- Как использовать функцию idxmax() в Pandas (с примерами)
- Пример 1: найти индекс с максимальным значением для каждого столбца
- Пример 2: найти столбец с максимальным значением для каждой строки
- pandas.DataFrame.max#
- Максимальное значение max() в Pandas DataFrame
- Пример 1: по столбцам
- Пример 2: по строке
- Пример 3
- Как найти минимальное и максимальное значение в Pandas таблице
- Действовать будем по плану:
- Загрузка датасета
- Работаем с максимальными значениями
- 1. Ищем максимальное значение:
- # для каждого столбца таблицы:
- # в определенном столбце таблицы:
- 2. Выводим на экран строку с максимальным значением
- Работаем с минимальными значениями
- 1. Ищем минимальное значение:
- # для каждого столбца таблицы
- # в определенном столбце таблицы:
- 2. Выводим на экран строку с минимальным значением
- Коротко о поиске максимальных и минимальных значений в pandas:
Как использовать функцию idxmax() в Pandas (с примерами)
Вы можете использовать функцию pandas.DataFrame.idxmax() , чтобы вернуть индекс максимального значения по указанной оси в кадре данных pandas.
Эта функция использует следующий синтаксис:
DataFrame.idxmax (ось = 0, скипна = Истина)
- axis : Используемая ось (0 = строки, 1 = столбцы). По умолчанию 0.
- skipna : следует ли исключать значения NA или null. Значение по умолчанию — Истина.
В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame(, index=['Andy','Bob', 'Chad', 'Dan', 'Eric', 'Frank']) #view DataFrame df points assists rebounds Andy 25 5 11 Bob 12 7 8 Chad 15 7 11 Dan 8 9 6 Eric 9 12 6 Frank 23 9 5 Пример 1: найти индекс с максимальным значением для каждого столбца
В следующем коде показано, как найти индекс с максимальным значением для каждого столбца:
#find index that has max value for each column df.idxmax (axis= 0 ) points Andy assists Eric rebounds Andy dtype: object - Игрок с наибольшим значением в столбце очков — Энди.
- Игрок с самым высоким значением в колонке передач — Эрик.
- Игрок с наибольшим значением в столбце подборов — Энди.
Важно отметить, что функция idxmax() вернет первое вхождение максимального значения.
Например, обратите внимание, что у Энди и Чеда было по 11 подборов. Поскольку Энди появляется первым в DataFrame, возвращается его имя.
Пример 2: найти столбец с максимальным значением для каждой строки
В следующем коде показано, как найти столбец с максимальным значением для каждой строки:
#find column that has max value for each row df.idxmax (axis= 1 ) Andy points Bob points Chad points Dan assists Eric assists Frank points dtype: object - Наибольшее значение в строке с надписью «Энди» можно найти в столбце очков .
- Наибольшее значение в строке с надписью «Боб» можно найти в столбце очков .
- Наибольшее значение в строке с надписью «Чад» можно найти в столбце очков .
- Самое высокое значение в строке с надписью «Дэн» можно найти в столбце передач .
- Наибольшее значение в строке с надписью «Эрик» можно найти в столбце передач .
- Наибольшее значение в строке с надписью «Энди» можно найти в столбце очков .
Обратитесь к документации pandas за полным объяснением функции idxmax().
pandas.DataFrame.max#
Return the maximum of the values over the requested axis.
If you want the index of the maximum, use idxmax . This is the equivalent of the numpy.ndarray method argmax .
Parameters axis
Axis for the function to be applied on. For Series this parameter is unused and defaults to 0.
For DataFrames, specifying axis=None will apply the aggregation across both axes.
Exclude NA/null values when computing the result.
numeric_only bool, default False
Include only float, int, boolean columns. Not implemented for Series.
Additional keyword arguments to be passed to the function.
Return the index of the minimum.
Return the index of the maximum.
Return the sum over the requested axis.
Return the minimum over the requested axis.
Return the maximum over the requested axis.
Return the index of the minimum over the requested axis.
Return the index of the maximum over the requested axis.
>>> idx = pd.MultiIndex.from_arrays([ . ['warm', 'warm', 'cold', 'cold'], . ['dog', 'falcon', 'fish', 'spider']], . names=['blooded', 'animal']) >>> s = pd.Series([4, 2, 0, 8], name='legs', index=idx) >>> s blooded animal warm dog 4 falcon 2 cold fish 0 spider 8 Name: legs, dtype: int64
Максимальное значение max() в Pandas DataFrame
Чтобы найти максимальное значение в Pandas DataFrame, вы можете использовать метод pandas.DataFrame.max(). Используя max(), вы можете найти максимальное значение по оси: по строкам или по столбцам, или максимум для всего DataFrame.
Пример 1: по столбцам
В этом примере мы рассчитаем максимальное значение по столбцам.
Узнаем самые высокие оценки, полученные студентами по предметам.
import pandas as pd mydictionary = # create dataframe df_marks = pd.DataFrame(mydictionary) print('DataFrame\n----------') print(df_marks) # calculate max along columns mean = df_marks.max() print('\nMaximum Value\n------') print(mean) DataFrame ---------- physics chemistry algebra 0 68 84 78 1 74 56 88 2 77 73 82 3 78 69 87 Maximum Value ------ physics 78 chemistry 84 algebra 88 dtype: int64
Пример 2: по строке
В этом примере мы найдем максимум по строкам DataFrame. Это приводит к нахождению максимальных оценок, полученных студентом по любому предмету.
import pandas as pd mydictionary = # create dataframe df_marks = pd.DataFrame(mydictionary) print('DataFrame\n----------') print(df_marks) # calculate max along columns mean = df_marks.max(axis=1) print('\nMaximum Value\n------') print(mean) DataFrame ---------- physics chemistry algebra 0 68 84 78 1 74 56 88 2 77 73 82 3 78 69 87 Maximum Value ------ 0 84 1 88 2 82 3 87 dtype: int64
Пример 3
В этом примере мы узнаем максимальное значение в DataFrame независимо от строк или столбцов.
В предыдущих примерах мы нашли максимальное значение по столбцам и строкам соответственно. В этих случаях примените функцию max() к результату функции max(), вы получите максимум полного DataFrame.
import pandas as pd mydictionary = # create dataframe df_marks = pd.DataFrame(mydictionary) print('DataFrame\n----------') print(df_marks) # calculate max of whole DataFrame mean = df_marks.max().max() print('\nMaximum Value\n------') print(mean) DataFrame ---------- physics chemistry algebra 0 68 84 78 1 74 56 88 2 77 73 82 3 78 69 87 Maximum Value ------ 88
В этом руководстве по Pandas мы узнали, как получить максимальное значение всего DataFrame, по столбцу (столбцам) и строкам.
Как найти минимальное и максимальное значение в Pandas таблице

Нахождение максимального и минимального значения в Pandas — зачастую, необходимая операция для анализа данных. Поэтому предлагаю попрактиковаться на примере тренировочного датасета: отыскать предельные значения и вывести строки с этими значениями на экран.
Действовать будем по плану:
Сначала поработаем с максимальными значениями:
- Найдем максимальное значение:
- для каждого столбца таблицы;
- в определенном столбце таблицы
- Выведем на экран строки с максимальными значениями
Затем поработаем с минимальными значениями:
- Найдем минимальное значение:
- для каждого столбца таблицы;
- в определенном столбце таблицы
- Выведем на экран строки с минимальными значениями
Загрузка датасета
Для наглядности будем использовать тренировочный датасет с пропорциями некоторых продуктов для приготовления кондитерских изделий. Скачать датасет можно по ссылке: products.csv. Итак, загрузим файл с данными:
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) 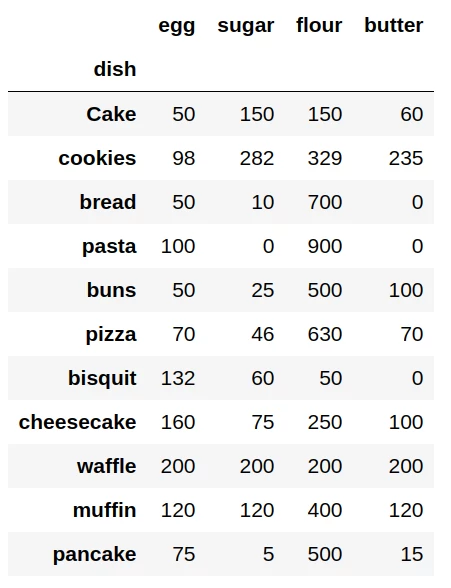
Названия десертов и наименования продуктов представлены в качестве индексов таблицы. Числовое значение в каждой ячейке, расположенной на пересечении строки с десертом и колонки с наименованием продукта — это количество продукта в граммах, необходимое для приготовления 1 кг. изделия.
После загрузки датасета можно переходить к реализации нашего плана и отыскать предельные значения!
Работаем с максимальными значениями
1. Ищем максимальное значение:
# для каждого столбца таблицы:
Получим максимальный вес каждого продукта. Для этого найдем максимальные значения в каждом столбце таблицы с помощью функции max() и выведем их на экран. Применим функцию max() ко всей таблице data:
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) #Получим максимальные значения в каждом столбце maximums = data.max() # выведем результат на экран print(maximums) Полученный результат — максимальные значения в каждом столбце
egg 200 sugar 282 flour 900 butter 235 dtype: int64
# в определенном столбце таблицы:
Узнаем, сколько потребуется сахара для приготовления 1 кг. самого сладкого блюда из представленных в таблице. Для этого получим максимальное значение в столбце «sugar» с помощью функции max(). На этот раз применим функцию max() к столбцу «sugar»:
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) #Получим максимальное значение в столбце "sugar" max_sugar = data['sugar'].max() # выведем результат на экран print(max_sugar) Полученный результат — максимальное значение в столбце «sugar»
Теперь мы знаем, что в 1 кг. самого сладкого блюда из таблицы data содержится 282 грамм сахара. Однако, хотелось бы узнать название этого блюда, а еще лучше — вывести всю строку с информацией о нем:
2. Выводим на экран строку с максимальным значением
Для этого используем полученное значение с максимальным количеством сахара (data[‘sugar’].max()) и выведем строку, для которой выполняется условие data[‘sugar’]==data[‘sugar’].max():
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) # Найдем строку с максимальным значением str = data[data['sugar']==data['sugar'].max()] # Выведем строку на экран print(str) Полученный результат — строка таблицы data с максимальным значением

В соответствии с полученным результатом, самым сладким блюдом из представленных в таблице data являются печенья!
Работаем с минимальными значениями
Главным козырем при нахождении минимальных значений в данных является функция min(). Рассмотрим варианты ее применения для получения желаемого результата:
1. Ищем минимальное значение:
# для каждого столбца таблицы
Выведем на экран минимальные значения в каждом столбце таблицы с помощью функции min(). Для этого применим функцию min() ко всей таблице data:
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) # Найдем минимальные значения в каждом столбце таблицы minimums = data.min() # Выведем результат на экран print(minimums) Полученный результат — минимальные значения в каждом столбце
egg 50 sugar 0 flour 50 butter 0 dtype: int64
# в определенном столбце таблицы:
Найдем минимальное значение в столбце «sugar» с помощью функции min():
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) # Найдем минимальное значение в столбце «sugar» min_sugar = data['sugar'].min() # Выведем найденное значение на экран print(min_sugar) Результат на экране — минимальное значение в столбце «sugar»:
Выходит, что среди размещенных в таблице блюд присутствуют несладкие изделия. Давайте узнаем, какой представитель выпечки самый несладкий: выведем на экран строку с его именем!
2. Выводим на экран строку с минимальным значением
Для этого найдем строку, для которой значение в столбце ‘sugar’ совпадает с найденным ранее минимальным количеством сахара: data[‘sugar’]==data[‘sugar’].min():
import pandas as pd data = pd.read_csv('products.csv', sep=';', index_col='dish') data.head(11) # Найдем строку с минимальным значением str = data[data['sugar']==data['sugar'].min()] # выведем строку на экран print(str) Результат — строка с минимальным значением в столбце «sugar»:
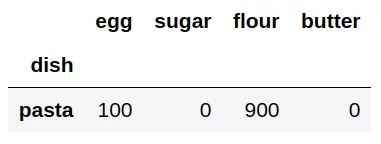
Таким образом, нам удалось выяснить, что в пасте (в соответствии с таблицей data) не содержится сахара. Ах, вот почему она не сладкая! 😉
Теперь, когда все технологические секреты раскрыты, а предельные значения найдены, подведем итоги:
Коротко о поиске максимальных и минимальных значений в pandas:
Дано: датасет data c числовыми значениями в столбцах: «egg», «sugar», «flour», «butter».
1. Получим максимальные / минимальные значения для каждого столбца:
# Максимальные значения - maximums maximums = data.max() # Минимальные значения - minimums minimums = data.min()
2. Получим максимальное / минимальное значение для столбца «sugar»:
# Максимальное значение в столбце "sugar" max_sugar = data['sugar'].max() # Минимальное значение в столбце "sugar" min_sugar = data['sugar'].min()
3. Выведем на экран строку с максимальным / минимальным значением в столбце «sugar»:
# Найдем строку с максимальным значением str = data[data['sugar']==data['sugar'].max()] # выведем строку на экран print(str) # Найдем строку с минимальным значением str = data[data['sugar']==data['sugar'].min()] # выведем строку на экран print(str)

У нас появился Telegram-канал для изучающих Python! Подписывайтесь по ссылке: «Кодим на Python! Вместе «питонить» веселее! 😉