Самая длинная общая подстрока Python
Задача состоит в том, чтобы найти самую длинную общую подстроку в заданной строке. Задача состоит в том, чтобы взять две строки и найти самую длинную общую подстроку с повторяющимися символами или без них. Другими словами, найти самую длинную общую подстроку, заданную в том же порядке и присутствующую в обеих строках. Например, «Tech» — это последовательность символов, заданная в «NextTech», которая также является подстрокой.
Процесс поиска самой длинной общей подпоследовательности:
Самый простой процесс поиска самой длинной общей подпоследовательности состоит в том, чтобы проверить каждый символ строки 1 и найти то же самое. последовательность в строке 2, проверяя каждый символ строки 2 один за другим, чтобы увидеть, является ли какая-либо подстрока общей в обеих строках. струны. Например, предположим, что у нас есть строка 1 «st1» и строка 2 «st2» с длинами a и b соответственно. Проверьте все подстроки «st1» и начните перебирать «st2», чтобы проверить, существует ли какая-либо подстрока «st1» как «st2». Начните с сопоставления подстроки длины 2 и увеличения длины на 1 на каждой итерации, доводя до максимальной длины строк.
Пример 1:
Этот пример посвящен поиску самой длинной общей подстроки с повторяющимися символами. Python предоставляет простые встроенные методы для выполнения любых функций. В приведенном ниже примере мы предоставили самый простой способ найти самую длинную общую подпоследовательность в двух строках. Комбинация циклов for и while используется для получения самой длинной общей подстроки в строке. Взгляните на пример, приведенный ниже:
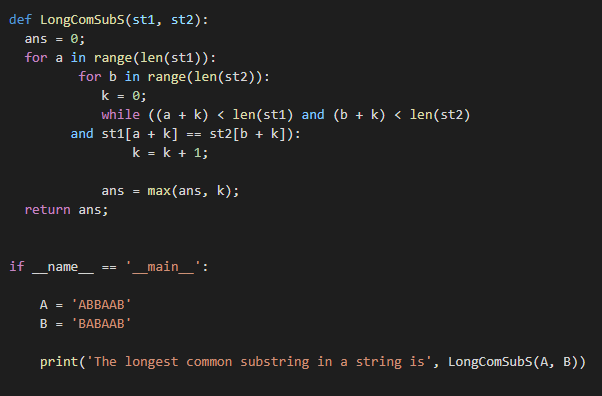
деф LongComSubS ( ст1 , ст2 ) :
ответ = 0 ;
за а в диапазон ( Лен ( ст1 ) ) :
за б в диапазон ( Лен ( ст2 ) ) :
к = 0 ;
пока ( ( а + к ) < Лен ( ст1 ) и ( б + к ) < Лен ( ст2 )
и ст1 [ а + к ] == ст2 [ б + к ] ) :
к = к + 1 ;
ответ = Максимум ( ответ , к ) ;
возвращение ответ ;
если __название__ == ‘__главный__’ :
Распечатать ( ‘Самая длинная общая подстрока в строке’ , LongComSubS ( А , Б ) )
Следующий вывод будет получен после выполнения вышеуказанного кода. Он найдет самую длинную общую подстроку и выдаст вам результат.

Пример 2:
Другой способ найти самую длинную общую подстроку — использовать итеративный подход. Цикл for используется для итерации, а условие if соответствует общей подстроке.
деф LongComSubS ( А , Б , м , н ) :
НАЙТИ = [ [ 0 за Икс в диапазон ( п + 1 ) ] за у в диапазон ( м + 1 ) ]
за я в диапазон ( 1 , м + 1 ) :
за Дж в диапазон ( 1 , п + 1 ) :
если А [ я — 1 ] == Б [ дж — 1 ] :
НАЙТИ [ я ] [ Дж ] = НАЙТИ [ я — 1 ] [ дж — 1 ] + 1
если НАЙТИ [ я ] [ Дж ] > максДлен:
макслен = НАЙТИ [ я ] [ Дж ]
endIndex = я
возвращение Икс [ endIndex — maxLen: endIndex ]
если __название__ == ‘__главный__’ :
Распечатать ( ‘Самая длинная общая подстрока в строке’ , LongComSubS ( А , Б , я , Дж ) )

Выполните приведенный выше код в любом интерпретаторе Python, чтобы получить желаемый результат. Однако мы использовали инструмент Spyder для выполнения программы поиска самой длинной общей подстроки в строке. Вот вывод приведенного выше кода:

Пример 3:
Вот еще один пример, который поможет вам найти самую длинную общую подстроку в строке, используя кодирование Python. Этот метод является самым маленьким, простым и легким способом найти самую длинную общую подпоследовательность. Взгляните на пример кода, приведенный ниже:
деф _итер ( ) :
за а , б в молния ( ст1 , ст2 ) :
если а == б:
урожай а
еще :
возвращение
возвращение » . присоединиться ( _итер ( ) )
если __название__ == ‘__главный__’ :
Распечатать ( ‘Самая длинная общая подстрока в строке’ , LongComSubS ( А , Б ) )

Ниже вы можете найти вывод кода, приведенного выше.

Используя этот метод, мы вернули не общую подстроку, а длину этой общей подстроки. Чтобы помочь вам получить желаемый результат, мы показали как результаты, так и методы получения этих результатов.
Временная сложность и пространственная сложность для нахождения самой длинной общей подстроки
За выполнение или выполнение любой функции нужно платить; временная сложность является одной из этих затрат. Временная сложность любой функции рассчитывается путем анализа того, сколько времени может потребоваться для выполнения оператора. Следовательно, чтобы найти все подстроки в «st1», нам нужно O (a ^ 2), где «a» — длина «st1», а «O» — символ временной сложности. Однако временная сложность итерации и определение того, существует ли подстрока в «st2» или нет, составляет O (m), где «m» — длина «st2». Таким образом, общая временная сложность обнаружения самой длинной общей подстроки в двух строках составляет O(a^2*m). Более того, объемная сложность — это еще одна стоимость выполнения программы. Сложность пространства представляет собой пространство, которое программа или функция будет сохранять в памяти во время выполнения. Следовательно, пространственная сложность поиска самой длинной общей подпоследовательности составляет O (1), поскольку для ее выполнения не требуется никакого места.
Вывод:
В этой статье мы узнали о методах поиска самой длинной общей подстроки в строке с помощью программирования на Python. Мы предоставили три простых и легких примера, чтобы получить самую длинную общую подстроку в python. В первом примере используется комбинация циклов for и while. В то время как во втором примере мы следовали итеративному подходу, используя цикл for и логику if. Напротив, в третьем примере мы просто использовали встроенную функцию python для получения длины общей подстроки в строке. Напротив, временная сложность поиска самой длинной общей подстроки в строке с использованием python составляет O (a ^ 2 * m), где a и ma — длина двух строк; строка 1 и строка 2 соответственно.
Даны две строки с первой и второй надписью. Выведите общую часть
Оля вырезает трафареты для надписей на футболке. У неё есть две надписи. Чтобы сэкономить время, она отрезала конец первого трафарета, добавила к нему справа недостающие буквы и так получила второй трафарет. Общая часть должна быть максимально возможной длины.
Даны две строки с первой и второй надписью. Выведите общую часть.
Даны две строки.Выведите на экран все символы которые присутствуют как в первой так и во второй строке
Даны две строки.Выведите на экран все символы которые присутствуют как в первой так и во второй.

Даны две строки. Удалить в первой строке первое вхождение второй строки
Посмотрите пж ребят и напишите , правильно ли я написал. int main() < setlocale(LC_ALL.
Даны две строки. Из первой строки удалить слова, встречающиеся во второй строке
Ребята, нужна помощь! Помогите пожалуйста! Сам я не очень шарю в ассемблере. В общем, даны 2.
Даны две строки. Получить строку, в которой чередуются слова первой и второй строки
Даны две строки. Получить строку, в которой чередуются слова первой и второй строки. Если в одной.
Даны две строки. Из множества символов первой строки удалить символы содержащиеся во второй строке.
составить программу для решения задач: 6. Даны две строки. Из множества символов первой строки.
q = input() w = input() s = w for i in w: if i not in q: w = w.replace(i, '') for i in q: if i not in s: q = q.replace(i, '') print(w)
q = input() w = input() for i in w: if i not in q: w = w.replace(i, '') if w in q: print(w)
for i in (w if len(w) > len(q) else q)
q = input() w = input() for i in (w if len(w) > len(q) else q): if i not in q: w = w.replace(i, '') if w in q: print(w)
from difflib import SequenceMatcher def longest_Substring(s1,s2): seq_match = SequenceMatcher(None,s1,s2) match = seq_match.find_longest_match(0, len(s1), 0, len(s2)) if (match.size!=0): return (s1[match.a: match.a + match.size]) else: return ('') s1 =input() s2 =input() print(longest_Substring(s1,s2))
Код не срабатывает только в одном случае: у слов «урок» и «рука» он выводит общую букву «у». Вообще, по условию задачи, это правильно, т.к. «у» – это и есть общая часть максимально возможной длины. Но ответ считается системой неверным.
Строки. Функции и методы строк

Итак, о работе со строками мы немного поговорили, теперь поговорим о функциях и методах строк.
Я постарался собрать здесь все строковые методы и функции, но если я что-то забыл — поправляйте.
Базовые операции
При вызове методов необходимо помнить, что строки в Python относятся к категории неизменяемых последовательностей, то есть все функции и методы могут лишь создавать новую строку.
: Поэтому все строковые методы возвращают новую строку, которую потом следует присвоить переменной. Таблица «Функции и методы строк»
| Функция или метод | Назначение |
|---|---|
| S = ‘str’; S = «str»; S = »’str»’; S = «»»str»»» | Литералы строк |
| S = «s\np\ta\nbbb» | Экранированные последовательности |
| S = r»C:\temp\new» | Неформатированные строки (подавляют экранирование) |
| S = b»byte» | Строка байтов |
| S1 + S2 | Конкатенация (сложение строк) |
| S1 * 3 | Повторение строки |
| S[i] | Обращение по индексу |
| S[i:j:step] | Извлечение среза |
| len(S) | Длина строки |
| S.find(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер первого вхождения или -1 |
| S.rfind(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер последнего вхождения или -1 |
| S.index(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError |
| S.rindex(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError |
| S.replace(шаблон, замена[, maxcount]) | Замена шаблона на замену. maxcount ограничивает количество замен |
| S.split(символ) | Разбиение строки по разделителю |
| S.isdigit() | Состоит ли строка из цифр |
| S.isalpha() | Состоит ли строка из букв |
| S.isalnum() | Состоит ли строка из цифр или букв |
| S.islower() | Состоит ли строка из символов в нижнем регистре |
| S.isupper() | Состоит ли строка из символов в верхнем регистре |
| S.isspace() | Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы (‘\f’), «новая строка» (‘\n’), «перевод каретки» (‘\r’), «горизонтальная табуляция» (‘\t’) и «вертикальная табуляция» (‘\v’)) |
| S.istitle() | Начинаются ли слова в строке с заглавной буквы |
| S.upper() | Преобразование строки к верхнему регистру |
| S.lower() | Преобразование строки к нижнему регистру |
| S.startswith(str) | Начинается ли строка S с шаблона str |
| S.endswith(str) | Заканчивается ли строка S шаблоном str |
| S.join(список) | Сборка строки из списка с разделителем S |
| ord(символ) | Символ в его код ASCII |
| chr(число) | Код ASCII в символ |
| S.capitalize() | Переводит первый символ строки в верхний регистр, а все остальные в нижний |
| S.center(width, [fill]) | Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию) |
| S.count(str, [start],[end]) | Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию) |
| S.expandtabs([tabsize]) | Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам |
| S.lstrip([chars]) | Удаление пробельных символов в начале строки |
| S.rstrip([chars]) | Удаление пробельных символов в конце строки |
| S.strip([chars]) | Удаление пробельных символов в начале и в конце строки |
| S.partition(шаблон) | Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки |
| S.rpartition(sep) | Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку |
| S.swapcase() | Переводит символы нижнего регистра в верхний, а верхнего – в нижний |
| S.title() | Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний |
| S.zfill(width) | Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями |
| S.ljust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar |
| S.rjust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar |
| S.format(*args, **kwargs) | Форматирование строки |
Для вставки кода на Python в комментарий заключайте его в теги