- Read Excel File in Python Pandas
- Introduction
- Getting Started with Excel Files in Pandas
- Understanding the Pandas’ read_excel Function
- Specify Data Types in Pandas read_excel
- Pandas read_excel() Example
- Pandas read_excel() usecols Example
- How to Read a Subset of Columns?
- How to Get the List of Columns Headers in Excel ?
- How to Use Pandas to Read Excel Files in Python
- The Quick Answer: Use Pandas read_excel to Read Excel Files
- Understanding the Pandas read_excel Function
- How to Read Multiple Sheets in an Excel File in Pandas
- How to Read Only n Lines When Reading Excel Files in Pandas
- Conclusion
- Additional Resources
Read Excel File in Python Pandas
In this article, we are going to learn how to «work with an Excel sheet using Pandas». We will cover the pandas read Excel function and its parameters used for reading the data of the Excel file and also various ways to read the data of the Excel file.
Introduction
In Python, we can work with the data in the Excel sheet with the help of the Pandas module. There is a function called the pandas read_excel function for reading the Excel file. There are lots of parameters for this function, like «io» , «sheet_name» , «dtype» , etc., for reading the data in different ways. We can also get a specific part of the data using pandas read_excel function parameters.
Getting Started with Excel Files in Pandas
First, to work with Excel files in Pandas, it is necessary to import the pandas module by running the following command :
Understanding the Pandas’ read_excel Function
pandas.read excel() is pandas read_excel function which is used to read the excel sheets with extensions ( .xlsx , .xls , .xlsx , .xlsm , .xlsb , .odf , .ods and .odt ) into pandas DataFrame object.
A «Pandas DataFrame object» is returned by reading a single sheet while reading two sheets results in a Dict of DataFrame.
We can also load Excel files from a URL or which are stored in the local filesystem.
It supports http , ftp , s3 , and file for URLs.
The Pandas Read Excel Function has various parameters.
Some of them are as follows:
- io :
This parameter describes the path to the file. The string path can be any valid string. There should be a host for file URLs.- can be str , bytes , ExcelFile , xlrd.Book , path object , or file-like object
- eg. :
- int, list of int, default 0 .
- usecols :
This parameter is used to read specific columns.- can be strings of columns, integers representing positions columns, or Excel-style columns like ( «A:C» ).
- can be a dictionary using data types as values and columns as keys.
- eg. : «a» is np.float64 and «b» is np.int32
- it is by default None and can be list-like, or int.
- int, default None
Specify Data Types in Pandas read_excel
When we are reading an Excel file, it is easy to specify the data type of the columns because of pandas.
The main three objectives served by this are :
- preventing the improper reading of data
- accelerating the reading process
- preserving memory
We can enter a dictionary where the data types are the values and the keys are the columns. This guarantees that the data are prepared correctly. Let’s look at how to define the data types for our columns.
Explanation:
In the above example, module pandas are imported as pd. Then the read_excel function is used to read the Excel file and store the dataset into a data variable. dtype parameter is used to specify the data type of columns in the form of key-value pairs, i.e., a dictionary.
Pandas read_excel() Example
Let’s see how to read Excel files using the pandas read_excel function by following these examples :
Here, I am using this sample Excel file from Github.
Importing an Excel file from a URL link.
Explanation:
In the above code, we just import the file URL link, read the file using the read_excel function, and print the data from the excel file.
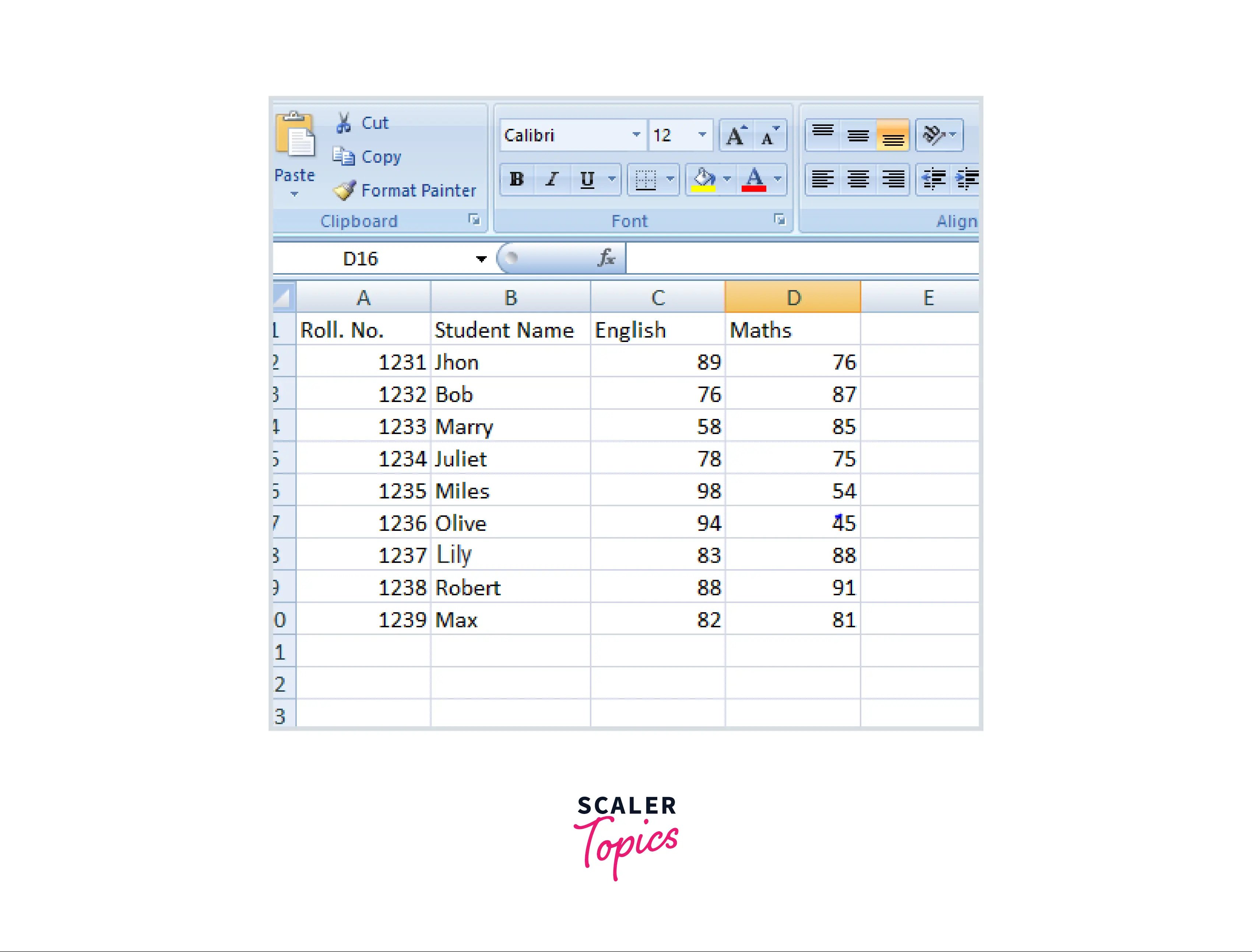
Let’s try to import a file from the local file system. So, Initially, my excel file looked like this :

Explanation:
In this code example, we are importing a file from the disk and reading it using the read_excel function.
Explanation:
Using the read_excel function, we read the data from the file. Then using the head function, by default, data of 5 rows from the start is printed.
Pandas read_excel() usecols Example
When we want to access some specific data from our dataset, i.e., some specific column or range of columns, then we usecols parameter of the read_excel function. It takes the column name, position, or range of columns (int, list, string, or callable default None) to specify which column we want to access.
Let’s see the below examples:
Explanation:
Here, we tried to read the valies of some specific columns using usecols function. Columns in the range from A to B as index values i.e. first two columns are printed as output.
Explanation:
In this above code example column at index «C» is printed using the usecols parameter.
Explanation:
Here, we use integer indexes to the usecols parameter to specify the column range. As a result, intial two columns are printed.
Explanation:
In this above code example, we are using only a single integerlist for printing the column data at that specific index.
Explanation:
We can also use the name of the column as a string list to get the data of that column.
How to Read a Subset of Columns?
Using only the square brackets, you can select columns, rows, or a combination of columns and rows. See how this works now.
Selecting only column:
Explanation:
Here, in this example, only column data of the specified given column name is printed.
Explanation:
In this above code example, the head() function is used to read the starting values of the file. Usually, It takes the data of the starting first 5 five rows by default if nothing is passed in the head function.
Explanation :
we can also filter data, like in the above code example , we get only the marks in English that are greater than 86 .
There is another approach for selecting columns in python using the .loc() function.
Explanation:
Using .loc we can access a collection of rows and columns by label(s) or a boolean array. In this above example, we use an integer index [1] to access the row at the 1st index.
How to Get the List of Columns Headers in Excel ?
There are various approaches to getting the list of column headers or column names.
- Using list(data.columns) function. Code:
How to Use Pandas to Read Excel Files in Python

In this tutorial, you’ll learn how to use Python and Pandas to read Excel files using the Pandas read_excel function. Excel files are everywhere – and while they may not be the ideal data type for many data scientists, knowing how to work with them is an essential skill.
By the end of this tutorial, you’ll have learned:
- How to use the Pandas read_excel function to read an Excel file
- How to read specify an Excel sheet name to read into Pandas
- How to read multiple Excel sheets or files
- How to certain columns from an Excel file in Pandas
- How to skip rows when reading Excel files in Pandas
- And more
The Quick Answer: Use Pandas read_excel to Read Excel Files
To read Excel files in Python’s Pandas, use the read_excel() function. You can specify the path to the file and a sheet name to read, as shown below:
# Reading an Excel File in Pandas import pandas as pd df = pd.read_excel('/Users/datagy/Desktop/Sales.xlsx') # With a Sheet Name df = pd.read_excel( io='/Users/datagy/Desktop/Sales.xlsx' sheet_name ='North' )In the following sections of this tutorial, you’ll learn more about the Pandas read_excel() function to better understand how to customize reading Excel files.
Understanding the Pandas read_excel Function
The Pandas read_excel() function has a ton of different parameters. In this tutorial, you’ll learn how to use the main parameters available to you that provide incredible flexibility in terms of how you read Excel files in Pandas.

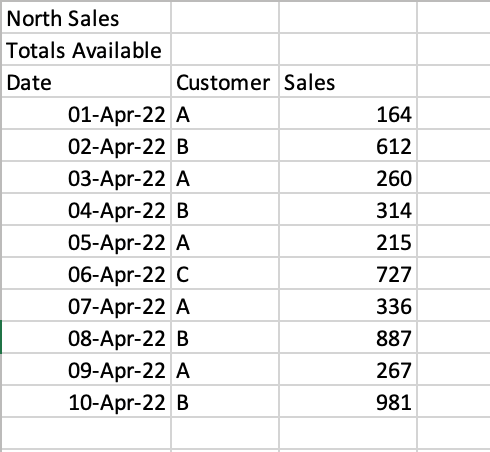
If we were to read the sheet ‘North’ , we would get the following returned:
# Reading a poorly formatted Excel file import pandas as pd df = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', sheet_name='North') print(df.head()) # Returns: # North Sales Unnamed: 1 Unnamed: 2 # 0 Totals Available NaN NaN # 1 Date Customer Sales # 2 2022-04-01 00:00:00 A 164 # 3 2022-04-02 00:00:00 B 612 # 4 2022-04-03 00:00:00 A 260Pandas makes it easy to skip a certain number of rows when reading an Excel file. This can be done using the skiprows= parameter. We can see that we need to skip two rows, so we can simply pass in the value 2, as shown below:
# Reading a Poorly Formatted File Correctly import pandas as pd df = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', sheet_name='North', skiprows=2) print(df.head()) # Returns: # Date Customer Sales # 0 2022-04-01 A 164 # 1 2022-04-02 B 612 # 2 2022-04-03 A 260 # 3 2022-04-04 B 314 # 4 2022-04-05 A 215This read the file much more accurately! It can be a lifesaver when working with poorly formatted files. In the next section, you’ll learn how to read multiple sheets in an Excel file in Pandas.
How to Read Multiple Sheets in an Excel File in Pandas
Pandas makes it very easy to read multiple sheets at the same time. This can be done using the sheet_name= parameter. In our earlier examples, we passed in only a single string to read a single sheet. However, you can also pass in a list of sheets to read multiple sheets at once.
Let’s see how we can read our first two sheets:
# Reading Multiple Excel Sheets at Once in Pandas import pandas as pd dfs = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', sheet_name=['East', 'West']) print(type(dfs)) # Returns:
In the example above, we passed in a list of sheets to read. When we used the type() function to check the type of the returned value, we saw that a dictionary was returned.
Each of the sheets is a key of the dictionary with the DataFrame being the corresponding key’s value. Let’s see how we can access the ‘West’ DataFrame:
# Reading Multiple Excel Sheets in Pandas import pandas as pd dfs = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', sheet_name=['East', 'West']) print(dfs.get('West').head()) # Returns: # Date Customer Sales # 0 2022-04-01 A 504 # 1 2022-04-02 B 361 # 2 2022-04-03 A 694 # 3 2022-04-04 B 702 # 4 2022-04-05 A 255You can also read all of the sheets at once by specifying None for the value of sheet_name= . Similarly, this returns a dictionary of all sheets:
# Reading Multiple Excel Sheets in Pandas import pandas as pd dfs = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', sheet_name=None)In the next section, you’ll learn how to read multiple Excel files in Pandas.
How to Read Only n Lines When Reading Excel Files in Pandas
When working with very large Excel files, it can be helpful to only sample a small subset of the data first. This allows you to quickly load the file to better be able to explore the different columns and data types.
This can be done using the nrows= parameter, which accepts an integer value of the number of rows you want to read into your DataFrame. Let’s see how we can read the first five rows of the Excel sheet:
# Reading n Number of Rows of an Excel Sheet import pandas as pd df = pd.read_excel( io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx', nrows=5) print(df) # Returns: # Date Customer Sales # 0 2022-04-01 A 191 # 1 2022-04-02 B 727 # 2 2022-04-03 A 782 # 3 2022-04-04 B 561 # 4 2022-04-05 A 969Conclusion
In this tutorial, you learned how to use Python and Pandas to read Excel files into a DataFrame using the .read_excel() function. You learned how to use the function to read an Excel, specify sheet names, read only particular columns, and specify data types. You then learned how skip rows, read only a set number of rows, and read multiple sheets.
Additional Resources
To learn more about related topics, check out the tutorials below: