Python Pandas read_csv: Load csv/text file

Learn how to read CSV file using python pandas. CSV (Comma-Separated Values) file format is generally used for storing data.
Pandas is the most popular data manipulation package in Python, and DataFrames are the Pandas data type for storing tabular 2D data. Reading data from csv files, and writing data to CSV files using Python is an important skill for any analyst or data scientist.
Table of Contents
1. Pandas read_csv() Syntax
The syntax of DataFrame to_csv() function and some of the important parameters are:
pandas.read_excel(io, sheet_name, header, usecols, nrows)| Sr.No | Parameters Description |
|---|---|
| 1 | filepath_or_buffer the file path from where you want to read the data. This could be a URL path or, could be a local system file path. |
| 2 | sep separator or delimiter to use. Default is a comma “,”. If sep is set to None then, automatically determined. |
| 3 | header default is ‘infer’. Explicitly pass header=0 to replace existing names while reading csv. Pass Header = 1 to consider the second line of the dataset as a header. |
| 4 | infer_datetime_format default False, If True and parse_dates is enabled for a column, pandas will attempt to infer the format of the datetime. If inferred, pandas read_csv will parse the data type of that column into datetime quickly. The parsing speed can be increased by 5-10 times. |
| 5 | prefix optional, prefix can be added to column numbers when there is no header, e.g. by adding prefix=”column”, dataframe column names will now become column0, column1, column2, etc. |
For complete list of read_csv parameters refer to official documentation.
2. Read CSV file using Pandas (Example)
Let’s review a full example:
- Create a DataFrame from scratch that we will be importing and save it in csv
- Load the DataFrame from that saved CSV file
import pandas as pd # Create a dataframe raw_data = df = pd.DataFrame(raw_data) df #Save the dataframe df.to_csv(r'Example1.csv')We have the following data about students:
| first_name | degree | age | |
|---|---|---|---|
| 0 | Sam | PhD | 25 |
| 1 | Ziva | MBA | 29 |
| 2 | Kia | 19 | |
| 3 | Robin | MS | 21 |
Read CSV file into Pandas DataFrame (Explained)
Now, let’s see the steps read the csv file DataFrame you just created to a csv file.
Step 1: Enter the path and filename where the csv file is stored.
pd.read_csv(r‘ D:\Python\Tutorial\ Example1 .csv ‘)
Notice that path is highlighted with 3 different colors:
- The blue part represents the pathname where you want to save the file.
- The green part is the name of the file you want to import.
- The purple part represents the file type or file extension. Use ‘.csv’ if your file is a CSV file or ‘.txt’ in case of a text file.
Modify the Python above code to reflect the path where the CSV file is stored on your computer.
Note: If you have used above code to save the file, you might have noticed that no file path was provided. In that case, the file automatically stored at the current working directory. To find current directory path use below code:
# Current working directory import os print(os.getcwd()) # Display all files present in the current working directory print(os.listdir(os.getcwd()))OUTPUT: D:\Python\Tutorial\ ['Example1.csv', 'Example2.csv']
Find out how to read multiple files in a folder(directory) here.
Step 2: Enter the following code and make the necessary changes to your path to read the CSV file.
import pandas as pd # Read csv file df = pd.read_csv(r'D:\Python\Tutorial\Example1.csv') dfSnapshot of Data Representation in CSV files
On the left side of image same csv file is opened in Microsoft Excel and Text Editor (can be Notepad++, Sublime Text, TextEdit on Mac, etc.)
On the right side same csv file is opened in Juptyter using pandas read_csv.
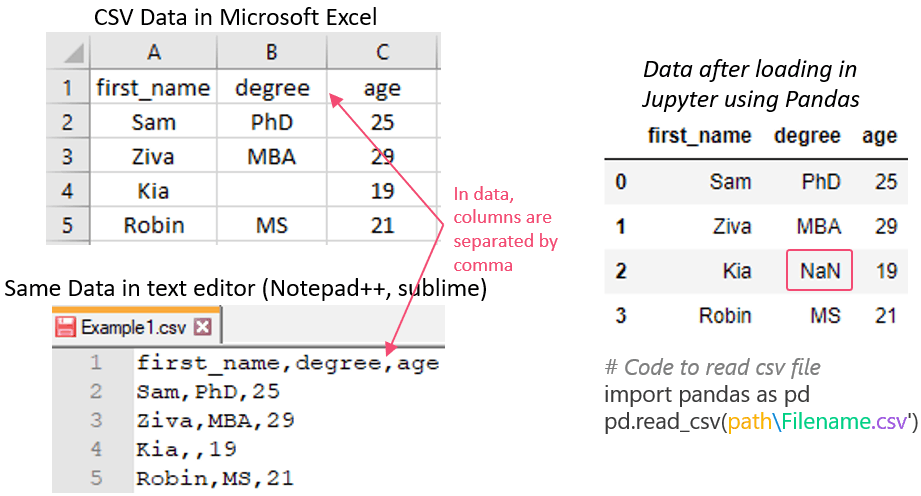
In CSV (Comma-Separated Values) tabular data is stored in text format, where commas are used to separate the different columns. So, in the below image, delimiter (or separator) is a comma. Other alternatives to comma include tab (“\t”) and semi-colon (“;”). Tab-separate files are known as TSV (Tab-Separated Values) files.
3. Common Errors and Troubleshooting
Listing down the common error you can face while loading data from CSV files into Pandas dataframe will be:
- FileNotFoundError: File b’filename.csv’ does not exist
- Reason: File Not Found error typically occurs when there is an issue with the file path (or directory) or file name.
- Fix: Check file path, file name, and file extension.
- UnicodeDecodeError: ‘utf-8’ codec can’t decode byte in position : invalid continuation byte
- Reason: Unicode Decode Error usually caused by the encoding of the file, and happens when you have a file with non-standard characters. utf-8 code error usually comes when the range of numeric values exceeding 0 to 127.
- Fix:
- While reading CSV use encoding parameter equals to ‘Latin-1’ or ‘ISO-8859-1’ pd.read_csv(‘filename.csv’,encoding=’latin-1′) or,
- Open file in a text editor and again save it with encoding ‘UTF-8’.
- pandas.parser.CParserError: Error tokenizing data. C error: Calling read(nbytes) on source failed. Try engine=’python’.
- Reason: Parse Errors generally caused because of the raw data.
- Fix: Make the engine parameter equals to ‘python’ pd.read_csv(‘filename.csv’, engine=’python’)
- pandas.io.common.CParserError: Error tokenizing data. C error: out of memory or Python(1284,0x7fffa37773c0) malloc: *** mach_vm_map(size=18446744071562067968) failed (error code=3)
- Reason: This error occurs due to out of memory issues of RAM.
- Fix: Use chunksize parameter while reading csv file pd.read_csv(‘filename.csv’,chunksize =5000,lineterminator=’\r’)
- pandas.io.common.CParserError: Error tokenizing data. C error: Expected 7 fields in line 4587, saw 8
- Reason: This error occurs when one of the rows has different number of fields in the data.
- Fix: Add argument error_bad_lines=False while loading csv pd.read_csv(‘filename.csv, error_bad_lines=False)
Conclusion
We have covered the steps needed to read a csv or txt file using pandas read_csv function.