Работа с отсутствующими значениями в Pandas
Отсутствующее значение в наборе данных отображается как вопросительный знак, ноль, NaN или просто пустая ячейка. Но как можно справиться с недостающими данными?
Конечно, каждая ситуация отличается и должна оцениваться по-разному.
Есть много способов справиться с недостающими значениями. Рассмотрим типичные варианты на примере набора данных — ‘Titanic’. Эти данные являются открытым набором данных Kaggle.
Для анализа необходимо импортировать библиотеки Python и загрузить данные.
Для загрузки используется метод Pandas read.csv(). В скобках указывается путь к файлу в кавычках, чтобы Pandas считывал файл во фрейм данных (Dataframes — df) с этого адреса. Путь к файлу может быть URL адрес или вашим локальным адресом файла.
# import the libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline import matplotlib as plt import matplotlib as mpl import matplotlib.cm as cm import matplotlib.pyplot as plt from matplotlib import pyplot # import the dataset train_df = pd.read_csv(r'C:\Users\Tatiana\Desktop\Python\titanic\train.csv') train_df.head(2)
Посмотрим на размер данных (количество строк, колонок):
Для просмотра статистической сводки каждого столбца, чтобы узнать распределение данных в каждом столбце используется метод describe( ). Этот метод показывает нам количество строк в столбце — count, среднее значение столбца — mean, столбец стандартное отклонение — std, минимальные (min) и максимальные (max) значения, а также границу каждого квартиля — 25%, 50% и 75%. Любые значения NaN автоматически пропускаются.
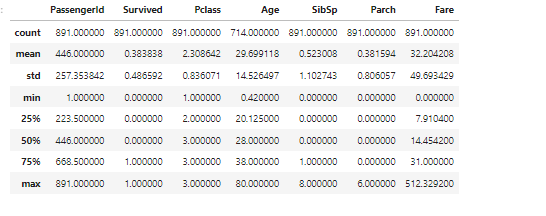
По умолчанию, метод describe( ) пропускает строки и столбцы не содержащие чисел — категориальные признаки. Чтобы включить сводку по всем столбцам нужно в скобках добавить аргумент — include = «all».
# describe all the columns train_df.describe(include = "all")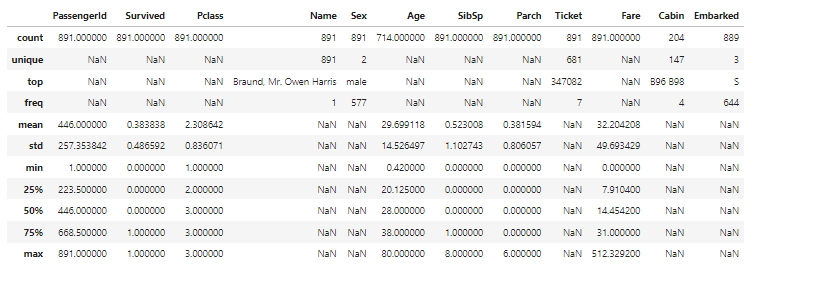
Для категориальных признаков этот метод показывает: — Сколько уникальных значений в наборе данных — unique; top значения; частота появления значений — freg.
Метод info( ) — показывает информацию о наборе данных, индекс, столбцы и тип данных, ненулевые значения и использование памяти.
# look at the info print(train_df.info())
В результате мы видим, что все колонки, кроме колонок ‘Age’, ‘Cabin’ и ‘Embarked’, содержат по 891 строк.
Колонка ‘Survived’ — это целевое значение. Показывает, кто выжил, а кто — нет. Эта колонка заполнена бинарными значениями:
Метод — value_counts(). Подсчет значений — это хороший способ понять, сколько единиц каждой характеристики / переменной у нас есть.
train_df['Survived'].value_counts()
Из 891 пассажира выжило 342.
sns.set_style('whitegrid') sns.countplot(x='Survived',data=train_df,palette='RdBu_r')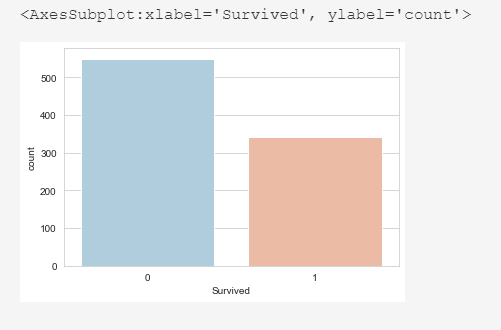
Из 891 пассажира выжило 342 это 38%.
figure, survive_bar = plt.subplots(figsize=(7, 7)) sns.barplot(x= train_df["Survived"].value_counts().index, y = train_df["Survived"].value_counts(), ax = survive_bar) survive_bar.set_xticklabels(['Not Survived', 'Survived']) survive_bar.set_ylabel('Frequency Count') survive_bar.set_title('Count of Survival', fontsize = 16) for patch in survive_bar.patches: label_x = patch.get_x() + patch.get_width()/2 # find midpoint of rectangle label_y = patch.get_y() + patch.get_height()/2 survive_bar.text(label_x, label_y, #left - freq below - rel freq wrt population as a percentage str(int(patch.get_height())) + '(' + ''.format(patch.get_height()/len(train_df.Survived))+')', horizontalalignment='center', verticalalignment='center')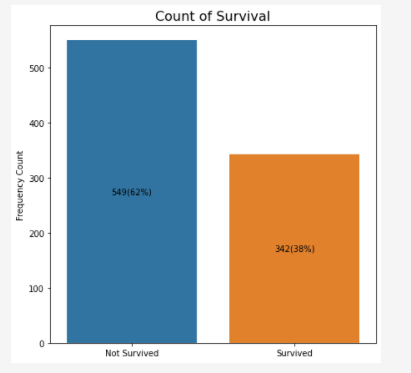
Визуализация: Графики подсчета значений в колонках — «Survived», «Pclass», «Sex», «SibSp», «Parch», «Embarked»
fig, myplot = plt.subplots(figsize = (15,6), nrows = 2,ncols = 3) features = ["Survived","Pclass","Sex","SibSp","Parch","Embarked"] row, col, num_cols = 0,0,3 for u in features: sns.barplot(x = train_df[u].value_counts().index,y = train_df[u].value_counts(), ax = myplot[row, col]) myplot[row, col].set_xlabel("") myplot[row, col].set_title(u + " Titanic", fontsize = 15) myplot[row, col].set_ylabel("Count") col = col + 1 if col == 3: col = 0 row = row + 1 plt.subplots_adjust(hspace = 0.5) plt.subplots_adjust(wspace = 0.3) # i put roundbracket around x,y,z to make more sense. just like how x \in [1,2,3] # and if x is a tuple or bracket #we have u \in [(1,2,3),(2,3,5). ] where u = (x,y,z) #for each patch in each graph from [0,0] to [1,2], we want to do the following. for v in range(2): for z in range(3): for patch in myplot[v,z].patches: label_x = patch.get_x() + patch.get_width()/2 # find midpoint of rectangle label_y = patch.get_y() + patch.get_height()/2 myplot[v,z].text(label_x, label_y, str(int(patch.get_height())) + '('+''.format( patch.get_height()/len(train_df.Survived))+')', horizontalalignment='center', verticalalignment='center')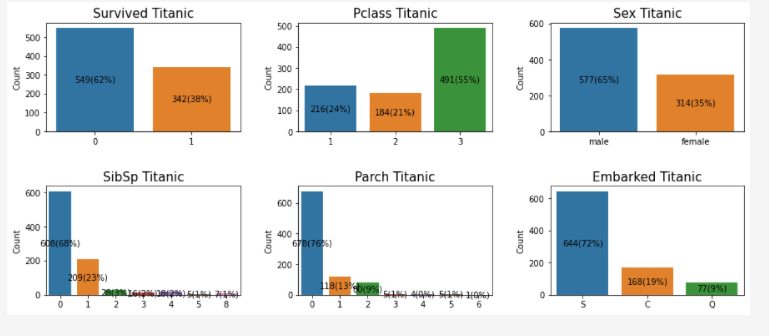
Теперь посмотрим на колонки которые имеют пропущенные значения.
Есть два метода обнаружения недостающих данных: — isnull() и notnull().
Результатом является логическое значение, указывающее, действительно ли значение, переданное в аргумент, отсутствует. «Истина» ( True ) означает, что значение является отсутствующим значением, а «Ложь» ( False ) означает, что значение не является отсутствующим.
# Evaluating for Missing Data missing_data = train_df.isnull() missing_data.head(6)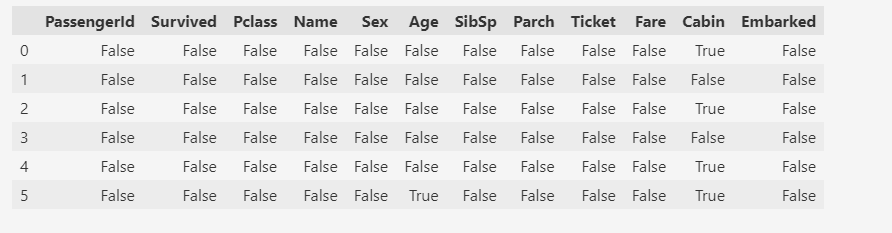
Используя цикл for в Python, мы можем быстро определить количество пропущенных значений в каждом столбце. Как упоминалось выше, «Истина» представляет отсутствующее значение, а «Ложь» означает, что значение присутствует в наборе данных. В теле цикла for метод «.value_counts ()» подсчитывает количество значений «True».
# Count missing values in each column for column in missing_data.columns.values.tolist(): print(column) print(missing_data[column].value_counts()) print(" ")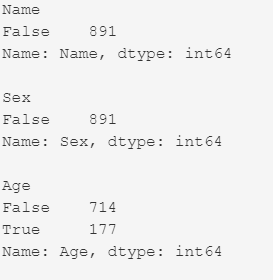

Посмотрим — сколько пропущенных значений в каждой колонке.
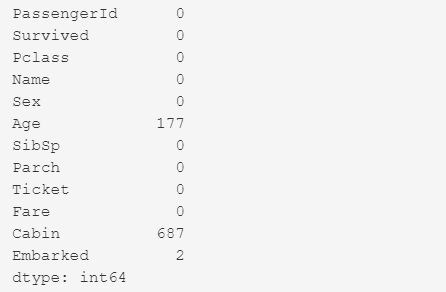
В колонке возраст — ‘Age’ не указано 177 значений. И нужно понять — это систематическая ошибка или какая-то случайная погрешность.
Н-р, может у пассажиров 1 класса (или у женщин) не спрашивали про возраст ( т. к. это было не прилично), или случайно пропустили. Понимание о причине пропущенных значений, определит — как работать с этими отсутствующими данными.
Нужно сгруппировать возраст, относительно того, отсутствует возраст или нет. Для группировки используем метод groupby().
True — отсутствует возраст
False — значение заполнено
# missing age or not train_df.groupby(train_df['Age'].isnull()).mean()
Среди пассажиров, у которых значение возраста отсутствовало, были выжившие (около 30%) и погибшие (около 70%) — колонка ‘Survived’, True = 0.29 .
Эти пассажиры были в более низком классе:
- колонка ‘Pclass’ — True = 2.59 (это среднее значение класса)
- колонка ‘Fare’ — True = 22.15 (это среднее значение стоимости билета)
Подсчет значений в колонке ‘Pclass’:
# Value Counts train_df['Pclass'].value_counts()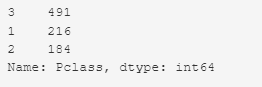
Например, в 3 классе было 491 пассажира (это 55%)
train_df.groupby(['Pclass']) ['Survived'].value_counts(normalize=True)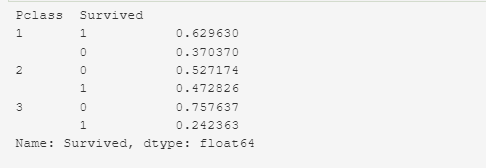
Для более детального анализа, создадим новую колонку ‘Age_NaN’ (бинарный классификатор). Используем метод where(), где прописываем условие: — если значение в колонке ‘Age’ отсутствует, то присваиваем в колонке ‘Age_NaN’ — значение 0, если присутствует, то 1.
# Let's create a new column 'Age_NaN' # If there is no value in the "Age" column, then = 0 and yes value = 1 train_df['Age_NaN'] = np.where(train_df['Age'].isnull(), 0,1) train_df.head(6)
Подсчет значений в колонке ‘Age_NaN’
# Value Counts train_df['Age_NaN'].value_counts()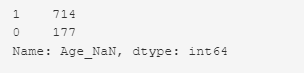
Выживаемость пассажиров в зависимости от наличия записи о возрасте.
# Survived passengers by 'Age_NaN' train_df.groupby(['Age_NaN']) ['Survived'].value_counts(normalize=True)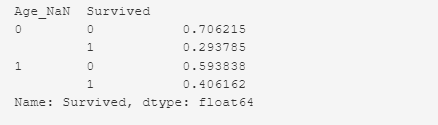
И снова мы видим: — что, среди пассажиров, у которых значение возраста отсутствовало, были выжившие (около 30%) и погибшие (около 70%).
Выживаемость пассажиров в зависимости от наличия записи о возрасте и класса.
train_df.groupby(['Age_NaN','Pclass']) ['Survived'].value_counts(normalize=True)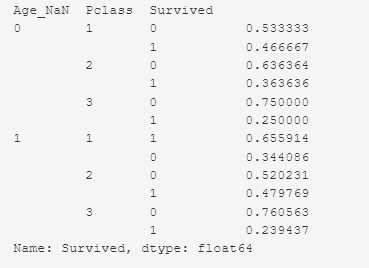
pd.crosstab(train_df['Pclass'], train_df['Age_NaN'])
В первом классе запись отсутствует у 30 пассажиров. Из 30 пассажиров выжило — 46%(14 пассажиров), погибло — 53%(16 пассажиров). Всего пассажиров было в первом классе — 216 (в данном наборе данных).
Во втором классе запись отсутствует у 11 пассажиров. Из 11 пассажиров выжило — 36%(4 пассажира), погибло — 63% (7 пассажиров). Всего пассажиров было во втором классе — 184 (в данном наборе данных).
В третьем классе запись отсутствует у 136 пассажиров. Из 136 пассажиров выжило — 25% (34 пассажира), погибло — 75% (102 пассажира). Всего пассажиров было в третьем классе — 491 (в данном наборе данных).
Выживаемость пассажиров в зависимости от наличия записи о возрасте и пола.
train_df.groupby(['Age_NaN','Sex']) ['Survived'].value_counts(normalize=True)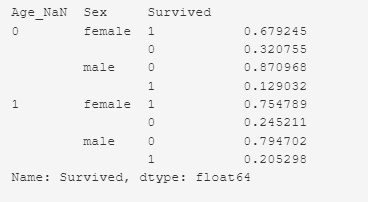
pd.crosstab(train_df['Sex'], train_df['Age_NaN'])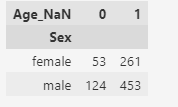
У 53 женщин нет записи о возрасте. Из 53 женщин выжило 68% (36 женщин), погибло 32% (17 женщин). Всего женщин было — 314 (в данном наборе данных).
У 124 мужчин нет записи о возрасте. Из 124 мужчин выжило 13% (16 мужчин), погибло 87% (108 мужчин). Всего мужчин было — 577 (в данном наборе данных)
Пассажиров было много в 3 классе и много погибло. Пассажиры — мужчины, у которых был более дешевый билет и более низкий класс — имели меньше шансов выжить.
Т.к. среди пассажиров, у которых значение возраста отсутствовало, были выжившие (около 30%) и погибшие (около 70%), и пассажиры были с разных классов( из 3 класса было значительно больше), и среди пассажиров были мужчины и женщины (мужчин было значительно больше), то при опросе у выживших и при осмотре тел погибших могли случайно пропустить возраст пассажира.
Следовательно делаем вывод, что возраст случайно не занесли.
Решение: Пропущенные значения заполнить средним значением.
# missing values are replaced by the average value train_df['Age'].fillna(train_df['Age'].mean(), inplace = True) sns.set_style('whitegrid') %matplotlib inline g = sns.FacetGrid(train_df, col='Survived') g.map(plt.hist, 'Age', bins=10)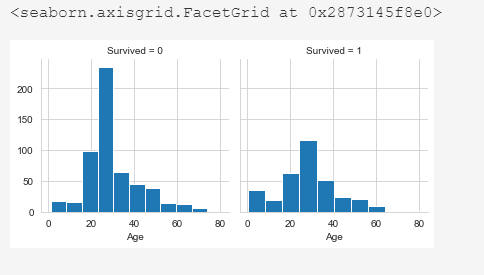
Посмотрим на график выживаемости пассажиров в зависимости от класса и возраста
# Survived passengers by Pclass and Age grid = sns.FacetGrid(train_df, col ='Survived', row ='Pclass', height = 3.5, aspect=1.5) grid.map(plt.hist, 'Age', alpha=.5, bins=10) grid.add_legend();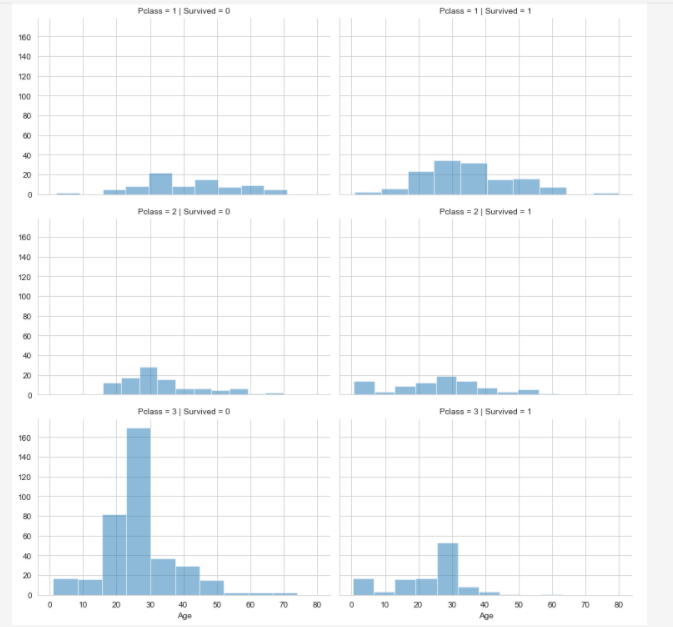
В колонке каюта ( ‘Cabin’) не указано 687 значений. Т. к. пропущенных значений много, можно удалить полностью колонку ‘Cabin’, а можно и оставить отсутствующие данные как — отсутствующие данные. Здесь важно понять: — Существует ли какая-то систематическая взаимосвязь между выживанием и тем, была ли у пассажира отдельная каюта.Для группировки используем метод groupby().
True — отсутствует упоминание о каюте
False — значение заполнено
# missing cabin or not # Relationship between the presence of a value in the "Cabin" column on the survival rate train_df.groupby(train_df['Cabin'].isnull()).mean() 
Те, пассажиры у кого запись отсутствует — выжили около 30%. А у кого запись о наличии каюты есть — выжило 67%.
Вывод: Есть взаимосвязь между выживанием и наличием каюты.
Создать новую колонку ‘Cabin_available’ (бинарный классификатор).Используем метод where(), где прописываем условие: — Если значение в колонке ‘Cabin’ отсутствует, то присваиваем в колонке ‘Cabin_available’ — значение 0, если присутствует, то 1.
# Let's create a new column 'Cabin_available' # If there is no value in the "Cabin" column, then = 0 and yes value = 1 train_df['Cabin_available'] = np.where(train_df['Cabin'].isnull(), 0,1) train_df.head(6) 
Выживаемость пассажиров в зависимости от наличия записи о каюте:
train_df.groupby(['Cabin_available']) ['Survived'].value_counts(normalize=True)
train_df.pivot_table( 'PassengerId', 'Cabin_available', 'Survived', 'count').plot( kind='bar', stacked=True)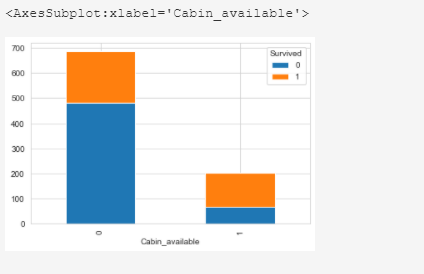
Теперь колонку ‘Cabin’ можно удалить.
train_df.drop(['Cabin'], axis = 1, inplace = True) train_df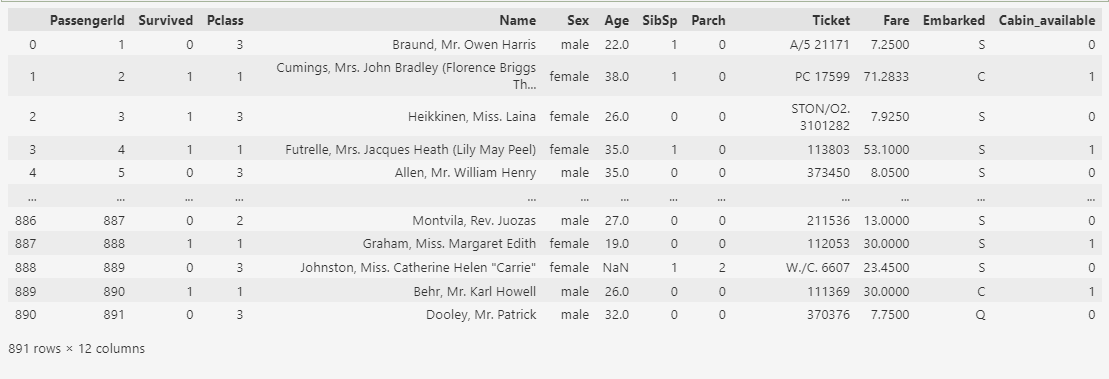
В колонке порт посадки на борт (‘Embarked’) не указано два значения. Это категориальный признак.
Решение: Заменить пропущенные значения по частоте. Заменить отсутствующее значение значением, которым чаще всего встречается в конкретном столбце.
train_df['Embarked'].value_counts()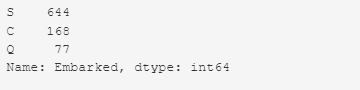
Чаще всего встречается значение S — 644. Нужно заменить пропущенные значения на S.
# replace the missing 'Embarked' values by the most frequent - S train_df['Embarked'].replace(np.nan, 'S', inplace = True) train_df['Embarked'].describe()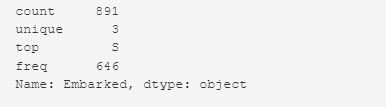
Good! Now, we have a dataset with no missing values. (Хорошо! Теперь у нас есть набор данных без пропущенных значений.)