- Python Pandas — Indexing and Selecting Data
- .loc()
- Example 1
- Example 2
- Example 3
- Example 4
- Example 5
- .iloc()
- Example 1
- Example 2
- Example 3
- .ix()
- Example 1
- Example 2
- Use of Notations
- Example 1
- Example 2
- Example 3
- Attribute Access
- Example
- How to select, filter, and subset data in Pandas dataframes
- Learn a range of useful techniques to select, filter, and subset data stored in Pandas dataframes to extract the exact information you need.
- Load the data
- Viewing the head, tail, and a sample
- Indexing and Selecting Data with Pandas
- Selecting some rows and some columns
- Selecting some rows and all columns
- Selecting some columns and all rows
- Pandas Indexing using [ ] , .loc[] , .iloc[ ] , .ix[ ]
- Selecting a single columns
Python Pandas — Indexing and Selecting Data
In this chapter, we will discuss how to slice and dice the date and generally get the subset of pandas object.
The Python and NumPy indexing operators «[ ]» and attribute operator «.» provide quick and easy access to Pandas data structures across a wide range of use cases. However, since the type of the data to be accessed isn’t known in advance, directly using standard operators has some optimization limits. For production code, we recommend that you take advantage of the optimized pandas data access methods explained in this chapter.
Pandas now supports three types of Multi-axes indexing; the three types are mentioned in the following table −
Both Label and Integer based
.loc()
Pandas provide various methods to have purely label based indexing. When slicing, the start bound is also included. Integers are valid labels, but they refer to the label and not the position.
.loc() has multiple access methods like −
- A single scalar label
- A list of labels
- A slice object
- A Boolean array
loc takes two single/list/range operator separated by ‘,’. The first one indicates the row and the second one indicates columns.
Example 1
#import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) #select all rows for a specific column print df.loc[:,'A']
Its output is as follows −
a 0.391548 b -0.070649 c -0.317212 d -2.162406 e 2.202797 f 0.613709 g 1.050559 h 1.122680 Name: A, dtype: float64
Example 2
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select all rows for multiple columns, say list[] print df.loc[:,['A','C']]
Its output is as follows −
A C a 0.391548 0.745623 b -0.070649 1.620406 c -0.317212 1.448365 d -2.162406 -0.873557 e 2.202797 0.528067 f 0.613709 0.286414 g 1.050559 0.216526 h 1.122680 -1.621420
Example 3
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select few rows for multiple columns, say list[] print df.loc[['a','b','f','h'],['A','C']]
Its output is as follows −
A C a 0.391548 0.745623 b -0.070649 1.620406 f 0.613709 0.286414 h 1.122680 -1.621420
Example 4
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select range of rows for all columns print df.loc['a':'h']
Its output is as follows −
A B C D a 0.391548 -0.224297 0.745623 0.054301 b -0.070649 -0.880130 1.620406 1.419743 c -0.317212 -1.929698 1.448365 0.616899 d -2.162406 0.614256 -0.873557 1.093958 e 2.202797 -2.315915 0.528067 0.612482 f 0.613709 -0.157674 0.286414 -0.500517 g 1.050559 -2.272099 0.216526 0.928449 h 1.122680 0.324368 -1.621420 -0.741470
Example 5
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # for getting values with a boolean array print df.loc['a']>0
Its output is as follows −
A False B True C False D False Name: a, dtype: bool
.iloc()
Pandas provide various methods in order to get purely integer based indexing. Like python and numpy, these are 0-based indexing.
The various access methods are as follows −
Example 1
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # select all rows for a specific column print df.iloc[:4]
Its output is as follows −
A B C D 0 0.699435 0.256239 -1.270702 -0.645195 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 3 0.539042 -1.284314 0.826977 -0.026251
Example 2
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Integer slicing print df.iloc[:4] print df.iloc[1:5, 2:4]
Its output is as follows −
A B C D 0 0.699435 0.256239 -1.270702 -0.645195 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 3 0.539042 -1.284314 0.826977 -0.026251 C D 1 -0.813012 0.631615 2 0.025070 0.230806 3 0.826977 -0.026251 4 1.423332 1.130568
Example 3
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Slicing through list of values print df.iloc[[1, 3, 5], [1, 3]] print df.iloc[1:3, :] print df.iloc[:,1:3]
Its output is as follows −
B D 1 0.890791 0.631615 3 -1.284314 -0.026251 5 -0.512888 -0.518930 A B C D 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 B C 0 0.256239 -1.270702 1 0.890791 -0.813012 2 -0.531378 0.025070 3 -1.284314 0.826977 4 -0.460729 1.423332 5 -0.512888 0.581409 6 -1.204853 0.098060 7 -0.947857 0.641358
.ix()
Besides pure label based and integer based, Pandas provides a hybrid method for selections and subsetting the object using the .ix() operator.
Example 1
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Integer slicing print df.ix[:4]
Its output is as follows −
A B C D 0 0.699435 0.256239 -1.270702 -0.645195 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 3 0.539042 -1.284314 0.826977 -0.026251
Example 2
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Index slicing print df.ix[:,'A']
Its output is as follows −
0 0.699435 1 -0.685354 2 -0.783192 3 0.539042 4 -1.044209 5 -1.415411 6 1.062095 7 0.994204 Name: A, dtype: float64
Use of Notations
Getting values from the Pandas object with Multi-axes indexing uses the following notation −
| Object | Indexers | Return Type |
|---|---|---|
| Series | s.loc[indexer] | Scalar value |
| DataFrame | df.loc[row_index,col_index] | Series object |
| Panel | p.loc[item_index,major_index, minor_index] | p.loc[item_index,major_index, minor_index] |
Note − .iloc() & .ix() applies the same indexing options and Return value.
Let us now see how each operation can be performed on the DataFrame object. We will use the basic indexing operator ‘[ ]’ −
Example 1
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df['A']
Its output is as follows −
0 -0.478893 1 0.391931 2 0.336825 3 -1.055102 4 -0.165218 5 -0.328641 6 0.567721 7 -0.759399 Name: A, dtype: float64
Note − We can pass a list of values to [ ] to select those columns.
Example 2
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df[['A','B']]
Its output is as follows −
A B 0 -0.478893 -0.606311 1 0.391931 -0.949025 2 0.336825 0.093717 3 -1.055102 -0.012944 4 -0.165218 1.550310 5 -0.328641 -0.226363 6 0.567721 -0.312585 7 -0.759399 -0.372696
Example 3
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df[2:2]
Its output is as follows −
Attribute Access
Columns can be selected using the attribute operator ‘.’.
Example
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df.A
Its output is as follows −
0 -0.478893 1 0.391931 2 0.336825 3 -1.055102 4 -0.165218 5 -0.328641 6 0.567721 7 -0.759399 Name: A, dtype: float64
How to select, filter, and subset data in Pandas dataframes
Learn a range of useful techniques to select, filter, and subset data stored in Pandas dataframes to extract the exact information you need.

Selecting, filtering and subsetting data is probably the most common task you’ll undertake if you work with data. It allows you to extract subsets of data where row or column values match specific parameters, or specific combinations of parameters, so it’s a key requirement for all forms of exploratory data analysis, data visualisation, and preprocessing for machine learning and modeling.
If, like me, you’ve come to Pandas from another platform, such as SQL, where you could write complex queries to select the data you wanted off the top of your head, getting to grips with the way you do this in Pandas can see a bit intimidating. However, when you break it down, it’s actually quite straightforward. Here are the main things you need to know to select and subset data from Pandas dataframes.
Load the data
For this project I’m using the Bank Marketing dataset, which you download from the UCI Machine Learning Repository. This is in a text format, but is separated with semicolons rather than commas. To load the data into a Pandas dataframe we’ll import the Pandas package with import pandas as pd and then use the pd.read_csv() to load the data into a dataframe called df . We’ll need to pass in the argument sep=»;» to tell Pandas to split the data correctly. As we only need a small number of columns, we can specifically define the ones to import with usecols .
import pandas as pd import numpy as np df = pd.read_csv('bank-full.csv', sep=";", usecols=['age','job','marital','education','balance','duration']) Viewing the head, tail, and a sample
Pandas includes three functions to allow you to quickly view the dataframe: head() , tail() , and sample() . By default head() and tail() return the first five rows from the top and bottom of the dataframe respectively, while sample() returns a single random row. Appending the function to the df will print the output. The first column in bold which lacks a header is the index.
| age | job | marital | education | balance | duration | |
|---|---|---|---|---|---|---|
| 0 | 58 | management | married | tertiary | 2143 | 261 |
| 1 | 44 | technician | single | secondary | 29 | 151 |
| 2 | 33 | entrepreneur | married | secondary | 2 | 76 |
| 3 | 47 | blue-collar | married | unknown | 1506 | 92 |
| 4 | 33 | unknown | single | unknown | 1 | 198 |
Indexing and Selecting Data with Pandas
Indexing in Pandas :
Indexing in pandas means simply selecting particular rows and columns of data from a DataFrame. Indexing could mean selecting all the rows and some of the columns, some of the rows and all of the columns, or some of each of the rows and columns. Indexing can also be known as Subset Selection.

Let’s see some example of indexing in Pandas. In this article, we are using “ nba.csv ” file to download the CSV, click here.
Selecting some rows and some columns
Let’s take a DataFrame with some fake data, now we perform indexing on this DataFrame. In this, we are selecting some rows and some columns from a DataFrame. Dataframe with dataset.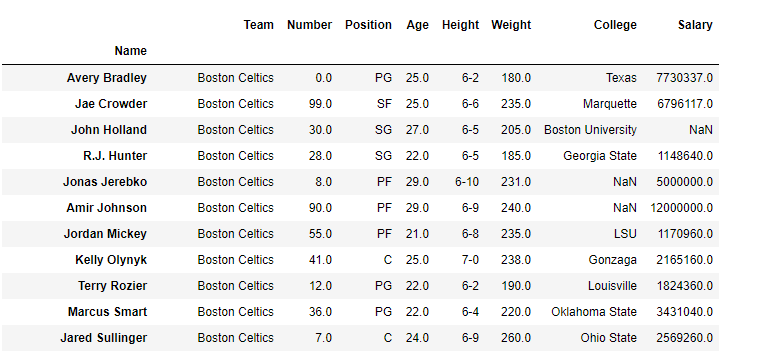
Suppose we want to select columns Age , College and Salary for only rows with a labels Amir Johnson and Terry Rozier 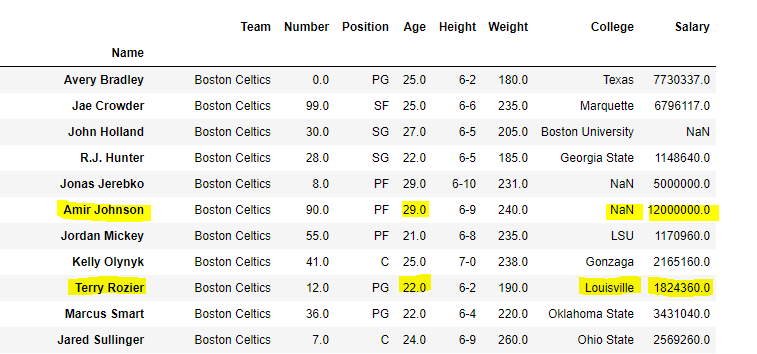
Our final DataFrame would look like this: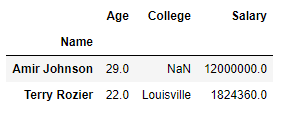
Selecting some rows and all columns
Let’s say we want to select row Amir Jhonson , Terry Rozier and John Holland with all columns in a dataframe.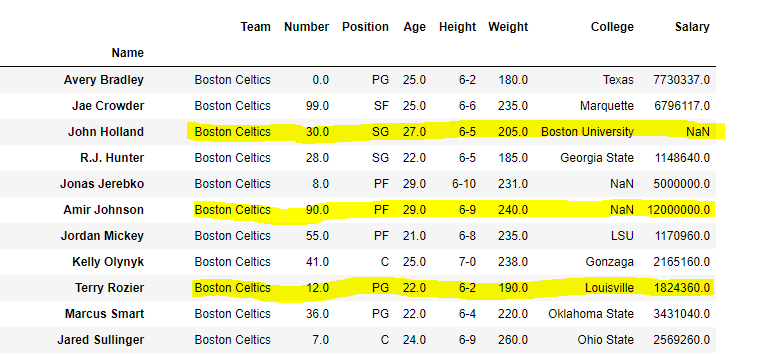
Our final DataFrame would look like this: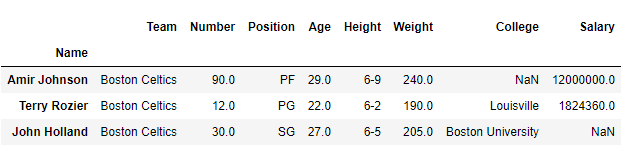
Selecting some columns and all rows
Let’s say we want to select columns Age, Height and Salary with all rows in a dataframe.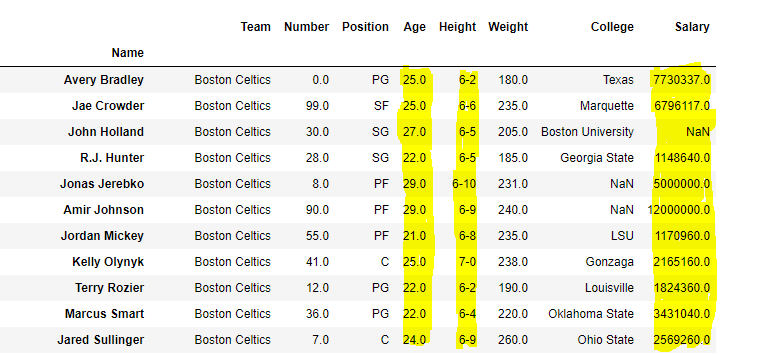
Our final DataFrame would look like this: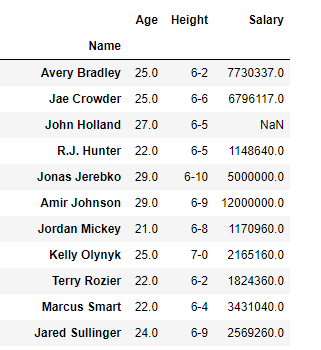
Pandas Indexing using [ ] , .loc[] , .iloc[ ] , .ix[ ]
There are a lot of ways to pull the elements, rows, and columns from a DataFrame. There are some indexing method in Pandas which help in getting an element from a DataFrame. These indexing methods appear very similar but behave very differently. Pandas support four types of Multi-axes indexing they are:
- Dataframe.[ ] ; This function also known as indexing operator
- Dataframe.loc[ ] : This function is used for labels.
- Dataframe.iloc[ ] : This function is used for positions or integer based
- Dataframe.ix[] : This function is used for both label and integer based
Collectively, they are called the indexers. These are by far the most common ways to index data. These are four function which help in getting the elements, rows, and columns from a DataFrame.
Indexing a Dataframe using indexing operator [] :
Indexing operator is used to refer to the square brackets following an object. The .loc and .iloc indexers also use the indexing operator to make selections. In this indexing operator to refer to df[].
Selecting a single columns
In order to select a single column, we simply put the name of the column in-between the brackets