- pandas.DataFrame.drop_duplicates#
- Drop duplicates in pandas DataFrame
- Table of contents
- The DataFrame.drop_duplicates() function
- Drop duplicates but keep first
- Drop duplicates from defined columns
- Drop duplicates but keep last
- Drop all duplicates
- Drop duplicates in place
- Drop duplicates and reset the index
- About Vishal
- Related Tutorial Topics:
- Python Exercises and Quizzes
- Pandas: как удалить дубликаты в нескольких столбцах
- Пример 1. Удаление дубликатов по всем столбцам
- Пример 2. Удаление дубликатов по определенным столбцам
- Дополнительные ресурсы
- Как удалить повторяющиеся строки в Pandas DataFrame
- Пример 1. Удаление дубликатов во всех столбцах
- Пример 2. Удаление дубликатов в определенных столбцах
pandas.DataFrame.drop_duplicates#
Considering certain columns is optional. Indexes, including time indexes are ignored.
Parameters subset column label or sequence of labels, optional
Only consider certain columns for identifying duplicates, by default use all of the columns.
keep , default ‘first’
Determines which duplicates (if any) to keep.
- ‘first’ : Drop duplicates except for the first occurrence.
- ‘last’ : Drop duplicates except for the last occurrence.
- False : Drop all duplicates.
Whether to modify the DataFrame rather than creating a new one.
ignore_index bool, default False
If True , the resulting axis will be labeled 0, 1, …, n — 1.
Returns DataFrame or None
DataFrame with duplicates removed or None if inplace=True .
Count unique combinations of columns.
Consider dataset containing ramen rating.
>>> df = pd.DataFrame( . 'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'], . 'style': ['cup', 'cup', 'cup', 'pack', 'pack'], . 'rating': [4, 4, 3.5, 15, 5] . >) >>> df brand style rating 0 Yum Yum cup 4.0 1 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0
By default, it removes duplicate rows based on all columns.
>>> df.drop_duplicates() brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0
To remove duplicates on specific column(s), use subset .
>>> df.drop_duplicates(subset=['brand']) brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5
To remove duplicates and keep last occurrences, use keep .
>>> df.drop_duplicates(subset=['brand', 'style'], keep='last') brand style rating 1 Yum Yum cup 4.0 2 Indomie cup 3.5 4 Indomie pack 5.0
Drop duplicates in pandas DataFrame
In this article, we learn to remove duplicates from the pandas DataFrame.
Data is gathered from various sources. It may not be in the proper form. It contains garbage values and duplicate data. Before analyzing a dataset, it must be clean and precise.
Table of contents
The DataFrame.drop_duplicates() function
This function is used to remove the duplicate rows from a DataFrame.
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)- subset : By default, if the rows have the same values in all the columns, they are considered duplicates. This parameter is used to specify the columns that only need to be considered for identifying duplicates.
- keep : Determines which duplicates (if any) to keep. It takes inputs as,
first – Drop duplicates except for the first occurrence. This is the default behavior.
last – Drop duplicates except for the last occurrence.
False – Drop all duplicates. - inplace : It is used to specify whether to return a new DataFrame or update an existing one. It is a boolean flag with default False.
- ignore_index : It is a boolean flag to indicate if row index should be reset after dropping duplicate rows. False: It keeps the original row index. True: It reset the index, and the resulting rows will be labeled 0, 1, …, n – 1.
It returns the DataFrame with dropped duplicates or None if inplace=True
Drop duplicates but keep first
When we have the DataFrame with many duplicate rows that we want to remove we use DataFrame.drop_duplicates() .
The rows that contain the same values in all the columns then are identified as duplicates. If the row is duplicated then by default DataFrame.drop_duplicates() keeps the first occurrence of that row and drops all other duplicates of it.
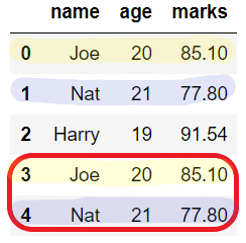
import pandas as pd student_dict = # Create DataFrame from dict student_df = pd.DataFrame(student_dict) print(student_df) # drop duplicate rows student_df = student_df.drop_duplicates() print(student_df) Before dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54 3 Joe 20 85.10 4 Nat 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54
Drop duplicates from defined columns
By default, DataFrame.drop_duplicate() removes rows with the same values in all the columns. But, we can modify this behavior using a subset parameter.
For example, subset=[col1, col2] will remove the duplicate rows with the same values in specified columns only, i.e., col1 and col2.
In the below example, rows for ‘Nat’ and ‘Sam’ are removed even though their names are different because only ‘age‘ and ‘marks‘ columns are considered to check for duplicates.
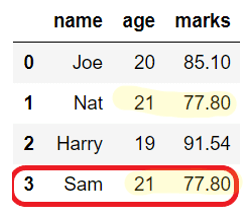
import pandas as pd student_dict = <"name":["Joe","Nat","Harry","Sam" ], "age":[20,21,19,21], "marks":[85.10, 77.80, 91.54, 77.80]># Create DataFrame from dict student_df = pd.DataFrame(student_dict) print(student_df) # drop duplicate rows student_df = student_df.drop_duplicates(subset=['age','marks']) print(student_df)Before dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54 3 Sam 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54
Drop duplicates but keep last
Let’s consider the case where we have a row that is duplicated multiple times in the DataSet. In such a case, To keep only one occurrence of the duplicate row, we can use the keep parameter of a DataFrame.drop_duplicate() , which takes the following inputs:
- first – Drop duplicates except for the first occurrence of the duplicate row. This is the default behavior.
- last – Drop duplicates except for the last occurrence of the duplicate row.
- False – Drop all the rows which are duplicate.
In the below example, we are dropping the last occurrence of the duplicate rows using keep=’last’ .
import pandas as pd student_dict = # Create DataFrame from dict student_df = pd.DataFrame(student_dict) print(student_df) # drop duplicate rows student_df = student_df.drop_duplicates(keep='last') print(student_df)Before dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54 3 Nat 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 2 Harry 19 91.54 3 Nat 21 77.80
Drop all duplicates
As explained in the above section, by default, DataFrame.drop_duplicates() keeps the duplicate row’s first occurrence and removes all others.
If we need to drop all the duplicate rows, then it can be done by using keep=False , as shown below.
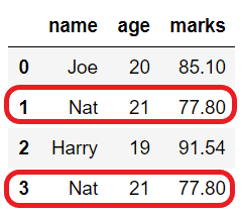
import pandas as pd student_dict = # Create DataFrame from dict student_df = pd.DataFrame(student_dict) print(student_df) # drop all duplicate rows student_df = student_df.drop_duplicates(keep=False) print(student_df) Before dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54 3 Nat 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 2 Harry 19 91.54
Drop duplicates in place
By default, DataFrame.drop_duplicates() removes the duplicates and returns the copy of the DataFrame.
But, if we want to make changes in the existing DataFrame, then set the flag inplace=True . It can be used when the drop operation is part of the function chaining.
import pandas as pd student_dict = # Create DataFrame from dict student_df = pd.DataFrame(student_dict) print(student_df) # drop duplicate rows student_df.drop_duplicates(inplace=True) print(student_df)Before dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54 3 Joe 20 85.10 4 Nat 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 1 Nat 21 77.80 2 Harry 19 91.54
Drop duplicates and reset the index
When we drop the rows from DataFrame, by default, it keeps the original row index as is. But, if we need to reset the index of the resultant DataFrame, we can do that using the ignore_index parameter of DataFrame.drop_duplicate() .
- If ignore_index=True , it reset the row labels of resultant DataFrame to 0, 1, …, n – 1.
- If ignore_index=False it does not change the original row index. By default, it is False.
import pandas as pd student_dict = # Create DataFrame from dict student_df = pd.DataFrame(student_dict, index=['a', 'b', 'c', 'd']) print(student_df) # drop duplicate rows student_df = student_df.drop_duplicates(keep=False, ignore_index=True) print(student_df) Before dropping duplicates: name age marks a Joe 20 85.10 b Nat 21 77.80 c Harry 19 91.54 d Nat 21 77.80 After dropping duplicates: name age marks 0 Joe 20 85.10 1 Harry 19 91.54
Did you find this page helpful? Let others know about it. Sharing helps me continue to create free Python resources.
About Vishal
I’m Vishal Hule, Founder of PYnative.com. I am a Python developer, and I love to write articles to help students, developers, and learners. Follow me on Twitter
Related Tutorial Topics:
Python Exercises and Quizzes
Free coding exercises and quizzes cover Python basics, data structure, data analytics, and more.
- 15+ Topic-specific Exercises and Quizzes
- Each Exercise contains 10 questions
- Each Quiz contains 12-15 MCQ
Pandas: как удалить дубликаты в нескольких столбцах
Вы можете использовать следующие методы для удаления повторяющихся строк в нескольких столбцах в кадре данных pandas:
Метод 1: удалить дубликаты во всех столбцах
Способ 2: удалить дубликаты в определенных столбцах
df.drop_duplicates(['column1', 'column3']) В следующих примерах показано, как использовать каждый метод на практике со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) region store sales 0 East 1 5 1 East 1 5 2 East 2 7 3 West 1 9 4 West 2 12 5 West 2 8 Пример 1. Удаление дубликатов по всем столбцам
В следующем коде показано, как удалить строки с повторяющимися значениями во всех столбцах:
#drop rows that have duplicate values across all columns df.drop_duplicates () region store sales 0 East 1 5 2 East 2 7 3 West 1 9 4 West 2 12 5 West 2 8 Строка в позиции индекса 1 имела те же значения во всех столбцах, что и строка в позиции индекса 0, поэтому она была удалена из DataFrame.
По умолчанию pandas сохраняет первую повторяющуюся строку. Тем не менее, вы можете использовать аргумент keep , чтобы вместо этого сохранить последнюю повторяющуюся строку:
#drop rows that have duplicate values across all columns (keep last duplicate) df.drop_duplicates (keep='last') region store sales 1 East 1 5 2 East 2 7 3 West 1 9 4 West 2 12 5 West 2 8 Пример 2. Удаление дубликатов по определенным столбцам
Вы можете использовать следующий код, чтобы удалить строки с повторяющимися значениями только в регионе и сохранить столбцы:
#drop rows that have duplicate values across region and store columns df.drop_duplicates(['region', 'store']) region store sales 0 East 1 5 2 East 2 7 3 West 1 9 4 West 2 12 В общей сложности две строки были удалены из DataFrame, поскольку они имели повторяющиеся значения в области и столбцах хранилища .
Примечание.Полную документацию по функции drop_duplicates() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как удалить повторяющиеся строки в Pandas DataFrame
Самый простой способ удалить повторяющиеся строки в кадре данных pandas — использовать функцию drop_duplicates() , которая использует следующий синтаксис:
df.drop_duplicates (подмножество = нет, сохранить = «первый», inplace = ложь)
- подмножество: какие столбцы следует учитывать для выявления дубликатов. По умолчанию все столбцы.
- keep: Указывает, какие дубликаты (если они есть) нужно сохранить.
- first: удалить все повторяющиеся строки, кроме первой.
- last: удалить все повторяющиеся строки, кроме последней.
- False : удалить все дубликаты.
- inplace: указывает, следует ли удалить дубликаты на месте или вернуть копию DataFrame.
В этом руководстве представлено несколько примеров практического использования этой функции в следующем кадре данных:
import pandas as pd #create DataFrame df = pd.DataFrame() #display DataFrame print(df) team points assists 0 a 3 8 1 b 7 6 2 b 7 7 3 c 8 9 4 c 8 9 5 d 9 3 Пример 1. Удаление дубликатов во всех столбцах
В следующем коде показано, как удалить строки с повторяющимися значениями во всех столбцах:
df.drop_duplicates () team points assists 0 a 3 8 1 b 7 6 2 b 7 7 3 c 8 9 5 d 9 3 По умолчанию функция drop_duplicates() удаляет все дубликаты, кроме первого.
Однако мы могли бы использовать аргумент keep=False для полного удаления всех дубликатов:
df.drop_duplicates (keep= False ) team points assists 0 a 3 8 1 b 7 6 2 b 7 7 5 d 9 3 Пример 2. Удаление дубликатов в определенных столбцах
В следующем коде показано, как удалить строки с повторяющимися значениями только в столбцах с названиями team и points :
df.drop_duplicates (subset=['team', 'points']) team points assists 0 a 3 8 1 b 7 6 3 c 8 9 5 d 9 3