- Get First Row of Pandas DataFrame?
- 1. Quick Examples of How to Get First Row of Pandas DataFrame
- 2. Get the First Row of Pandas using iloc[]
- 3. Get the First Row using loc()
- 4. Get the First Row of Pandas using values()
- 5. Get the First Row of DataFrame using head()
- 6. Get the First Row of Pandas as a List
- 7. Get the First Row of a particular column
- Conclusion
- Related Articles
- References
- You may also like reading:
- Get values, rows and columns in pandas dataframe
- pandas get columns
- The dot notation
- Square brackets notation
- Get multiple columns
- pandas get rows
- Get one row
- Get multiple rows
- pandas get cell values
- Square brackets notation
- .loc[] method
Get First Row of Pandas DataFrame?
By using DataFrame.iloc[0] and head(1) you can select/get the first row of pandas DataFrame. iloc[] is a property that is used to select rows and columns by position/index. If the position/index does not exist, it gives an index error. In this article, I will cover usage of pandas.DataFrame.iloc[] and using this how we can get the first row of Pandas DataFrame in different ways with examples.
pandas loc[] is another property that is used to operate on the column and row labels. For a better understanding of these two learn the differences and similarities between pandas loc[] vs iloc[].
1. Quick Examples of How to Get First Row of Pandas DataFrame
If you are in a hurry, below are some quick examples of how to get the first row of DataFrame.
Let’s create DataFrame using data from the Python dictionary and run the above examples to get the first row of DataFrame.
index_labels=['r1','r2','r3','r4','r5'] df = pd.DataFrame(technologies, columns = ['Courses', 'Fee', 'Duration', 'Discount'], index = index_labels) print(df) # Outputs: Courses Fee Duration Discount r1 Spark 20000 30day 1000 r2 PySpark 25000 40days 2300 r3 Hadoop 26000 35days 1200 r4 Python 22000 40days 2500 r5 pandas 24000 60days 2000 2. Get the First Row of Pandas using iloc[]
Using the Pandas iloc[] attribute we can get the single row or column by using an index, by specifying the index position 0 we can get the first row of DataFrame. iloc[0] will return the first row of DataFrame in the form of Pandas Series.
Related: You can use df.iloc[] to get the last row of DataFrame.
We can also get the first row of Pandas DataFrame by providing an index range i.e. [:1] to iloc[] attribute. This syntax will select the rows from 0 to1 and returned the first row in the form of DataFrame. For example,
3. Get the First Row using loc()
We can also get the first row of DataFrame using the loc[] attribute for that, we have to pass the first row index with the help of the index[] attribute. It will return the first row in the form of Series object.
4. Get the First Row of Pandas using values()
Pandas DataFrame.values attribute is used to return a Numpy representation of the given DataFrame. Use this attribute we can get the first row of DataFrame in the form of NumPy array. Let’s get the first row,
5. Get the First Row of DataFrame using head()
The pandas.DataFrame.head() method returns the first n rows of dataframe. We can use this head() function to get only the first row of the dataframe, for that, we pass ‘1’ as an argument to this function. It will return the first row of DataFrame.
6. Get the First Row of Pandas as a List
As we know from the above, we have got the first row of the DataFrame using df.iloc[0]. It has given the result as a series object. Using the series.tolist() function, we can get the first row of DataFrame in the form of a list. For example,
7. Get the First Row of a particular column
If we want to get value of first row based on particular column, we can pass specified column into DataFrame then call iloc[] attribute. It will return value of first row based on specified column.
Alternatively, we can get the value of the first row based on a particular column using the index range of the iloc[] attribute. It will return the first row value in the form of a Series.
Conclusion
In this article, I have explained the usage of DataFrame.iloc[] and using this how we can get the first row of DataFrame in different ways. As well as I explained how to get the first row of DataFrame using head() and other functions.
Related Articles
- Pandas Difference Between loc[] vs iloc[]
- How to Convert List to Pandas Series
- How to Plot Columns of Pandas DataFrame
- Apache Kafka Producer and Consumer in Scala
- Pandas Select Multiple Columns in DataFrame
- Pandas iloc[] Usage with Examples
- Pandas Get Index from DataFrame
- Python Dictionary Values()
- Get unique rows in Pandas DataFrame
- How to get row numbers in a Pandas DataFrame?
- Get First N row From Pandas DataFrame
References
You may also like reading:
Get values, rows and columns in pandas dataframe
This article is part of the Transition from Excel to Python series. We have walked through the data i/o (reading and saving files) part. Let’s move on to something more interesting. In Excel, we can see the rows, columns, and cells. We can reference the values by using a “=” sign or within a formula. In Python, the data is stored in computer memory (i.e., not directly visible to the users), luckily the pandas library provides easy ways to get values, rows, and columns.
Let’s first prepare a dataframe, so we have something to work with. We’ll use this example file from before, and we can open the Excel file on the side for reference.
>> df User Name Country City Gender Age 0 Forrest Gump USA New York M 50 1 Mary Jane CANADA Tornoto F 30 2 Harry Porter UK London M 20 3 Jean Grey CHINA Shanghai F 30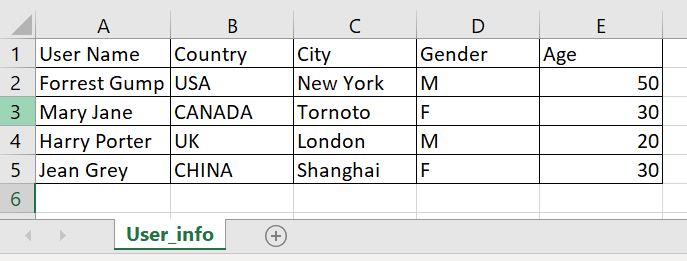
- There are five columns with names: “User Name”, “Country”, “City”, “Gender”, “Age”
- There are 4 rows (excluding the header row)
df.index returns the list of the index, in our case, it’s just integers 0, 1, 2, 3.
df.columns gives the list of the column (header) names.
df.shape shows the dimension of the dataframe, in this case it’s 4 rows by 5 columns.
>> df.columns Index(['User Name', 'Country', 'City', 'Gender', 'Age'], dtype='object') >>> df.shape (4, 5)pandas get columns
There are several ways to get columns in pandas. Each method has its pros and cons, so I would use them differently based on the situation.
The dot notation
We can type df.Country to get the “Country” column. This is a quick and easy way to get columns. However, if the column name contains space, such as “User Name”. This method will not work.
>> df.Age 0 50 1 30 2 20 3 30 Name: Age, dtype: int64 >>> df.User Name SyntaxError: invalid syntaxSquare brackets notation
This is my personal favorite. It requires a dataframe name and a column name, which goes like this: dataframe[column name] . The column name inside the square brackets is a string, so we have to use quotation around it. Although it requires more typing than the dot notation, this method will always work in any cases. Because we wrap around the string (column name) with a quote, names with spaces are also allowed here.
>> df['City'] 0 New York 1 Tornoto 2 London 3 Shanghai Name: City, dtype: objectGet multiple columns
The square bracket notation makes getting multiple columns easy. The syntax is similar, but instead, we pass a list of strings into the square brackets. Pay attention to the double square brackets:
dataframe[ [column name 1, column name 2, column name 3, . ] ]
pandas get rows
We can use .loc[] to get rows. Note the square brackets here instead of the parenthesis (). The syntax is like this: df.loc[row, column] . column is optional, and if left blank, we can get the entire row. Because Python uses a zero-based index, df.loc[0] returns the first row of the dataframe.
Get one row
>> df.loc[2] User Name Harry Porter Country UK City London Gender M Age 20 Name: 2, dtype: objectGet multiple rows
We’ll have to use indexing/slicing to get multiple rows. In pandas, this is done similar to how to index/slice a Python list.
To get the first three rows, we can do the following:
pandas get cell values
To get individual cell values, we need to use the intersection of rows and columns. Think about how we reference cells within Excel, like a cell “C10”, or a range “C10:E20”. The follow two approaches both follow this row & column idea.
Square brackets notation
Using the square brackets notation, the syntax is like this: dataframe[column name][row index] . This is sometimes called chained indexing. An easier way to remember this notation is: dataframe[column name] gives a column, then adding another [row index] will give the specific item from that column.
Let’s say we want to get the City for Mary Jane (on row 2).
To get the 2nd and the 4th row, and only the User Name, Gender and Age columns, we can pass the rows and columns as two lists like the below.
Remember, df[[‘User Name’, ‘Age’, ‘Gender’]] returns a new dataframe with only three columns. Then .loc[ [ 1,3 ] ] returns the 1st and 4th rows of that dataframe.
.loc[] method
As previously mentioned, the syntax for .loc is df.loc[row, column] . Need a reminder on what are the possible values for rows (index) and columns?
>> df.columns Index(['User Name', 'Country', 'City', 'Gender', 'Age'], dtype='object')Let’s try to get the country name for Harry Porter, who’s on row 3.
To get the 2nd and the 4th row, and only the User Name, Gender and Age columns, we can pass the rows and columns as two lists into the “row” and “column” positional arguments.