- pandas.DataFrame.assign#
- pandas.DataFrame.insert#
- Как вставить столбец в фрейм данных Pandas
- Пример 1: вставить новый столбец в качестве первого столбца
- Пример 2. Вставьте новый столбец в качестве среднего столбца
- Пример 3: вставить новый столбец в качестве последнего столбца
- 4 способа добавления колонок в датафреймы Pandas
- Способ 1-й
- Способ 2-й
- Способ 3-й
- Способ 4-й
- Заключение
pandas.DataFrame.assign#
Returns a new object with all original columns in addition to new ones. Existing columns that are re-assigned will be overwritten.
Parameters **kwargs dict of
The column names are keywords. If the values are callable, they are computed on the DataFrame and assigned to the new columns. The callable must not change input DataFrame (though pandas doesn’t check it). If the values are not callable, (e.g. a Series, scalar, or array), they are simply assigned.
A new DataFrame with the new columns in addition to all the existing columns.
Assigning multiple columns within the same assign is possible. Later items in ‘**kwargs’ may refer to newly created or modified columns in ‘df’; items are computed and assigned into ‘df’ in order.
>>> df = pd.DataFrame('temp_c': [17.0, 25.0]>, . index=['Portland', 'Berkeley']) >>> df temp_c Portland 17.0 Berkeley 25.0
Where the value is a callable, evaluated on df :
>>> df.assign(temp_f=lambda x: x.temp_c * 9 / 5 + 32) temp_c temp_f Portland 17.0 62.6 Berkeley 25.0 77.0
Alternatively, the same behavior can be achieved by directly referencing an existing Series or sequence:
>>> df.assign(temp_f=df['temp_c'] * 9 / 5 + 32) temp_c temp_f Portland 17.0 62.6 Berkeley 25.0 77.0
You can create multiple columns within the same assign where one of the columns depends on another one defined within the same assign:
>>> df.assign(temp_f=lambda x: x['temp_c'] * 9 / 5 + 32, . temp_k=lambda x: (x['temp_f'] + 459.67) * 5 / 9) temp_c temp_f temp_k Portland 17.0 62.6 290.15 Berkeley 25.0 77.0 298.15
pandas.DataFrame.insert#
Raises a ValueError if column is already contained in the DataFrame, unless allow_duplicates is set to True.
Parameters loc int
Insertion index. Must verify 0
column str, number, or hashable object
Label of the inserted column.
value Scalar, Series, or array-like allow_duplicates bool, optional, default lib.no_default
>>> df = pd.DataFrame('col1': [1, 2], 'col2': [3, 4]>) >>> df col1 col2 0 1 3 1 2 4 >>> df.insert(1, "newcol", [99, 99]) >>> df col1 newcol col2 0 1 99 3 1 2 99 4 >>> df.insert(0, "col1", [100, 100], allow_duplicates=True) >>> df col1 col1 newcol col2 0 100 1 99 3 1 100 2 99 4
Notice that pandas uses index alignment in case of value from type Series :
>>> df.insert(0, "col0", pd.Series([5, 6], index=[1, 2])) >>> df col0 col1 col1 newcol col2 0 NaN 100 1 99 3 1 5.0 100 2 99 4
Как вставить столбец в фрейм данных Pandas
Часто вам может понадобиться вставить новый столбец в pandas DataFrame. К счастью, это легко сделать с помощью функции вставки () pandas, которая использует следующий синтаксис:
вставка (local, столбец, значение, allow_duplicates = False)
- loc: Индекс для вставки столбца. Первый столбец равен 0.
- столбец: Имя для нового столбца.
- value: Массив значений для нового столбца.
- allow_duplicates: разрешить или запретить совпадение имени нового столбца с именем существующего столбца. По умолчанию — Ложь.
В этом руководстве показано несколько примеров использования этой функции на практике.
Пример 1: вставить новый столбец в качестве первого столбца
Следующий код показывает, как вставить новый столбец в качестве первого столбца существующего DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df points assists rebounds 0 25 5 11 1 12 7 8 2 15 7 10 3 14 9 6 4 19 12 6 #insert new column 'player' as first column player_vals = ['A', 'B', 'C', 'D', 'E'] df.insert (loc= 0 , column='player', value=player_vals) df player points assists rebounds 0 A 25 5 11 1 B 12 7 8 2 C 15 7 10 3 D 14 9 6 4 E 19 12 6 Пример 2. Вставьте новый столбец в качестве среднего столбца
Следующий код показывает, как вставить новый столбец в качестве третьего столбца существующего DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #insert new column 'player' as third column player_vals = ['A', 'B', 'C', 'D', 'E'] df.insert (loc= 2 , column='player', value=player_vals) df points assists player rebounds 0 25 5 A 11 1 12 7 B 8 2 15 7 C 10 3 14 9 D 6 4 19 12 E 6 Пример 3: вставить новый столбец в качестве последнего столбца
Следующий код показывает, как вставить новый столбец в качестве последнего столбца существующего DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #insert new column 'player' as last column player_vals = ['A', 'B', 'C', 'D', 'E'] df.insert (loc= len(df.columns) , column='player', value=player_vals) df points assists player rebounds 0 25 5 A 11 1 12 7 B 8 2 15 7 C 10 3 14 9 D 6 4 19 12 E 6 Обратите внимание, что использование len(df.columns) позволяет вставить новый столбец в качестве последнего столбца в любом фрейме данных, независимо от того, сколько столбцов в нем может быть.
Вы можете найти полную документацию по функции insert() здесь .
4 способа добавления колонок в датафреймы Pandas

Pandas — это библиотека для анализа и обработки данных, написанная на языке Python. Она предоставляет множество функций и способов для управления табличными данными. Основная структура данных Pandas — это датафрейм, который хранит информацию в табличной форме с помеченными строками и столбцами.
В контексте данных строки представляют собой утверждения, или точки данных. Столбцы отражают свойства, или атрибуты утверждений. Рассмотрим эту структуру на простом примере. Допустим, каждая строка — это дом. В таком случае, столбцы заключают в себе сведения об этом доме (его возрасте, количестве комнат, стоимости и т.д.).
Добавление или удаление столбцов — обычная операция при анализе данных. Ниже мы разберем 4 различных способа добавления новых столбцов в датафрейм Pandas.
Сначала создадим простой фрейм данных для использования в примерах:
import numpy as np import pandas as pd df = pd.DataFrame() df
Способ 1-й
Пожалуй, это самый распространенный путь создания нового столбца в Pandas:

Мы указываем имя столбца подобно тому, как выбираем столбец во фрейме данных. Затем этому столбцу присваиваются значения. Новый столбец добавляется последним (т. е. становится столбцом с самым высоким индексом).
Можно добавить сразу несколько столбцов. Их наименования перечисляются списком, а значения должны быть двумерными для совместимости с количеством строк и столбцов. Например, следующий код добавляет три столбца, заполненные случайными целыми числами от 0 до 10:
df[["1of3", "2of3", "3of3"]] = np.random.randint(10, size=(4,3)) df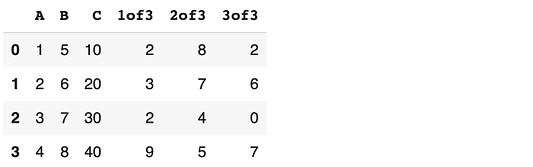
Давайте удалим эти три столбца, прежде чем перейти к следующему методу.
df.drop(["1of3", "2of3", "3of3"], axis=1, inplace=True)
Способ 2-й
В первом способе мы добавляли новый столбец в конец. Pandas также позволяет добавлять столбцы по определенному индексу. Для настройки расположения нового столба воспользуемся функцией вставки (insert function). Давайте добавим один столбец рядом с А:

Для использования функции вставки необходимо 3 параметра: индекс, имя столбца и значение. Индексы столбцов начинаются с 0, поэтому мы устанавливаем параметр индекса 1, чтобы добавить новый столбец рядом со столбцом A. Мы можем указать постоянное значение, которое будет выставлено во всех строках.
Способ 3-й
Функция loc позволяет выбирать строки и столбцы, используя их метки. Таким же образом можно создать новый столбец:

Для выбора строк и столбцов мы указываем нужные метки. Если хотим выбрать все строки, ставим двоеточие. В части таблицы, где нужно проставить столбец, указываем метки столбцов, которые нам необходимо выбрать. Поскольку в датафрейме нет столбца E, Pandas создаст новый столбец.
Способ 4-й
Добавить столбцы можно также с помощью функции assign :
df = df.assign(F = df.C * 10) df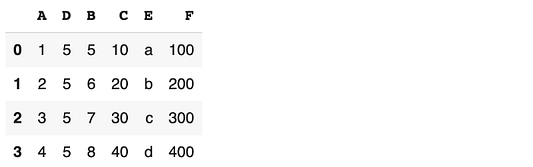
В функции assign необходимо прописать имя столбца и значения. Обратите внимание: мы получаем значения, используя другой столбец во фрейме данных. Предыдущие способы также допускают такую операцию.
Надо понимать, что между функциями assign и insert есть существенное различие.
Функция вставки ( insert ) работает на месте. Это означает, что изменение (добавление нового столбца) сохраняется во фрейме данных.
С функцией назначения ситуация немного иная. Он возвращает измененный фрейм данных, но не изменяет исходный. Чтобы использовать измененную версию (с новым столбцом), нам нужно явно назначить ее.
Заключение
Мы рассмотрели 4 различных способа добавления новых столбцов в фрейм данных Pandas. Это обычная операция при анализе и обработке данных.
Мне нравится пользоваться библиотекой Pandas, поскольку она предоставляет, как правило, несколько способов для выполнения одной задачи. По-моему, это говорит о гибкости и универсальности Pandas.