- Handling encoding issues with Unicode normalisation in Python
- Example
- Encoding options
- Text normalisation
- Unicode and composed characters
- Composition and Decomposition
- Canonical and Compatibility Equivalence
- Applying Unicode normalisation forms
- Improve your Python skills, learn from the experts!
- References
- Subscribe to our newsletter
- 10.9. File Encoding¶
- 10.9.1. Str vs Bytes¶
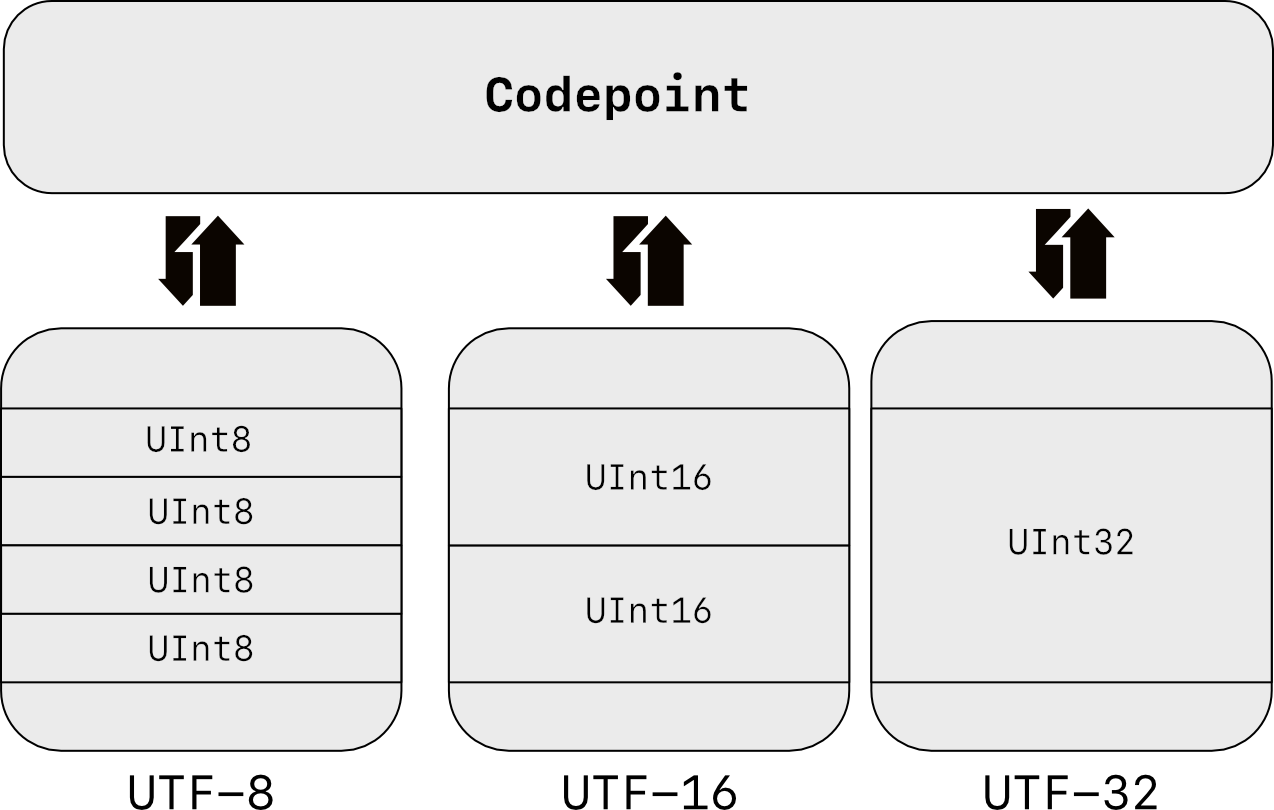
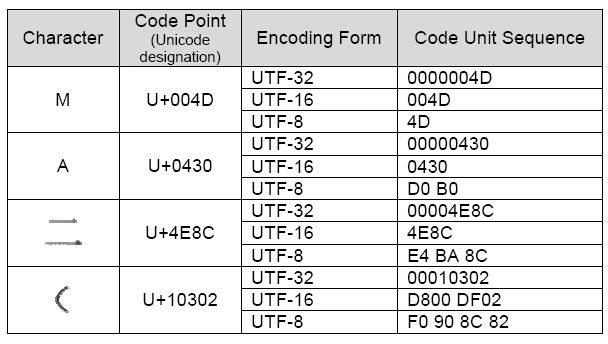
- 10.9.2. UTF-8¶
- 10.9.3. Unicode Encode Error¶
- 10.9.4. Unicode Decode Error¶
- 10.9.5. Escape Characters¶
Handling encoding issues with Unicode normalisation in Python
When reading and writing from various systems, it is not uncommon to encounter encoding issues when the systems have different locales. In this post I show several options for handling such issues.
Example
Say you have a field containing names and there’s a Czech name «Mořic» containing an r with caron, which you have to export to a csv with Windows-1252 1 encoding. This will fail:
>>> example = 'Mořic' >>> example.encode('WINDOWS-1252') UnicodeEncodeError: 'charmap' codec can't encode character '\u0159' in position 2: character maps to
Unfortunately, Windows-1252 does not support this character and thus an exception is raised, so we need a way to handle such encoding issues.
Encoding options
Since Python 3.3 2 , the str type is represented in Unicode. Unicode characters have no representation in bytes; this is what character encoding does – a mapping from Unicode characters to bytes. Each encoding handles the mapping differently, and not all encodings supports all Unicode characters, possibly resulting in issues when converting from one encoding to the other. Only the UTF family supports all Unicode characters. The most commonly used encoding is UTF-8, so stick with that whenever possible.
With str.encode you have several error handling options. The default signature is str.encode(encoding=»utf-8″, errors=»strict») . Given the example «Mořic», the error options are:
| Errors value | Description | Result |
|---|---|---|
| strict | Encoding errors raise a UnicodeError (default). | Exception |
| ignore | Ignore erroneous characters. | Moic |
| replace | Replace erroneous characters with ?. | Mo?ic |
| xmlcharrefreplace | Replace erroneous characters with XML character reference. | Mořic |
| backslashreplace | Replace erroneous characters with backslashed escape sequence. | Mo\\u0159ic |
| namereplace | Replace erroneous characters with \N <. >escape sequence. | Mo\\Nic |
Text normalisation
Normalisation can be applied in four forms:
| Normal Form | Full Name |
|---|---|
| NFD | Normalisation Form Canonical Decomposition |
| NFC | Normalisation Form Canonical Composition |
| NFKD | Normalisation Form Compatibility Decomposition |
| NFKC | Normalisation Form Compatibility Composition |
To understand Unicode normal forms, we need a bit of background information first.
Unicode and composed characters
In Unicode, characters are mapped to so-called code points. Every character in the Unicode universe 3 is expressed by a code point written as U+ and four hexadecimal digits; e.g. U+0061 represents lowercase «a».
The Unicode standard provides two ways for specifying composed characters:
- Decomposed: as a sequence of combining characters
- Precomposed: as a single combined character
For example, the character «ã» (lowercase a with tilde) in decomposed form is given as U+0061 (a) U+0303 (˜), or in precomposed form as U+00E3 (ã).
Composition and Decomposition
Composition is the process of combining multiple characters to form a single character, typically a base character and one or more marks 4 . Decomposition is the reverse; splitting a composed character into multiple characters.
Before diving into normalisation, let’s define a function for printing the Unicode code points for each character in a string:
>>> def unicodes(string): >>> return ' '.join('U+'.format(ord(c)) for c in string) >>> >>> example = 'Mořic' >>> print(unicodes(example)) U+004D U+006F U+0159 U+0069 U+0063
Canonical and Compatibility Equivalence
A problem arises when characters have multiple representations. For example the Ångström symbol Å (one Ångström unit equals one ten-billionth of a meter) can be represented in three ways:
How can we determine if strings are equal when their decomposed forms are different? Unicode equivalence is defined in two ways:
When a character from different code points has the same appearance and meaning, it is considered canonically equivalent. For example all three representations of the Ångström example above have the same appearance and meaning, and are thus canonically equivalent.
Compatibility equivalence is defined as a sequence of code points which only have the same meaning, but are not equal visually. For example fractions are considered compatible equivalent: ¼ (U+00BC) and 1⁄4 (U+0031 U+2044 U+0034) do not have the same visual appearance, but do have the same meaning and are thus compatibility equivalent.
Compatibility equivalence is considered a weaker equivalence form and a subset of canonical equivalence. When a character is canonically equivalent, it is also compatibility equivalent, but not vice versa.
Applying Unicode normalisation forms
Now, with this background information, we can get to the Unicode normal forms. Given the example «Mořic» at the start, we can apply normalisation before encoding this string with Windows-1252:
>>> import unicodedata >>> >>> def unicodes(string): >>> return ' '.join('U+'.format(ord(c)) for c in string) >>> >>> example = "Mořic" >>> >>> print(unicodes(example)) U+004D U+006F U+0159 U+0069 U+0063 # 5 Unicode code points, so the ř is given in precomposed form >>> example.encode("WINDOWS-1252") UnicodeEncodeError: 'charmap' codec cant encode character '\u0159' in position 2: character maps to undefined> # Windows-1252 cannot encode U+0159 (ř) >>> nfd_example = unicodedata.normalize("NFD", example) >>> print(unicodes(nfd_example)) U+004D U+006F U+0072 U+030C U+0069 U+0063 # 6 Unicode code points, so the ř is given in decomposed form >>> print(nfd_example) Mořic # Python shell with UTF-8 encoding still displays the r with caret >>> nfd_example.encode("WINDOWS-1252") UnicodeEncodeError: 'charmap' codec cant encode character '\u030c' in position 3: character maps to undefined> # Windows-1252 can now encode U+0072 (r), but not U+030C (ˇ) >>> print(nfd_example.encode('WINDOWS-1252', 'ignore')) Moric # Successfully encoded Windows-1252 and ignored U+030C (ˇ)
That’s it! With unicodedata.normalize(«NFD», «Mořic»).encode(‘WINDOWS-1252’, ‘ignore’) we can normalise first and then encode Windows-1252, ignoring the unknown characters for Windows-1252, resulting in Moric . I like this alternative, usually people are okay with this since it doesn’t mingle the data too much and keeps it readable.
Improve your Python skills, learn from the experts!
At GoDataDriven we offer a host of Python courses from beginner to expert, taught by the very best professionals in the field. Join us and level up your Python game:
- Python Essentials – Great if you are just starting with Python.
- Data Science with Python Foundation – Want to make the step up from data analysis and visualization to true data science? This is the right course.
- Advanced Data Science with Python – Learn to productionize your models like a pro and use Python for machine learning.
References
- Windows-1252 was the first default character set in Microsoft Windows and thus you will encounter it in lots of legacy Windows systems. The default for Windows systems nowadays is UTF-16. ↩
- Pre-Python 3.3, str was a byte string (sequence of bytes in certain encoding, default ASCII) and unicode , a Unicode string. ↩
- More precisely, the “Unicode universe” is the Unicode Character Database (UCD), which contains all Unicode characters and its properties and metadata. ↩
- Unicode categorises characters. Each category is denoted by an abbreviation of two letters, first an uppercase and second a lowercase letter. The uppercase letters shows the major category, the lowercase the minor category. The major category for marks is “M”. ↩
Subscribe to our newsletter
Stay up to date on the latest insights and best-practices by registering for the GoDataDriven newsletter.
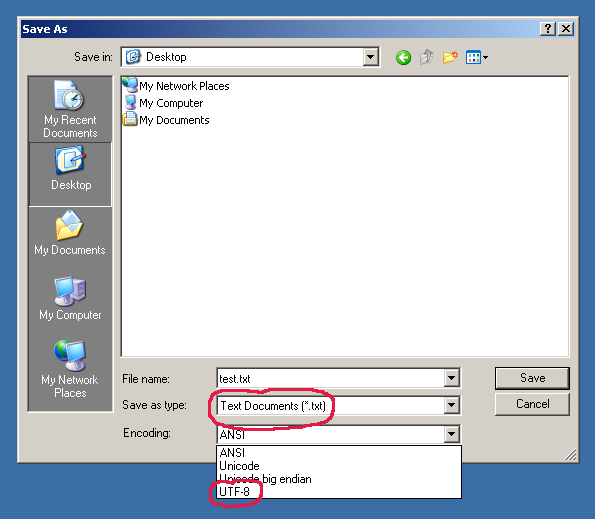
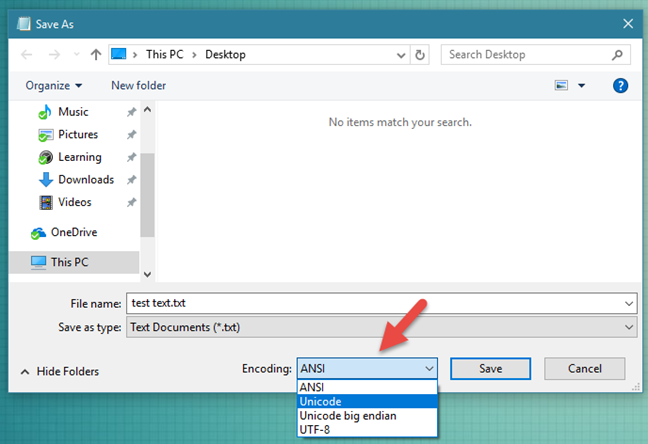
10.9. File Encoding¶
- utf-8 — a.k.a. Unicode — international standard (should be always used!)
- iso-8859-1 — ISO standard for Western Europe and USA
- iso-8859-2 — ISO standard for Central Europe (including Poland)
- cp1250 or windows-1250 — Central European encoding on Windows
- cp1251 or windows-1251 — Eastern European encoding on Windows
- cp1252 or windows-1252 — Western European encoding on Windows
- ASCII — ASCII characters only
- Since Windows 10 version 1903, UTF-8 is default encoding for Notepad!

10.9.1. Str vs Bytes¶
- That was a big change in Python 3
- In Python 2, str was bytes
- In Python 3, str is unicode (UTF-8)
>>> text = 'Księżyc' >>> text 'Księżyc'
>>> text = b'Księżyc' Traceback (most recent call last): SyntaxError: bytes can only contain ASCII literal characters
Default encoding is UTF-8 . Encoding names are case insensitive. cp1250 and windows-1250 are aliases the same codec:
>>> text = 'Księżyc' >>> >>> text.encode() b'Ksi\xc4\x99\xc5\xbcyc' >>> text.encode('utf-8') b'Ksi\xc4\x99\xc5\xbcyc' >>> text.encode('iso-8859-2') b'Ksi\xea\xbfyc' >>> text.encode('cp1250') b'Ksi\xea\xbfyc' >>> text.encode('windows-1250') b'Ksi\xea\xbfyc'
Note the length change while encoding:
>>> text = 'Księżyc' >>> text 'Księżyc' >>> len(text) 7
>>> text = 'Księżyc'.encode() >>> text b'Ksi\xc4\x99\xc5\xbcyc' >>> len(text) 9
Note also, that those characters produce longer output:
But despite being several «characters» long, the length is different:
Here’s the output of all Polish diacritics (accented characters) with their encoding:
>>> 'ą'.encode() b'\xc4\x85' >>> 'ć'.encode() b'\xc4\x87' >>> 'ę'.encode() b'\xc4\x99' >>> 'ł'.encode() b'\xc5\x82' >>> 'ń'.encode() b'\xc5\x84' >>> 'ó'.encode() b'\xc3\xb3' >>> 'ś'.encode() b'\xc5\x9b' >>> 'ż'.encode() b'\xc5\xbc' >>> 'ź'.encode() b'\xc5\xba'
Note also a different way of iterating over bytes :
>>> text = 'Księżyc' >>> >>> for character in text: . print(character) K s i ę ż y c >>> >>> for character in text.encode(): . print(character) 75 115 105 196 153 197 188 121 99
10.9.2. UTF-8¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='utf-8') as file: . file.write('José Jiménez') 12 >>> >>> with open(FILE, encoding='utf-8') as file: . print(file.read()) José Jiménez
10.9.3. Unicode Encode Error¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='cp1250') as file: . file.write('José Jiménez') 12
10.9.4. Unicode Decode Error¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='utf-8') as file: . file.write('José Jiménez') 12 >>> >>> with open(FILE, encoding='cp1250') as file: . print(file.read()) JosĂ© JimĂ©nez
10.9.5. Escape Characters¶
- \r\n — is used on windows
- \n — is used everywhere else
- More information in Builtin Printing
- Learn more at https://en.wikipedia.org/wiki/List_of_Unicode_characters

Frequently used escape characters:
- \n — New line (ENTER)
- \t — Horizontal Tab (TAB)
- \’ — Single quote ‘ (escape in single quoted strings)
- \» — Double quote » (escape in double quoted strings)
- \\ — Backslash \ (to indicate, that this is not escape char)
Less frequently used escape characters:
- \a — Bell (BEL)
- \b — Backspace (BS)
- \f — New page (FF — Form Feed)
- \v — Vertical Tab (VT)
- \uF680 — Character with 16-bit (2 bytes) hex value F680
- \U0001F680 — Character with 32-bit (4 bytes) hex value 0001F680
- \o755 — ASCII character with octal value 755
- \x1F680 — ASCII character with hex value 1F680
>>> a = '\U0001F9D1' # 🧑 >>> b = '\U0000200D' # '' >>> c = '\U0001F680' # 🚀 >>> >>> astronaut = a + b + c >>> print(astronaut) 🧑🚀