__item--b-offset') print(title+'\n') for content in contents: _key = content.find('span',class_='coin-content-info__key').text.strip() val = content.find('span',class_='coin-content-info__val').text.strip() print(_key+' = '+ val) parsing('370') # id монеты