- How to extract tables from PDF using Python Pandas and tabula-py
- A quick and ready script to extract repetitive tables from PDF
- Extract Regions names
- Extract Table from PDF using Python
- Method 1:
- Step 1: Import library and define file path
- Step 2: Extract table from PDF file
- Step 3: Write dataframe to CSV file
- Method 2:
- Extract multiple tables from a single page of PDF using Python
- Extract all tables from PDF using Python
- Conclusion
- How to Extract Table from PDF with Python and Pandas
- 1: Extract tables from PDF with Python
- 2: Extract tables from PDF — keep format
- 2.1 Convert PDF to HTML
- 2.2 Extract tables with Pandas
- 2.3 HTMLTableParser
- 3. Python Libraries for extraction from PDF files
- 3.1 Python PDF parsing
- 3.2 Parse HTML tables
- 3.3 Example PDF files
How to extract tables from PDF using Python Pandas and tabula-py
A quick and ready script to extract repetitive tables from PDF
This tutorial is an improvement of my previous post, where I extracted multiple tables without Python pandas . In this tutorial, I will use the same PDF file, as that used in my previous post, with the difference that I manipulate the extracted tables with Python pandas .
The code of this tutorial can be downloaded from my Github repository.
Almost all the pages of the analysed PDF file have the following structure:
In the top-right part of the page, there is the name of the Italian region, while in the bottom-right part of the page there is a table.
I want to extract both the region names and the tables for all the pages. I need to extract the bounding box for both the tables. The full procedure to measure margins is illustrated in my previous post, section Define margins.
This script implements the following steps:
- define the bounding box, which is represented through a list with the following shape: [top,left,bottom,width] . Data within the bounding box are expressed in cm. They must be converted to PDF points, since tabula-py requires them in this format. We set the conversion factor fc = 28.28 .
- extract data using the read_pdf() function
- save data to a pandas dataframe.
In this example, we scan the pdf twice: firstly to extract the regions names, secondly, to extract tables. Thus we need to define two bounding boxes.
Extract Regions names
Firstly, I define the bounding box to extract the regions:
box = [1.5, 22,3.8,26.741]
fc = 28.28
for i in range(0, len(box)):
box[i] *= fc Extract Table from PDF using Python

In this tutorial we will discuss how to extract table from PDF files using Python.
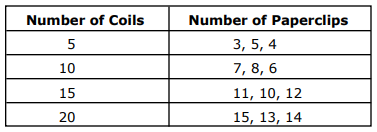
We know that it is on the first page of the PDF file. Now we can extract it to CSV or DataFrame using Python:
Method 1:
Step 1: Import library and define file path
Step 2: Extract table from PDF file
The above code reads the first page of the PDF file, searching for tables, and appends each table as a DataFrame into a list of DataFrames dfs.
Here we expected only a single table, therefore the length of the dfs list should be 1:
You can also validate the result by displaying the contents of the first element in the list:
Number of Coils Number of Paperclips 0 5 3, 5, 4 1 10 7, 8, 6 2 15 11, 10, 12 3 20 15, 13, 14 Step 3: Write dataframe to CSV file
Simply write the DataFrame to CSV in the same directory:
Method 2:
This method will produce the same result, and rather than going step-by-step, the library provides a one-line solution:
Both of the above methods are easy to use when you are sure that there is only one table on a particular page.
In the next section we will explore how to adjust the code when working with multiple tables.
Extract multiple tables from a single page of PDF using Python
We want to extract the tables below:
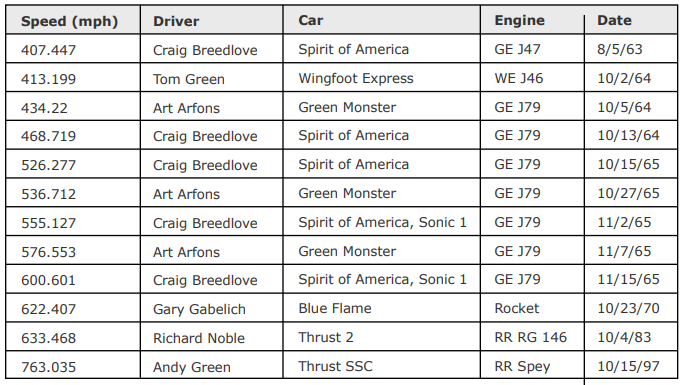
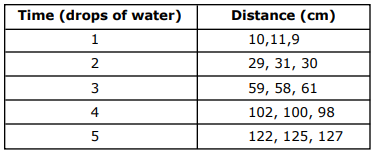
Using Method 1 from the previous section, we can extract each table as a DataFrame and create a list of DataFrames:
Notice that in this case we set pages=’2′, since we are extracting tables from page 2 of the PDF file.
Check that the list contains two DataFrames:
Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
and you should get two CSV files: table_0.csv and table_1.csv.
Note: if you try to use Method 2 described in the previous section, it will extract the 2 tables into a single worksheet in the CSV file and you would need to break it up into two worksheets manually.
Extract all tables from PDF using Python
In the above sections we focused on extracting tables from a given single page (page 1 or page 2). Now what do we do if we simply want to get all of the tables from the PDF file into different CSV files?
It is easily solvable with tabula-py library. The code is almost identical to the previous part. The only change we would need to do is set pages=’all’, so the code extracts all of the tables it finds as DataFrames and creates a list with them:
Check that the list contains all three DataFrames:
Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
Conclusion
In this article we discussed how to extract table from PDF files using tabula-py library.
How to Extract Table from PDF with Python and Pandas
In this short tutorial, we’ll see how to extract tables from PDF files with Python and Pandas.
We will cover two cases of table extraction from PDF:
(1) Simple table with tabula-py
from tabula import read_pdf df_temp = read_pdf('china.pdf') (2) Table with merged cells
import pandas as pd html_tables = pd.read_html(page) Let’s cover both examples in more detail as context is important.
1: Extract tables from PDF with Python
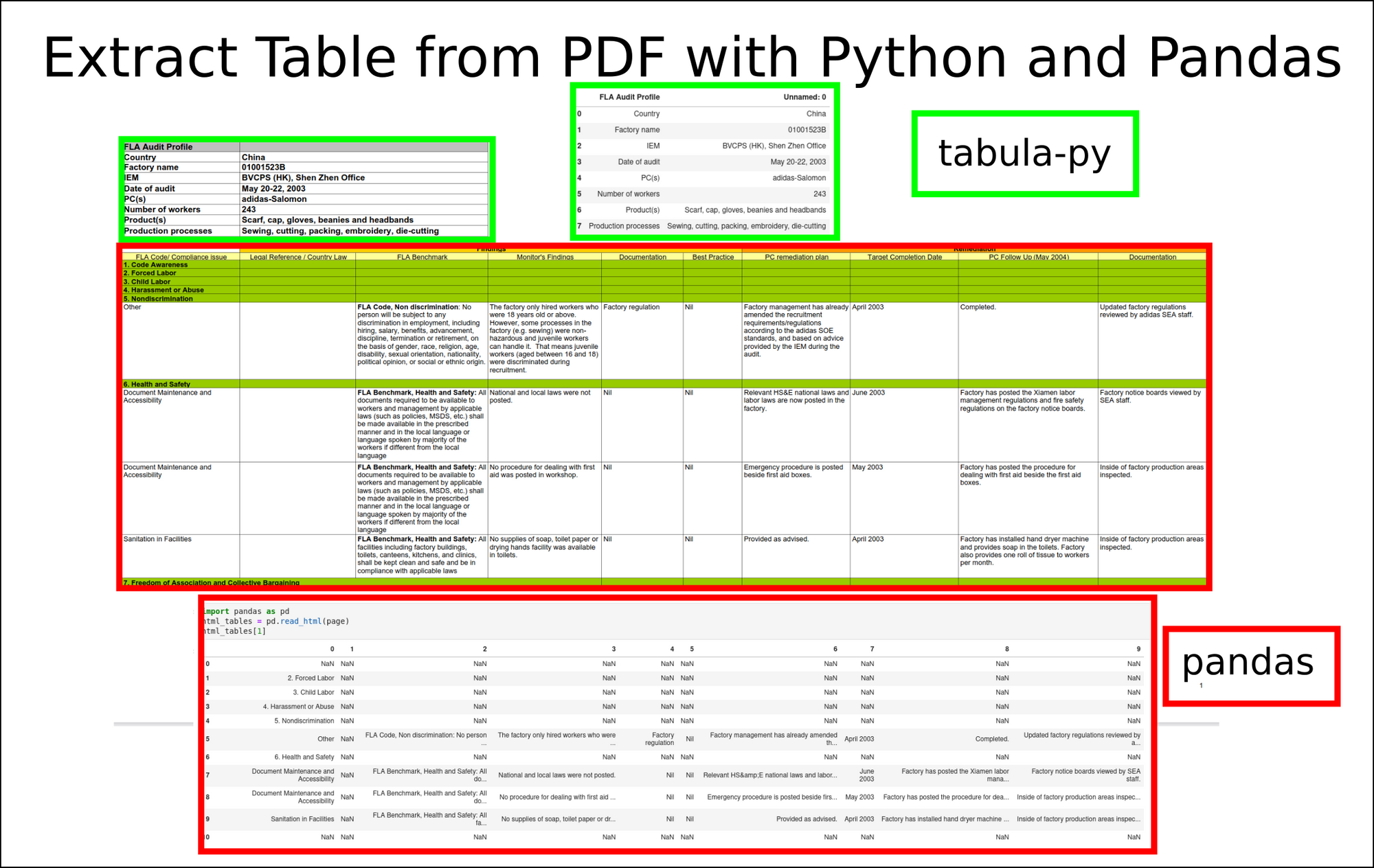
In this example we will extract multiple tables from remote PDF file: china.pdf.
We will use library called: tabula-py which can be installed by:
The .pdf file contains 2 table:
from tabula import read_pdf file = 'https://raw.githubusercontent.com/tabulapdf/tabula-java/master/src/test/resources/technology/tabula/china.pdf' df_temp = read_pdf(file, stream=True) After reading the data we can get a list of DataFrames which contain table data.
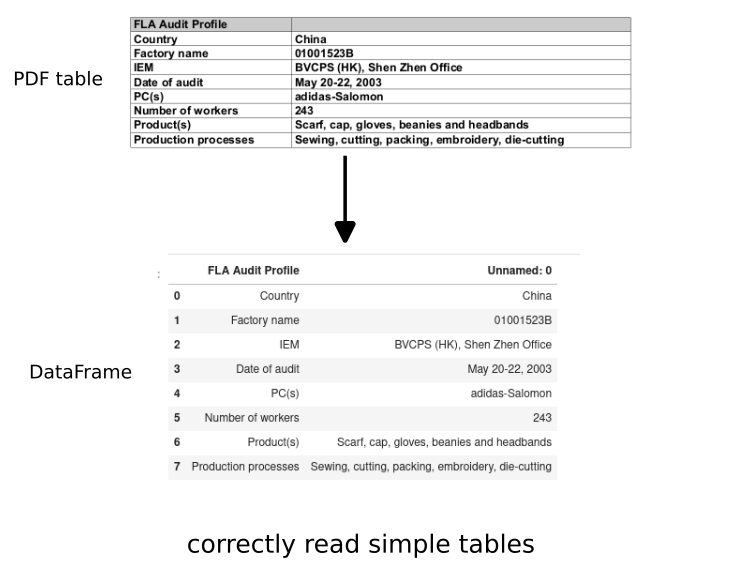
| FLA Audit Profile | Unnamed: 0 | |
|---|---|---|
| 0 | Country | China |
| 1 | Factory name | 01001523B |
| 2 | IEM | BVCPS (HK), Shen Zhen Office |
| 3 | Date of audit | May 20-22, 2003 |
| 4 | PC(s) | adidas-Salomon |
| 5 | Number of workers | 243 |
| 6 | Product(s) | Scarf, cap, gloves, beanies and headbands |
| 7 | Production processes | Sewing, cutting, packing, embroidery, die-cutting |
Which is the exact match of the first table from the PDF file.
While the second one is a bit weird. The reason is because of the merged cells which are extracted as NaN values:
| Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Findings | Unnamed: 3 | |
|---|---|---|---|---|---|
| 0 | FLA Code/ Compliance issue | Legal Reference / Country Law | FLA Benchmark | Monitor’s Findings | NaN |
| 1 | 1. Code Awareness | NaN | NaN | NaN | NaN |
| 2 | 2. Forced Labor | NaN | NaN | NaN | NaN |
| 3 | 3. Child Labor | NaN | NaN | NaN | NaN |
| 4 | 4. Harassment or Abuse | NaN | NaN | NaN | NaN |
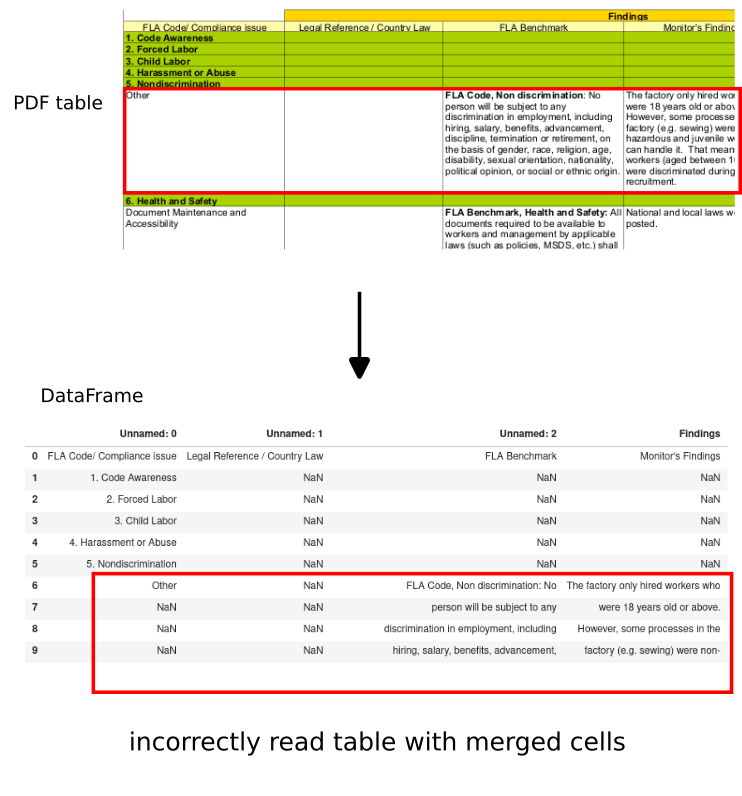
How to workaround this problem we will see in the next step.
Some cells are extracted to multiple rows as we can see from the image:
2: Extract tables from PDF — keep format
Often tables in PDF files have:
Most libraries and software are not able to extract them in a reliable way.
To extract complex table from PDF files with Python and Pandas we will do:
- download the file (it’s possible without download)
- convert the PDF file to HTML
- extract the tables with Pandas
2.1 Convert PDF to HTML
First we will download the file from: china.pdf.
Then we will convert it to HTML with the library: pdftotree.
import pdftotree page = pdftotree.parse('china.pdf', html_path=None, model_type=None, model_path=None, visualize=False) library can be installed by:
2.2 Extract tables with Pandas
Finally we can read all the tables from this page with Pandas:
import pandas as pd html_tables = pd.read_html(page) html_tables[1] Which will give us better results in comparison to tabula-py

2.3 HTMLTableParser
As alternatively to Pandas, we can use the library: html-table-parser-python3 to parse the HTML tables to Python lists.
from html_table_parser.parser import HTMLTableParser p = HTMLTableParser() p.feed(page) print(p.tables[0]) it convert the HTML table to Python list:
[['', ''], ['Country', 'China'], ['Factory name', '01001523B'], ['IEM', 'BVCPS (HK), Shen Zhen Office'], ['Date of audit', 'May 20-22, 2003'], ['PC(s)', 'adidas-Salomon'], ['Number of workers', '243'], ['Product(s)', 'Scarf, cap, gloves, beanies and headbands']] Now we can convert the list to Pandas DataFrame:
import pandas as pd pd.DataFrame(p.tables[1]) To install this library we can do:
pip install html-table-parser-python3 There are two differences to Pandas:
3. Python Libraries for extraction from PDF files
Finally let’s find a list of useful Python libraries which can help in PDF parsing and extraction:
3.1 Python PDF parsing
3.2 Parse HTML tables
- html-table-parser-python3 — parse HTML tables with Python 3 to list of values
- tablextract — extracts the information represented in any HTML table
- pdftotree — convert PDF into hOCR with text, tables, and figures being recognized and preserved.
- pandas.read_html
- html-table-extractor — A python library for extracting data from html table
- py-html-table — Python library to extract data from HTML Tables with rowspan
3.3 Example PDF files
Finally you can find example PDF files where you can test table extraction with Python and Pandas:
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.