- Parsing URL in Python
- Parsing Urls
- Quoting URL
- Manipulating Query Parameter
- Related Posts
- Python parse url params
- # Parse a URL query string to get query parameters in Python
- # Getting a dictionary containing the URL’s query parameters
- # Keeping query parameters without values in the results
- # Additional Resources
Parsing URL in Python
Urllib module in Python is used to access, and interact with, websites using URL (Uniform Resource Locator). A URL (colloquially termed a web address) is a reference to a web resource that specifies its location on a computer network and a mechanism for retrieving it.
Urilib has below modules for working with URL
- urllib.request for opening and reading URLs
- urllib.error containing the exceptions raised by urllib.request
- urllib.parse for parsing URLs
- urllib.robotparser for parsing robots.txt files
Parsing Urls
urllib.parse module defines interface to break URL strings up in components (addressing scheme, network location, path etc.), to combine the components back into a URL string.
urlparse() parse a URL into six components. urlsplit() is similar to urlparse(), but does not split the params from the URL. For example:
import urllib.parse sample_url = "http://example.com:8080/example.html?val1=1&val2=Hello" # Parse URL with urlparse() result = urllib.parse.urlparse(sample_url) print(result) # Output # ParseResult(scheme='http', netloc='example.com:8080', path='/example.html', params='', query='val1=1&val2=Hello', fragment='') print("Scheme : " + result.scheme) print("HostName : " + result.hostname) print("Path : " + result.path) # Output # Scheme : http # HostName : example.com # Path : /example.html print(result.geturl()) # Output # http://example.com:8080/example.html?val1=1&val2=Hello result = urllib.parse.urlsplit(sample_url) print(result) # Output # SplitResult(scheme='http', netloc='example.com:8080', path='/example.html', query='val1=1&val2=Hello', fragment='') urljoin() construct a absolute URL by combining a base URL with another URL. It uses addressing scheme, the network location to provide missing components in the relative URL. For example:
import urllib.parse # Join URL with urljoin() print(urllib.parse.urljoin('http://example.com:8080/example.html', 'FAQ.html')) # Output # http://example.com:8080/FAQ.html Quoting URL
URL quoting module provides functions to make program data safe for use as URL components by quoting special characters and appropriately encoding non-ASCII text. It also support reversing these operations to recreate the original data from the contents of a URL component.
quote() function replace special characters in string using the %xx escape. It is intended for quoting the path section of URL. quote_plus() is similar to quote(), but it replace spaces by plus signs. Plus signs in the original string are escaped unless they are included in safe. To get back the URL from the quoted url, use unquote(). It %xx escapes by their single-character equivalent. unquote_plus() is similar to unquote(), but also replace plus signs by spaces, as required for unquoting HTML form values. Syntax of above functions
quote(string, safe='/', encoding=None, errors=None) quote_plus(string, safe='', encoding=None, errors=None) unquote(string, encoding='utf-8', errors='replace') unquote_plus(string, encoding='utf-8', errors='replace')
Following example demonstrate quoting of program data, so that they can be used as component of URL.
import urllib.parse sample_string = "Hello El Niño" # Replaces special characters for use in URLs quoteStr = urllib.parse.quote(sample_string) print(quoteStr) # Output # Hello%20El%20Ni%C3%B1o # Replaces special characters for use in URLs quotePlusStr = urllib.parse.quote_plus(sample_string) print(quotePlusStr) # Output # Hello+El+Ni%C3%B1o # Get back actual string from quoted string print(urllib.parse.unquote(quoteStr)) # Output # Hello El Niño print(urllib.parse.unquote_plus(quotePlusStr)) # Output # Hello El Niño
Manipulating Query Parameter
urlencode() convert a mapping object or a sequence of two-element tuples to a percent-encoded ASCII text string. It returns string containing series of key=value pairs separated by ‘&’ characters, where both key and value are quoted. The order of parameters in the encoded string will match the order of parameter tuples in the sequence. To reverse encoding process, use parse_qs() and parse_qsl() to parse query strings into Python data structures. Syntax of the function are
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus) urllib.parse.parse_qs(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace', max_num_fields=None) urllib.parse.parse_qsl(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace', max_num_fields=None)
parse_qs() parse a query string given as a string argument and returns a dictionary. Dictionary keys are the unique query variable names and the values are lists of values for each name. parse_qsl() parse a query string given as a string argument and returs as a list of name, value pairs.
import urllib.parse # Use urlencode() to convert maps to parameter strings query_data = < 'name': "Mango", "type": "Fruit", "price": 37 >result = urllib.parse.urlencode(query_data) print(result) # Output # name=Mango&type=Fruit&price=37 print(urllib.parse.parse_qs(result)) # Output # print(urllib.parse.parse_qsl(result)) # Output # [('name', 'Mango'), ('type', 'Fruit'), ('price', '37')] Related Posts
Python parse url params
Last updated: Feb 19, 2023
Reading time · 2 min

# Parse a URL query string to get query parameters in Python
To parse a URL query string and get query parameters:
- Import the urlparse and parse_qs methods from the urllib.parse module.
- Use the urlparse method to get a parse result object.
- Pass the object to the parse_qs method to get a dictionary of the query params.
Copied!from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC' parse_result = urlparse(url) # 👇️ "page=10&limit=15&price=ASC" print(parse_result) dict_result = parse_qs(parse_result.query) # 👇️ print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ 'ASC'
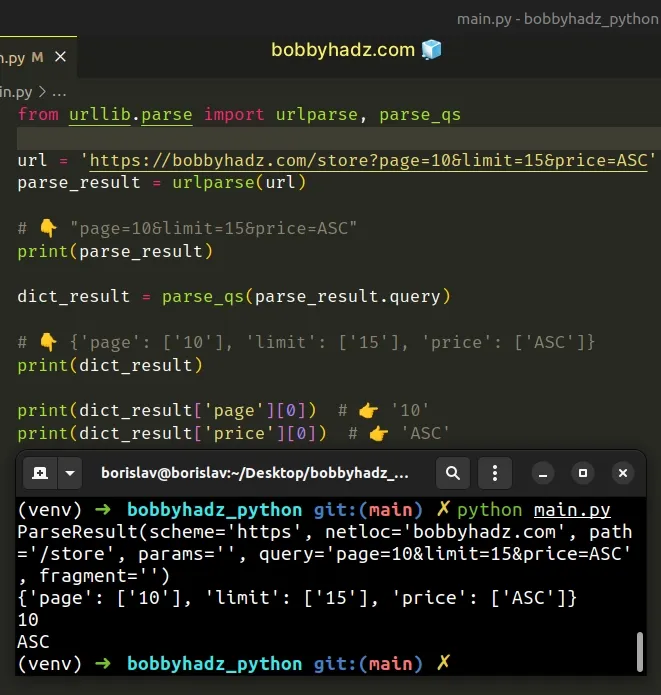
We used the urlparse and parse_qs methods from the urllib.parse module to parse a URL query string.
The urlparse method takes a URL and parses it into six components.
Copied!from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC' parse_result = urlparse(url) # 👇️ ParseResult(scheme='https', netloc='bobbyhadz.com', path='/store', params='', query='page=10&limit=15&price=ASC', fragment='') print(parse_result) # 👇️ page=10&limit=15&price=ASC print(parse_result.query)
We can access the query attribute on the object to get the query string.
Notice that other components like path and fragment are also available.
Copied!from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC#my-fragment' parse_result = urlparse(url) # 👇️ page=10&limit=15&price=ASC print(parse_result.query) # 👇️ /store print(parse_result.path) # 👇️ my-fragment print(parse_result.fragment)
# Getting a dictionary containing the URL’s query parameters
After we parse the URL and get the query string, we can pass the string to the parse_qs method to get a dictionary containing the URL’s query parameters.
Copied!from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC#my-fragment' parse_result = urlparse(url) # 👇️ "page=10&limit=15&price=ASC" print(parse_result) dict_result = parse_qs(parse_result.query) # 👇️ print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ 'ASC'
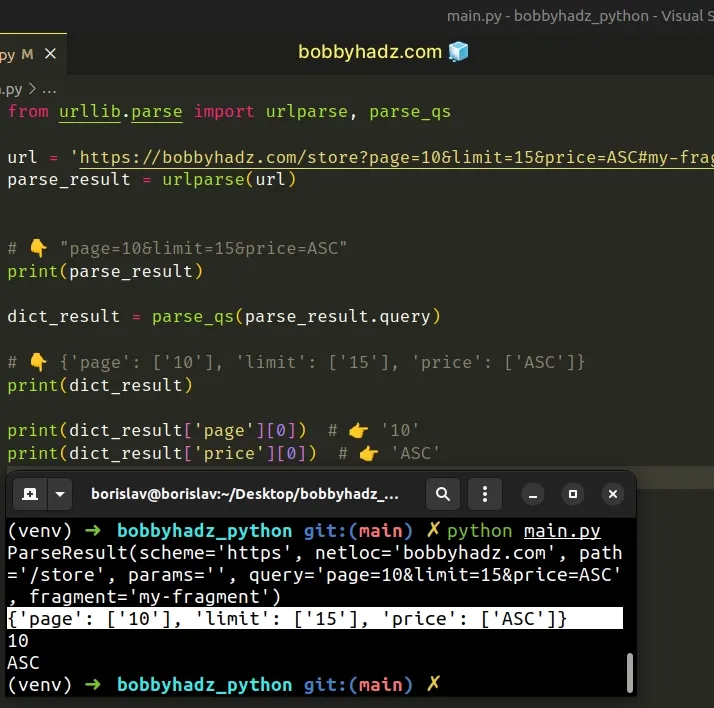
The parse_qs method parses the given query string and returns the results as a dictionary.
The dictionary keys are the names of the query parameters and the values are lists that store the values for each parameter.
You first have to access a key in the dictionary and then have to access the list item at the specific index (most likely 0 unless you have a query param with multiple values).
# Keeping query parameters without values in the results
If your URL has query parameters without values that you want to keep in the results, set the keep_blank_values argument to True when calling parse_qs .
Copied!from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price' parse_result = urlparse(url) print(parse_result) dict_result = parse_qs(parse_result.query, keep_blank_values=True) # 👇️ print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ ""
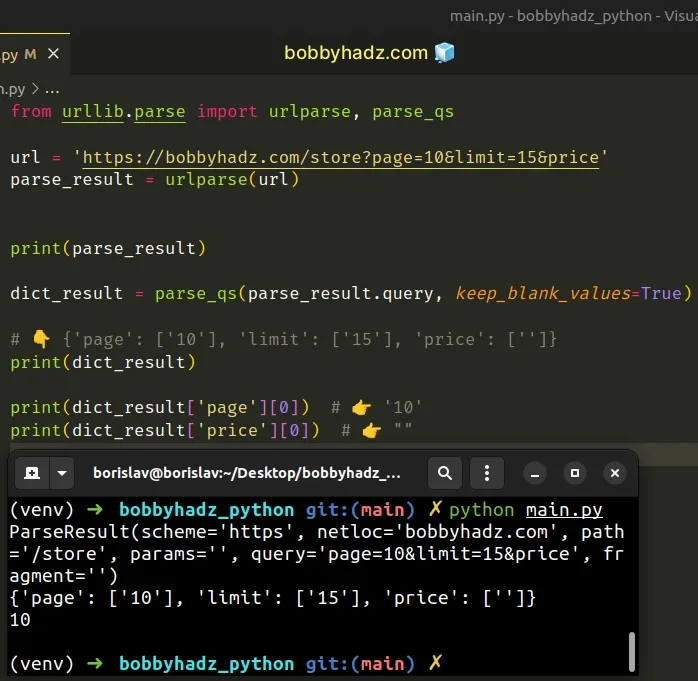
Even though the price query parameter doesn’t have a value specified, it is still included in the dictionary if keep_blank_values is set to True .
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.