- pandas.DataFrame.groupby#
- Основы Pandas №2 // Агрегация и группировка
- Агрегация данных — теория
- Агрегация данных — практика
- Агрегация данных pandas №1: .count()
- Агрегация данных pandas №2: .sum()
- Агрегация данных pandas №3 и №4: .min() и .max()
- Агрегация данных pandas №5 и №6: .mean() и .median()
- Группировка в pandas
- Функция .groupby в действии
- Проверить себя №1
- Проверить себя №2
- Итого
- pandas.core.groupby.DataFrameGroupBy.mean#
pandas.DataFrame.groupby#
Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
Parameters by mapping, function, label, pd.Grouper or list of such
Used to determine the groups for the groupby. If by is a function, it’s called on each value of the object’s index. If a dict or Series is passed, the Series or dict VALUES will be used to determine the groups (the Series’ values are first aligned; see .align() method). If a list or ndarray of length equal to the selected axis is passed (see the groupby user guide), the values are used as-is to determine the groups. A label or list of labels may be passed to group by the columns in self . Notice that a tuple is interpreted as a (single) key.
Split along rows (0) or columns (1). For Series this parameter is unused and defaults to 0.
level int, level name, or sequence of such, default None
If the axis is a MultiIndex (hierarchical), group by a particular level or levels. Do not specify both by and level .
as_index bool, default True
For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output.
sort bool, default True
Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. Groupby preserves the order of rows within each group.
Changed in version 2.0.0: Specifying sort=False with an ordered categorical grouper will no longer sort the values.
When calling apply and the by argument produces a like-indexed (i.e. a transform ) result, add group keys to index to identify pieces. By default group keys are not included when the result’s index (and column) labels match the inputs, and are included otherwise.
Changed in version 1.5.0: Warns that group_keys will no longer be ignored when the result from apply is a like-indexed Series or DataFrame. Specify group_keys explicitly to include the group keys or not.
Changed in version 2.0.0: group_keys now defaults to True .
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
dropna bool, default True
If True, and if group keys contain NA values, NA values together with row/column will be dropped. If False, NA values will also be treated as the key in groups.
Returns a groupby object that contains information about the groups.
Convenience method for frequency conversion and resampling of time series.
See the user guide for more detailed usage and examples, including splitting an object into groups, iterating through groups, selecting a group, aggregation, and more.
>>> df = pd.DataFrame('Animal': ['Falcon', 'Falcon', . 'Parrot', 'Parrot'], . 'Max Speed': [380., 370., 24., 26.]>) >>> df Animal Max Speed 0 Falcon 380.0 1 Falcon 370.0 2 Parrot 24.0 3 Parrot 26.0 >>> df.groupby(['Animal']).mean() Max Speed Animal Falcon 375.0 Parrot 25.0
Hierarchical Indexes
We can groupby different levels of a hierarchical index using the level parameter:
>>> arrays = [['Falcon', 'Falcon', 'Parrot', 'Parrot'], . ['Captive', 'Wild', 'Captive', 'Wild']] >>> index = pd.MultiIndex.from_arrays(arrays, names=('Animal', 'Type')) >>> df = pd.DataFrame('Max Speed': [390., 350., 30., 20.]>, . index=index) >>> df Max Speed Animal Type Falcon Captive 390.0 Wild 350.0 Parrot Captive 30.0 Wild 20.0 >>> df.groupby(level=0).mean() Max Speed Animal Falcon 370.0 Parrot 25.0 >>> df.groupby(level="Type").mean() Max Speed Type Captive 210.0 Wild 185.0
We can also choose to include NA in group keys or not by setting dropna parameter, the default setting is True .
>>> l = [[1, 2, 3], [1, None, 4], [2, 1, 3], [1, 2, 2]] >>> df = pd.DataFrame(l, columns=["a", "b", "c"])
>>> df.groupby(by=["b"]).sum() a c b 1.0 2 3 2.0 2 5
>>> df.groupby(by=["b"], dropna=False).sum() a c b 1.0 2 3 2.0 2 5 NaN 1 4
>>> l = [["a", 12, 12], [None, 12.3, 33.], ["b", 12.3, 123], ["a", 1, 1]] >>> df = pd.DataFrame(l, columns=["a", "b", "c"])
>>> df.groupby(by="a").sum() b c a a 13.0 13.0 b 12.3 123.0
>>> df.groupby(by="a", dropna=False).sum() b c a a 13.0 13.0 b 12.3 123.0 NaN 12.3 33.0
When using .apply() , use group_keys to include or exclude the group keys. The group_keys argument defaults to True (include).
>>> df = pd.DataFrame('Animal': ['Falcon', 'Falcon', . 'Parrot', 'Parrot'], . 'Max Speed': [380., 370., 24., 26.]>) >>> df.groupby("Animal", group_keys=True).apply(lambda x: x) Animal Max Speed Animal Falcon 0 Falcon 380.0 1 Falcon 370.0 Parrot 2 Parrot 24.0 3 Parrot 26.0
>>> df.groupby("Animal", group_keys=False).apply(lambda x: x) Animal Max Speed 0 Falcon 380.0 1 Falcon 370.0 2 Parrot 24.0 3 Parrot 26.0
Основы Pandas №2 // Агрегация и группировка
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
…простейший метод агрегации для него — суммирование water_needs , то есть 100 + 350 + 670 + 200 = 1320. Как вариант, можно посчитать количество животных — 4. Теория не так сложна. Но пора переходить к практике.
Агрегация данных — практика
Где мы остановились в последний раз? Открыли Jupyter Notebook, импортировали pandas и numpy и загрузили два набора данных: zoo.csv и article_reads . Продолжим с этого же места. Если вы не прошли первую часть, вернитесь и начните с нее.
Начнем с набора zoo . Он был загружен следующим образом:
pd.read_csv('zoo.csv', delimiter = ',') 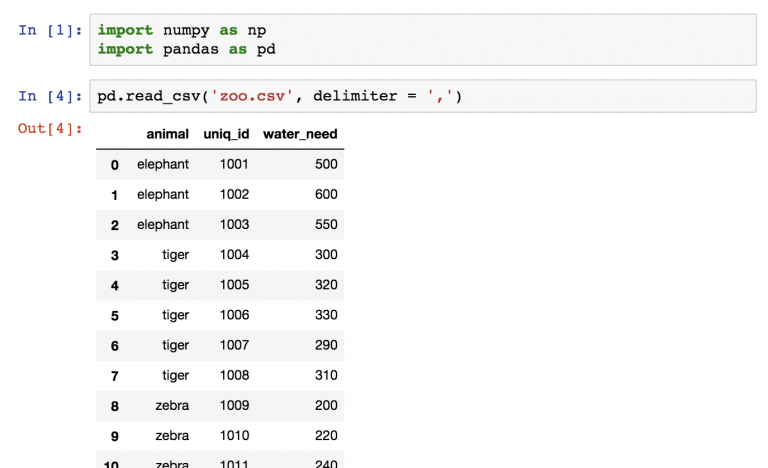
Дальше сохраним набор данных в переменную zoo .
zoo = pd.read_csv('zoo.csv', delimiter = ',') Теперь нужно проделать пять шагов:
- Посчитать количество строк (количество животных) в zoo .
- Посчитать общее значение water_need животных.
- Найти наименьшее значение water_need .
- И самое большое значение water_need .
- Наконец, среднее water_need .
Агрегация данных pandas №1: .count()
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo :

А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
В этом случае результат будет даже лучше, если написать следующим образом:
Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Агрегация данных pandas №2: .sum()
Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:

Просто из любопытства можно попробовать найти сумму во всех колонках:

Примечание: интересно, как .sum() превращает слова из колонки animal в строку названий животных. (Кстати, это соответствует всей логике языка Python).
Агрегация данных pandas №3 и №4: .min() и .max()
Какое наименьшее значение в колонке water_need ? Определить это несложно:

То же и с максимальным значением:

Агрегация данных pandas №5 и №6: .mean() и .median()
Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:


Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды ( water_need ) для всех животных (это 347,72 ). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
Функция .groupby в действии
Проделаем эту же группировку с DataFrame zoo .
Между переменной zoo и функцией . mean() нужно вставить ключевое слово groupby :
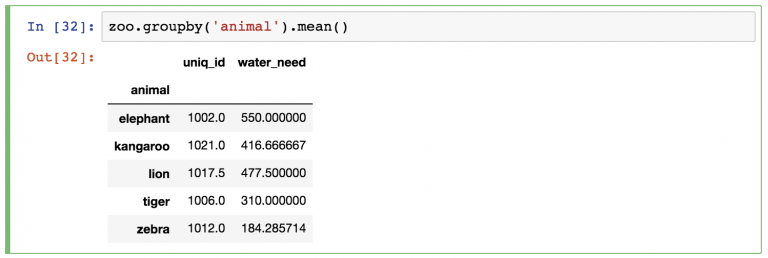
Как и раньше, pandas автоматически проведет расчеты . mean() для оставшихся колонок (колонка animal пропала, потому что по ней проводилась группировка). Можно или игнорировать колонку uniq_id или удалить ее одним из следующих способов:
zoo.groupby(‘animal’).mean()[[‘water_need’]] — возвращает объект DataFrame.
zoo.groupby(‘animal’).mean().water_need — возвращает объект Series.
Можно поменять метод агрегации с . mean() на любой изученный до этого.
Проверить себя №1
Вернемся к набору данных article_read .
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
Получить его можно было с помощью кода:
article_read.groupby('source').count() Взять набор данных article_read , создать сегменты по значениям колонки source ( groupby(‘source’) ) и в конце концов посчитать значения по источникам ( .count() ).

Также можно удалить ненужные колонки и сохранить только user_id :
article_read.groupby('source').count()[['user_id']] Проверить себя №2
Вот еще одна, более сложная задача:
Какие самые популярные источник и страна для пользователей country_2 ? Другими словами, какая тема из какого источника принесла больше всего просмотров из country_2 ?
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count() 
В первую очередь отфильтровали пользователей из country_2 ( article_read[article_read.country == ‘country_2’] ). Затем для этого подмножества был использован метод groupby . (Да, группировку можно осуществлять для нескольких колонок. Для этого их названия нужно собрать в список. Поэтому квадратные скобки используются между круглыми. Это что касается части groupby([‘source’, ‘topic’]) ).
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
В следующем материале вы узнаете о четырех распространенных методах форматирования данных: merge , sort , reset_index и fillna .
pandas.core.groupby.DataFrameGroupBy.mean#
Changed in version 2.0.0: numeric_only no longer accepts None and defaults to False .
- ‘cython’ : Runs the operation through C-extensions from cython.
- ‘numba’ : Runs the operation through JIT compiled code from numba.
- None : Defaults to ‘cython’ or globally setting compute.use_numba
- For ‘cython’ engine, there are no accepted engine_kwargs
- For ‘numba’ engine, the engine can accept nopython , nogil and parallel dictionary keys. The values must either be True or False . The default engine_kwargs for the ‘numba’ engine is >
Apply a function groupby to a Series.
Apply a function groupby to each row or column of a DataFrame.
>>> df = pd.DataFrame('A': [1, 1, 2, 1, 2], . 'B': [np.nan, 2, 3, 4, 5], . 'C': [1, 2, 1, 1, 2]>, columns=['A', 'B', 'C'])
Groupby one column and return the mean of the remaining columns in each group.
>>> df.groupby('A').mean() B C A 1 3.0 1.333333 2 4.0 1.500000
Groupby two columns and return the mean of the remaining column.
>>> df.groupby(['A', 'B']).mean() C A B 1 2.0 2.0 4.0 1.0 2 3.0 1.0 5.0 2.0
Groupby one column and return the mean of only particular column in the group.
>>> df.groupby('A')['B'].mean() A 1 3.0 2 4.0 Name: B, dtype: float64