- Web Scraping с помощью python
- Задача
- Инструменты
- Загрузка данных
- Первая попытка
- Разберемся, как работает браузер
- Скачаем все оценки
- Парсинг
- Немного про XPath
- Вернемся к нашей задаче
- Резюме
- UPD
- Python how to load html file in python
- How to parse local HTML file in Python?
- Modifying the file
- Python — Reading HTML Pages
- Install Beautifulsoup
- Reading the HTML file
- Extracting Tag Value
- Extracting All Tags
Web Scraping с помощью python
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup, lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
import requests user_id = 12345 url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url для второй страницы r = requests.get(url) with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251'))
Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью «Сеть» в «Инструментах разработчика» в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
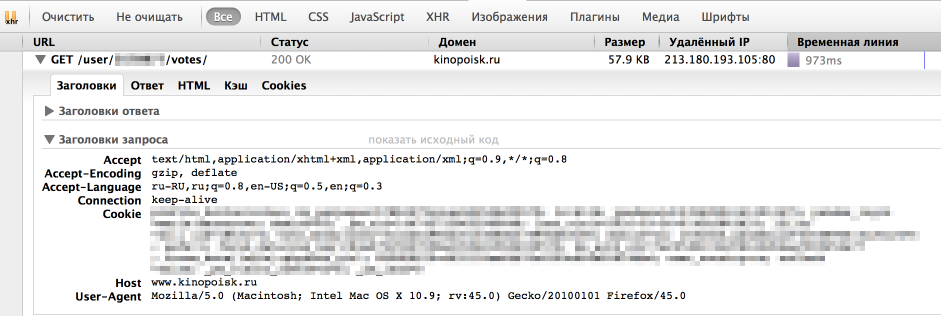
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = < 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' >r = requests.get(url, headers = headers)На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: «Как понять сколько всего страниц с оценками?» Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов ( ).

import requests # establishing session s = requests.Session() s.headers.update(< 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' >) def load_user_data(user_id, page, session): url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page) request = session.get(url) return request.text def contain_movies_data(text): soup = BeautifulSoup(text) film_list = soup.find('div', ) return film_list is not None # loading files page = 1 while True: data = load_user_data(user_id, page, s) if contain_movies_data(data): with open('./page_%d.html' % (page), 'w') as output_file: output_file.write(data.encode('cp1251')) page += 1 else: breakПарсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
from lxml import html test = ''' one
two
another tag
''' tree = html.fromstring(test) tree.xpath('//h2') # все h2 теги tree.xpath('//h2[@align]') # h2 теги с атрибутом align tree.xpath('//h2[@align="center"]') # h2 теги с атрибутом align равным "center" div_node = tree.xpath('//div')[0] # div тег div_node.xpath('.//h2') # все h2 теги, которые являются дочерними div ноде Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию «Инспектировать элемент» в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге . Выделим эту ноду:
from bs4 import BeautifulSoup from lxml import html # Beautiful Soup soup = BeautifulSoup(text) film_list = soup.find('div', ) # lxml tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0]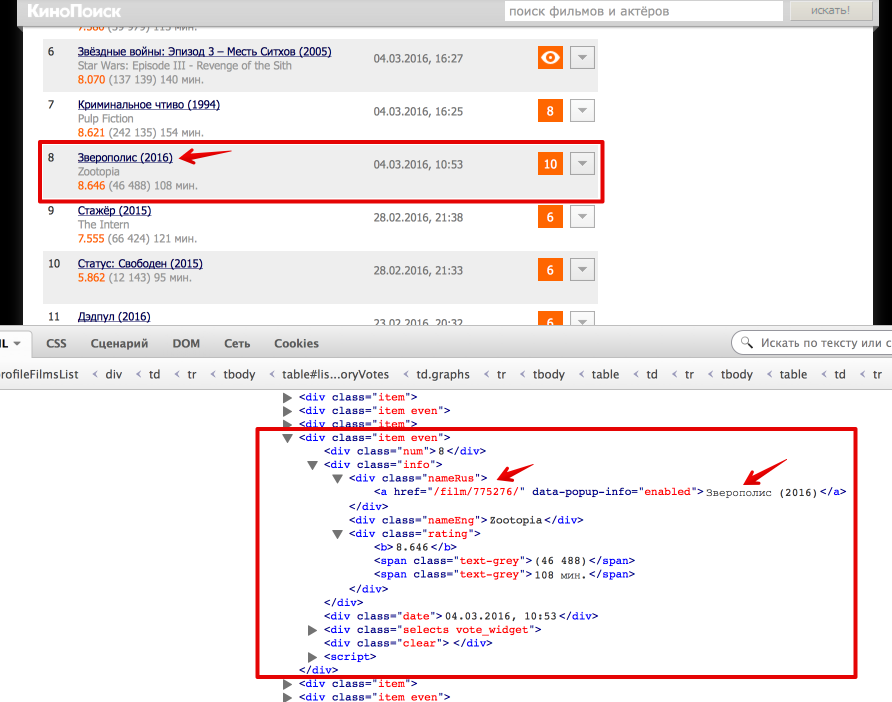
Каждый фильм представлен как или . Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
# Beatiful Soup movie_link = item.find('div', ).find('a').get('href') movie_desc = item.find('div', ).find('a').text # lxml movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0]Еще небольшой хинт для debug’a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
# BeatifulSoup print item #lxml from lxml import etree print etree.tostring(item_lxml)def read_file(filename): with open(filename) as input_file: text = input_file.read() return text def parse_user_datafile_bs(filename): results = [] text = read_file(filename) soup = BeautifulSoup(text) film_list = film_list = soup.find('div', ) items = film_list.find_all('div', ) for item in items: # getting movie_id movie_link = item.find('div', ).find('a').get('href') movie_desc = item.find('div', ).find('a').text movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item.find('div', ).text #getting watch time watch_datetime = item.find('div', ).text date_watched, time_watched = re.match('(\d\.\d\.\d), (\d:\d)', watch_datetime).groups() # getting user rating user_rating = item.find('div', ).text if user_rating: user_rating = int(user_rating) results.append(< 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc >) return results def parse_user_datafile_lxml(filename): results = [] text = read_file(filename) tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] items_lxml = film_list_lxml.xpath('//div[@class = "item even" or @class = "item"]') for item_lxml in items_lxml: # getting movie id movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item_lxml.xpath('.//div[@class = "nameEng"]/text()')[0] # getting watch time watch_datetime = item_lxml.xpath('.//div[@class = "date"]/text()')[0] date_watched, time_watched = re.match('(\d\.\d\.\d), (\d:\d)', watch_datetime).groups() # getting user rating user_rating = item_lxml.xpath('.//div[@class = "vote"]/text()') if user_rating: user_rating = int(user_rating[0]) results.append(< 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc >) return resultsРезюме

В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github’e.
UPD
- Аутентификация: зачастую для того, чтобы получить данные с сайта нужно пройти аутентификацию, в простейшем случае это просто HTTP Basic Auth: логин и пароль. Тут нам снова поможет библиотека Requests. Кроме того, широко распространена oauth2: как использовать oauth2 в python можно почитать на stackoverflow. Также в комментариях есть пример от Terras того, как пройти аутентификацию в web-форме.
- Контролы: На сайте также могут быть дополнительные web-формы (выпадающие списки, check box’ы итд). Алгоритм работы с ними примерно тот же: смотрим, что посылает браузер и отправляем эти же параметры как data в POST-запрос (Requests, stackoverflow). Также могу порекомендовать посмотреть 2й урок курса «Data Wrangling» на Udacity, где подробно рассмотрен пример scrapping сайта US Department of Transportation и посылка данных web-форм.
Python how to load html file in python
Here are a few ways how we can open HTML files on chrome: Method 1: Using os and webbrowser The webbrowser module in python provides a high-level interface to allow displaying Web-based documents to users, and the os module provides a portable way of using operating system dependent functionalities (like reading or writing files, manipulating file paths etc.). We can simply run the html file in new browser using the given steps: File in Use: GFG.html Approach Create a html file that you want to open In Python, Import module Call html file using open_new_tab()
How to parse local HTML file in Python?
Prerequisites : Beautifulsoup
Parsing means dividing a file or input into pieces of information/data that can be stored for our personal use in the future. Sometimes, we need data from an existing file stored on our computers, parsing technique can be used in such cases. The parsing includes multiple techniques used to extract data from a file. The following includes Modifying the file, Removing something from the file, Printing data, using the recursive child generator method to traverse data from the file, finding the children of tags , web scraping from a link to extract useful information, etc.
Modifying the file
Using the prettify method to modify the HTML code from- https://festive-knuth-1279a2.netlify.app/, look better. Prettify makes the code look in the standard form like the one used in VS Code .
Python — Reading HTML Pages
library known as beautifulsoup. Using this library, we can search for the values of html tags and get specific data like title of the page and the list of headers in the page.
Install Beautifulsoup
Use the Anaconda package manager to install the required package and its dependent packages.
conda install Beaustifulsoap
Reading the HTML file
In the below example we make a request to an url to be loaded into the python environment. Then use the html parser parameter to read the entire html file. Next, we print first few lines of the html page.
import urllib2 from bs4 import BeautifulSoup # Fetch the html file response = urllib2.urlopen('http://tutorialspoint.com/python/python_overview.htm') html_doc = response.read() # Parse the html file soup = BeautifulSoup(html_doc, 'html.parser') # Format the parsed html file strhtm = soup.prettify() # Print the first few characters print (strhtm[:225]) When we execute the above code, it produces the following result.
Extracting Tag Value
We can extract tag value from the first instance of the tag using the following code.
import urllib2 from bs4 import BeautifulSoup response = urllib2.urlopen('http://tutorialspoint.com/python/python_overview.htm') html_doc = response.read() soup = BeautifulSoup(html_doc, 'html.parser') print (soup.title) print(soup.title.string) print(soup.a.string) print(soup.b.string) When we execute the above code, it produces the following result.
Python Overview None Python is Interpreted
Extracting All Tags
We can extract tag value from all the instances of a tag using the following code.
import urllib2 from bs4 import BeautifulSoup response = urllib2.urlopen('http://tutorialspoint.com/python/python_overview.htm') html_doc = response.read() soup = BeautifulSoup(html_doc, 'html.parser') for x in soup.find_all('b'): print(x.string) When we execute the above code, it produces the following result.
Python is Interpreted Python is Interactive Python is Object-Oriented Python is a Beginner's Language Easy-to-learn Easy-to-read Easy-to-maintain A broad standard library Interactive Mode Portable Extendable Databases GUI Programming Scalable