Основы Pandas №3 // Важные методы форматирования данных
Это третья часть руководства по pandas, в которой речь пойдет о методах форматирования данных, часто используемых в проектах data science: merge , sort , reset_index и fillna . Конечно, есть и другие, поэтому в конце статьи будет шпаргалка с функциями и методами, которые также могут пригодиться.
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.
Суть в том, что при работе с данными довольно часто придется вытаскивать данные из двух и более разных страниц. Это делается с помощью merge .
Примечание: хотя в pandas это называется merge , метод почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo (из предыдущих частей руководства), в котором есть разные животные. Но в этот раз нужен еще один DataFrame — zoo_eats , в котором будет описаны пищевые требования каждого вида.
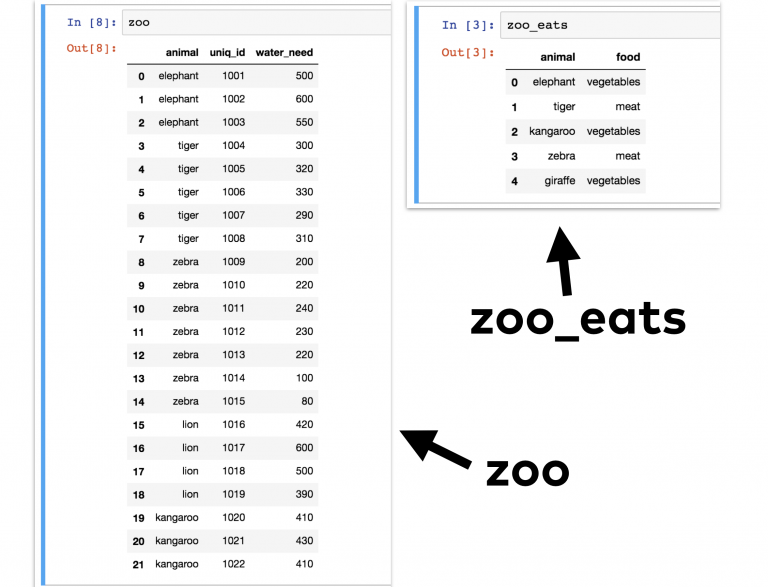
Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:
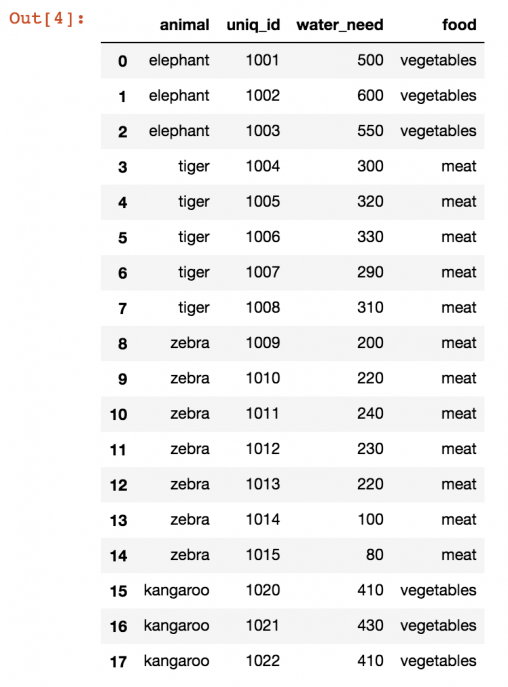
В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?
В первую очередь нужно создать DataFrame zoo_eats , потому что zoo уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
animal;food elephant;vegetables tiger;meat kangaroo;vegetables zebra;vegetables giraffe;vegetables О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в Jupyter Notebook pandas_tutorial_1 , который был создан еще в первой части руководства.
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food']) И вот готов DataFrame zoo_eats .
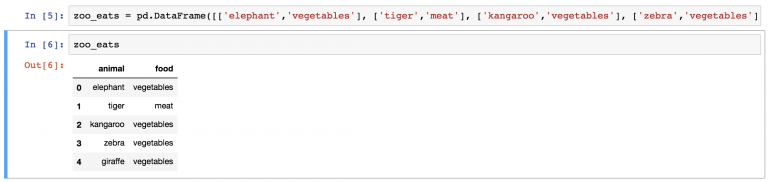
Теперь пришло время метода merge:
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame ( zoo ). Потом к нему применен метод .merge() . В качестве его параметра выступает новый DataFrame ( zoo_eats ). Можно было сделать и наоборот:
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.
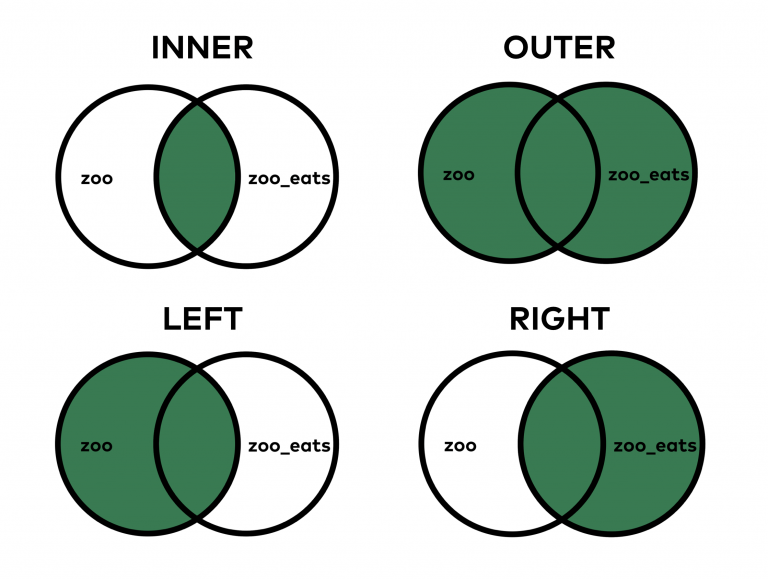
В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в zoo_eats нет значения lion . А в zoo нет значения giraffe . По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
zoo.merge(zoo_eats, how='outer') 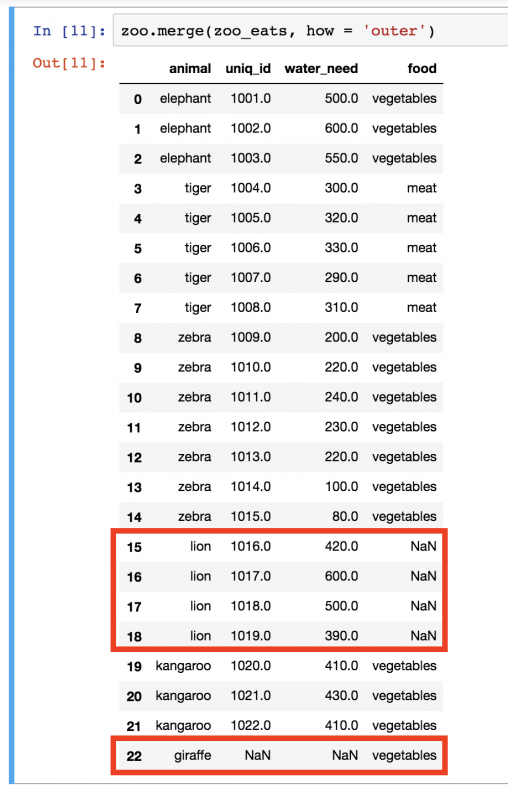
В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск ( NaN ).
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: vegetables , meat и NaN (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром how=’left’ при объединении.
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = ‘left’ заберет все значения из левой таблицы ( zoo ), но из правой ( zoo_eats ) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Для использования merge библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка animal ). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры left_on и right_on .
Например, последний merge мог бы выглядеть следующим образом:
zoo.merge(zoo_eats, how = 'left', left_on='animal', right_on='animal') Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о left_on и right_on не стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:

Примечание: в прошлых версиях pandas была функция sort() , работающая подобным образом. Но в новых версиях ее заменили на sort_values() , поэтому пользоваться нужно именно новым вариантом.
Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by :
zoo.sort_values(by=['animal', 'water_need']) 
Примечание: ключевое слово by можно использовать и для одной колонки zoo.sort_values(by = [‘water_need’] .
sort_values сортирует в порядке возрастания, но это можно поменять на убывание:
zoo.sort_values(by=['water_need'], ascending=False) 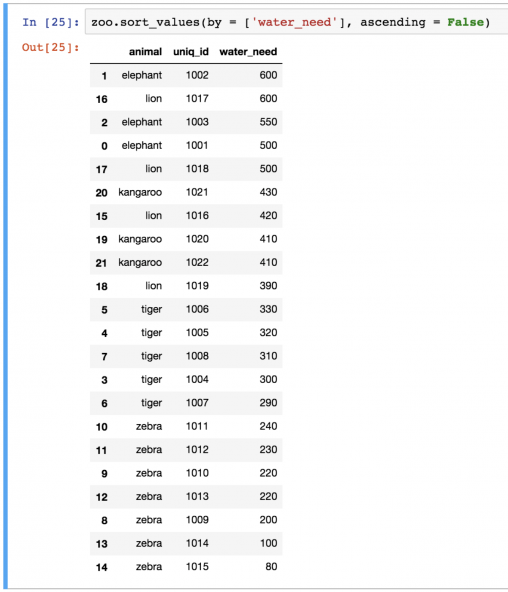
reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?
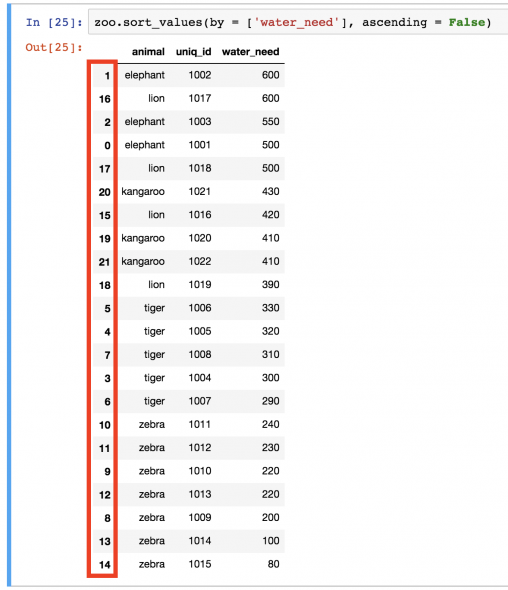
Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.
В случае изменения DataFrame нужно переиндексировать строки. Для этого можно использовать метод reset_index() . Например:
zoo.sort_values(by=['water_need'], ascending=False).reset_index() 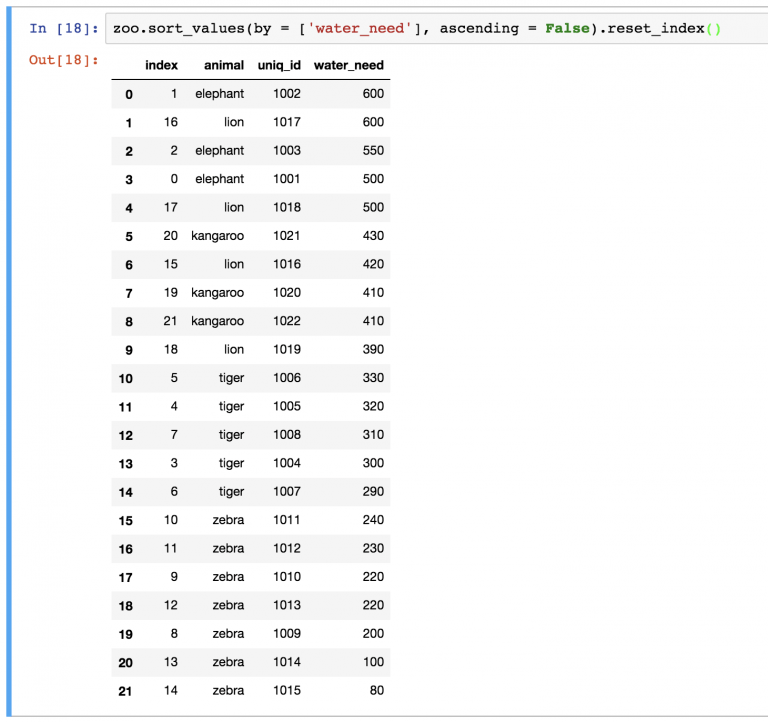
Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True) 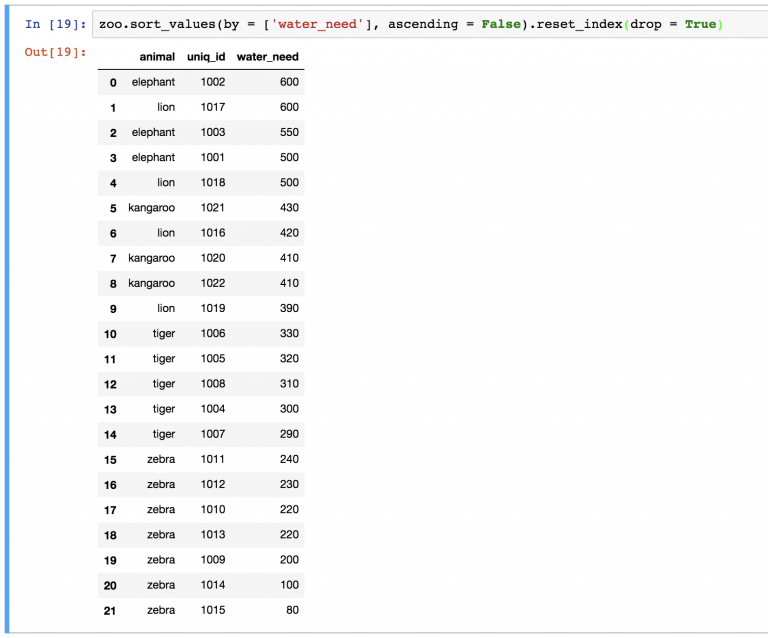
Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:
Это все животные. Проблема только в том, что для львов есть значение NaN . Само по себе это значение может отвлекать, поэтому лучше заменять его на что-то более осмысленное. Иногда это может быть 0 , в других случаях — строка. Но в этот раз обойдемся unknown . Функция fillna() автоматически найдет и заменит все значения NaN в DataFrame:
zoo.merge(zoo_eats, how='left').fillna('unknown') 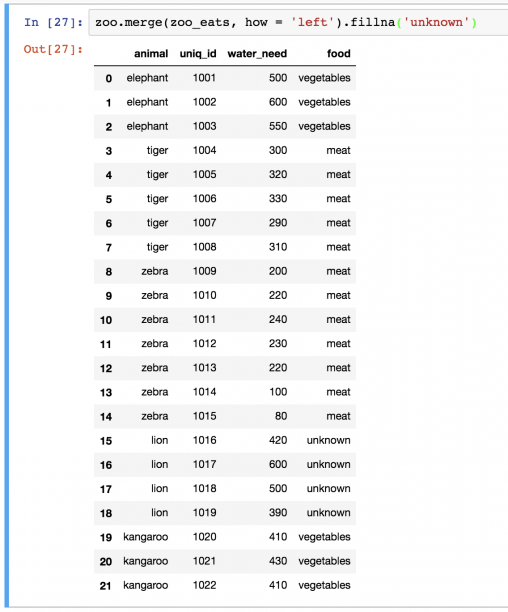
Примечание: зная, что львы едят мясо, можно было также написать zoo.merge(zoo_eats, how=’left’).fillna(‘meat’) .
Проверьте себя
Вернемся к набору данных article_read .
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Скачайте еще один набор данных: blog_buy . Это можно сделать с помощью следующих двух строк в Jupyter Notebook:
!wget https://pythonru.com/downloads/pandas_tutorial_buy.csv blog_buy = pd.read_csv('pandas_tutorial_buy.csv', delimiter=';', names=['my_date_time', 'event', 'user_id', 'amount']) Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
- Какой средний доход в период с 2018-01-01 по 2018-01-07 от пользователей из article_read ?
- Выведите топ-3 страны по общему уровню дохода за период с 2018-01-01 по 2018-01-07 . (Пользователей из article_read здесь тоже нужно использовать).
Решение задания №1
Для вычисления использовался следующий код:
step_1 = article_read.merge(blog_buy, how='left', left_on='user_id', right_on='user_id') step_2=step_1.amount step_3=step_2.fillna(0) result=step_3.mean() result 
Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
- На скриншоте также есть две строки с импортом pandas и numpy, а также чтением файлов csv в Jupyter Notebook.
- На шаге №1 объединены две таблицы ( article_read и blog_buy ) на основе колонки user_id . В таблице article_read хранятся все пользователи, даже если они ничего не покупают, потому что ноли ( 0 ) также должны учитываться при подсчете среднего дохода. Из таблицы удалены те, кто покупали, но кого нет в наборе article_read . Все вместе привело к left-merge.
- Шаг №2 — удаление ненужных колонок с сохранением только amount .
- На шаге №3 все значения NaN заменены на 0 .
- В конце концов проводится подсчет с помощью .mean() .
Решение задания №2
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id') step_2 = step_1.fillna(0) step_3 = step_2.groupby('country').sum() step_4 = step_3.amount step_5 = step_4.sort_values(ascending = False) step_5.head(3) 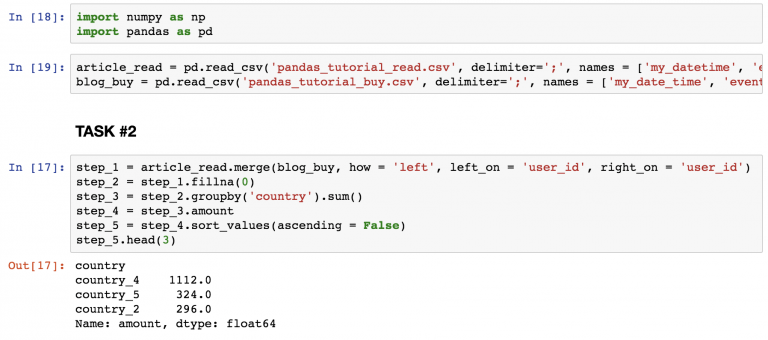
Найдите топ-3 страны на скриншоте.
- Тот же метод merge , что и в первом задании.
- Замена всех NaN на 0 .
- Суммирование всех числовых значений по странам.
- Удаление всех колонок кроме amount .
- Сортировка результатов в убывающем порядке так, чтобы можно было видеть топ.
- Вывод только первых 3 строк.
Итого
Это был третий эпизод руководства pandas с важными и часто используемыми методами: merge, sort, reset_index и fillna .