- Saved searches
- Use saved searches to filter your results more quickly
- read_csv C-engine CParserError: Error tokenizing data #11166
- read_csv C-engine CParserError: Error tokenizing data #11166
- Comments
- How to Solve Error Tokenizing Data on read_csv in Pandas
- Step 1: Analyze and Skip Bad Lines for Error Tokenizing Data
- Step 2: Use correct separator to solve Pandas tokenizing error
- Step 3: Use different engine for read_csv()
- Step 4: Identify the headers to solve Error Tokenizing Data
- Step 5: Autodetect skiprows for read_csv()
- Conclusion
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
read_csv C-engine CParserError: Error tokenizing data #11166
read_csv C-engine CParserError: Error tokenizing data #11166
Comments
I have encountered a dataset where the C-engine read_csv has problems. I am unsure of the exact issue but I have narrowed it down to a single row which I have pickled and uploaded it to dropbox. If you obtain the pickle try the following:
df = pd.read_pickle('faulty_row.pkl') df.to_csv('faulty_row.csv', encoding='utf8', index=False) df.read_csv('faulty_row.csv', encoding='utf8')
I get the following exception:
CParserError: Error tokenizing data. C error: Buffer overflow caught - possible malformed input file. If you try and read the CSV using the python engine then no exception is thrown:
df.read_csv('faulty_row.csv', encoding='utf8', engine='python')
Suggesting that the issue is with read_csv and not to_csv. The versions I using are:
INSTALLED VERSIONS ------------------ commit: None python: 2.7.10.final.0 python-bits: 64 OS: Linux OS-release: 3.19.0-28-generic machine: x86_64 processor: x86_64 byteorder: little LC_ALL: None LANG: en_GB.UTF-8 pandas: 0.16.2 nose: 1.3.7 Cython: 0.22.1 numpy: 1.9.2 scipy: 0.15.1 IPython: 3.2.1 patsy: 0.3.0 tables: 3.2.0 numexpr: 2.4.3 matplotlib: 1.4.3 openpyxl: 1.8.5 xlrd: 0.9.3 xlwt: 1.0.0 xlsxwriter: 0.7.3 lxml: 3.4.4 bs4: 4.3.2 The text was updated successfully, but these errors were encountered:
I’m encountering this error as well. Using the method suggested by @chris-b1 causes the following error:
Traceback (most recent call last): File "C:/Users/je/Desktop/Python/comparison.py", line 30, in encoding='utf-8', engine='c') File "C:\Program Files\Python 3.5\lib\site-packages\pandas\io\parsers.py", line 498, in parser_f return _read(filepath_or_buffer, kwds) File "C:\Program Files\Python 3.5\lib\site-packages\pandas\io\parsers.py", line 275, in _read parser = TextFileReader(filepath_or_buffer, **kwds) File "C:\Program Files\Python 3.5\lib\site-packages\pandas\io\parsers.py", line 590, in __init__ self._make_engine(self.engine) File "C:\Program Files\Python 3.5\lib\site-packages\pandas\io\parsers.py", line 731, in _make_engine self._engine = CParserWrapper(self.f, **self.options) File "C:\Program Files\Python 3.5\lib\site-packages\pandas\io\parsers.py", line 1103, in __init__ self._reader = _parser.TextReader(src, **kwds) File "pandas\parser.pyx", line 515, in pandas.parser.TextReader.__cinit__ (pandas\parser.c:4948) File "pandas\parser.pyx", line 705, in pandas.parser.TextReader._get_header (pandas\parser.c:7386) File "pandas\parser.pyx", line 829, in pandas.parser.TextReader._tokenize_rows (pandas\parser.c:8838) File "pandas\parser.pyx", line 1833, in pandas.parser.raise_parser_error (pandas\parser.c:22649) pandas.parser.CParserError: Error tokenizing data. C error: Calling read(nbytes) on source failed. Try engine='python'. I have also found this issue when reading a large csv file with the default egine. If I use engine=’python’ then it works fine.
I missed @alfonsomhc answer because it just looked like a comment.
df = pd.read_csv('test.csv', engine='python') had the same issue trying to read a folder not a csv file
Has anyone investigated this issue? It’s killing performance when using read_csv in a keras generator.
The original data provided is no longer available so the issue is not reproducible. Closing as it’s not clear what the issue is, but @dgrahn or anyone else if you can provide a reproducible example we can reopen
@WillAyd Let me know if you need additional info.
Since GitHub doesn’t accept CSVs, I changed the extension to .txt.
Here’s the code which will trigger the exception.
for chunk in pandas.read_csv('debug.csv', chunksize=1000, names=range(2504)): pass
Here’s the exception from Windows 10, using Anaconda.
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import pandas >>> for chunk in pandas.read_csv('debug.csv', chunksize=1000, names=range(2504)): pass . Traceback (most recent call last): File "", line 1, in File "D:\programs\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1007, in __next__ return self.get_chunk() File "D:\programs\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1070, in get_chunk return self.read(nrows=size) File "D:\programs\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1036, in read ret = self._engine.read(nrows) File "D:\programs\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1848, in read data = self._reader.read(nrows) File "pandas\_libs\parsers.pyx", line 876, in pandas._libs.parsers.TextReader.read File "pandas\_libs\parsers.pyx", line 903, in pandas._libs.parsers.TextReader._read_low_memory File "pandas\_libs\parsers.pyx", line 945, in pandas._libs.parsers.TextReader._read_rows File "pandas\_libs\parsers.pyx", line 932, in pandas._libs.parsers.TextReader._tokenize_rows File "pandas\_libs\parsers.pyx", line 2112, in pandas._libs.parsers.raise_parser_error pandas.errors.ParserError: Error tokenizing data. C error: Buffer overflow caught - possible malformed input file. $ python3 Python 3.6.6 (default, Aug 13 2018, 18:24:23) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas >>> for chunk in pandas.read_csv('debug.csv', chunksize=1000, names=range(2504)): pass . Traceback (most recent call last): File "", line 1, in File "/usr/lib64/python3.6/site-packages/pandas/io/parsers.py", line 1007, in __next__ return self.get_chunk() File "/usr/lib64/python3.6/site-packages/pandas/io/parsers.py", line 1070, in get_chunk return self.read(nrows=size) File "/usr/lib64/python3.6/site-packages/pandas/io/parsers.py", line 1036, in read ret = self._engine.read(nrows) File "/usr/lib64/python3.6/site-packages/pandas/io/parsers.py", line 1848, in read data = self._reader.read(nrows) File "pandas/_libs/parsers.pyx", line 876, in pandas._libs.parsers.TextReader.read File "pandas/_libs/parsers.pyx", line 903, in pandas._libs.parsers.TextReader._read_low_memory File "pandas/_libs/parsers.pyx", line 945, in pandas._libs.parsers.TextReader._read_rows File "pandas/_libs/parsers.pyx", line 932, in pandas._libs.parsers.TextReader._tokenize_rows File "pandas/_libs/parsers.pyx", line 2112, in pandas._libs.parsers.raise_parser_error pandas.errors.ParserError: Error tokenizing data. C error: Buffer overflow caught - possible malformed input file. How to Solve Error Tokenizing Data on read_csv in Pandas
In this tutorial, we’ll see how to solve a common Pandas read_csv() error – Error Tokenizing Data. The full error is something like:
ParserError: Error tokenizing data. C error: Expected 2 fields in line 4, saw 4
The Pandas parser error when reading csv is very common but difficult to investigate and solve for big CSV files.
There could be many different reasons for this error:
- «wrong» data in the file
- different number of columns
- mixed data
- several data files stored as a single file
- nested separators
- different separator
- line terminators
Let’s cover the steps to diagnose and solve this error
Step 1: Analyze and Skip Bad Lines for Error Tokenizing Data
Suppose we have CSV file like:
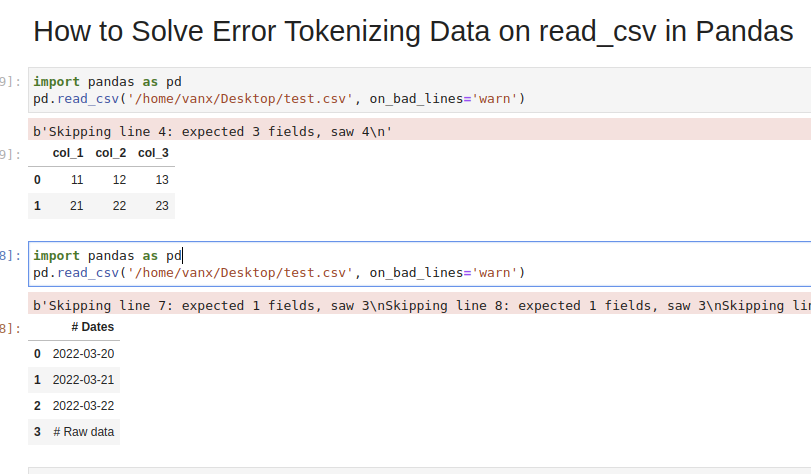
col_1,col_2,col_3 11,12,13 21,22,23 31,32,33,44which we are going to read by — read_csv() method:
import pandas as pd pd.read_csv('test.csv')ParserError: Error tokenizing data. C error: Expected 3 fields in line 4, saw 4We can easily see where the problem is. But what should be the solution in this case? Remove the 44 or add a new column? It depends on the context of this data.
If we don’t need the bad data we can use parameter — on_bad_lines=’skip’ in order to skip bad lines:
pd.read_csv('test.csv', on_bad_lines='skip')For older Pandas versions you may need to use: error_bad_lines=False which will be deprecated in future.
If we like to get warning messages for the problematic lines then on_bad_lines=’warn’ can be used.
Using warn instead of skip will produce:
pd.read_csv('test.csv', on_bad_lines='warn')b'Skipping line 4: expected 3 fields, saw 4\n'To find more about how to drop bad lines with read_csv() read the linked article.

Step 2: Use correct separator to solve Pandas tokenizing error
In some cases the reason could be the separator used to read the CSV file. In this case we can open the file and check its content.
If you don’t know how to read huge files in Windows or Linux — then check the article.
Depending on your OS and CSV file you may need to use different parameters like:
More information on the parameters can be found in Pandas doc for read_csv()
If the CSV file has tab as a separator and different line endings we can use:
import pandas as pd pd.read_csv('test.csv', sep='\t', lineterminator='\r\n')Note that delimiter is an alias for sep .
Step 3: Use different engine for read_csv()
The default C engine cannot automatically detect the separator, but the python parsing engine can.
There are 3 engines in the latest version of Pandas:
Python engine is the slowest one but the most feature-complete.
Using python as engine can help detecting the correct delimiter and solve the Error Tokenizing Data:
pd.read_csv('test.csv', engine='python')Step 4: Identify the headers to solve Error Tokenizing Data
Sometimes Error Tokenizing Data problem may be related to the headers.
For example multiline headers or additional data can produce the error. In this case we can skip the first or last few lines by:
pd.read_csv('test.csv', skiprows=1, engine='python')or skipping the last lines:
pd.read_csv('test.csv', skipfooter=1, engine='python')Note that we need to use python as the read_csv() engine for parameter — skipfooter .
In some cases header=None can help in order to solve the error:
pd.read_csv('test.csv', header=None)Step 5: Autodetect skiprows for read_csv()
Suppose we had CSV file like:
Dates 2022-03-20 2022-03-21 2022-03-22 Raw data col_1,col_2,col_3 11,12,13 21,22,23 31,32,33We are interested in reading the data stored after the line «Raw data». If this line is changing for different files and we need to autodetect the line.
To search for a line containing some match in Pandas we can use a separator which is not present in the file «@@».
In case of multiple occurrences we can get the biggest index. To autodetect skiprows parameter in Pandas read_csv() use:
df_temp = pd.read_csv('test.csv', sep='@@', engine='python', names=['col']) ix_last_start = df_temp[df_temp['col'].str.contains('# Raw data')].index.max()Finding the starting line can be done by visually inspecting the file in the text editor.
Then we can simply read the file by:
df_analytics = pd.read_csv(file, skiprows=ix_last_start)Conclusion
In this post we saw how to investigate the error:
ParserError: Error tokenizing data. C error: Expected 3 fields in line 4, saw 4We covered different reasons and solutions in order to read any CSV file with Pandas.
Some solutions will warn and skip problematic lines. Others will try to resolve the problem automatically.
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.