Scalars#
Python defines only one type of a particular data class (there is only one integer type, one floating-point type, etc.). This can be convenient in applications that don’t need to be concerned with all the ways data can be represented in a computer. For scientific computing, however, more control is often needed.
In NumPy, there are 24 new fundamental Python types to describe different types of scalars. These type descriptors are mostly based on the types available in the C language that CPython is written in, with several additional types compatible with Python’s types.
Array scalars have the same attributes and methods as ndarrays . [ 1 ] This allows one to treat items of an array partly on the same footing as arrays, smoothing out rough edges that result when mixing scalar and array operations.
Array scalars live in a hierarchy (see the Figure below) of data types. They can be detected using the hierarchy: For example, isinstance(val, np.generic) will return True if val is an array scalar object. Alternatively, what kind of array scalar is present can be determined using other members of the data type hierarchy. Thus, for example isinstance(val, np.complexfloating) will return True if val is a complex valued type, while isinstance(val, np.flexible) will return true if val is one of the flexible itemsize array types ( str_ , bytes_ , void ).
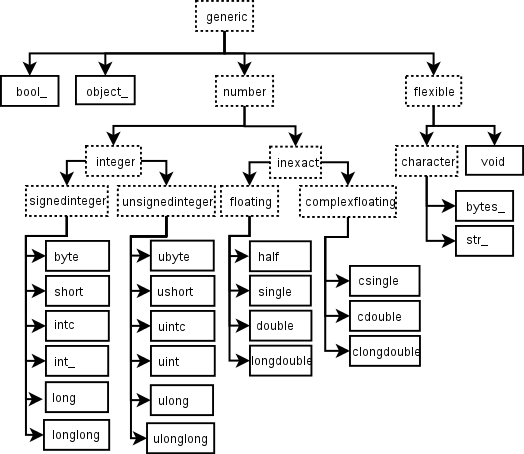
[ 1 ]
However, array scalars are immutable, so none of the array scalar attributes are settable.
Built-in scalar types#
The built-in scalar types are shown below. The C-like names are associated with character codes, which are shown in their descriptions. Use of the character codes, however, is discouraged.
Some of the scalar types are essentially equivalent to fundamental Python types and therefore inherit from them as well as from the generic array scalar type:
Data type objects ( dtype )#
A data type object (an instance of numpy.dtype class) describes how the bytes in the fixed-size block of memory corresponding to an array item should be interpreted. It describes the following aspects of the data:
- Type of the data (integer, float, Python object, etc.)
- Size of the data (how many bytes is in e.g. the integer)
- Byte order of the data ( little-endian or big-endian )
- If the data type is structured data type , an aggregate of other data types, (e.g., describing an array item consisting of an integer and a float),
- what are the names of the “ fields ” of the structure, by which they can be accessed ,
- what is the data-type of each field , and
- which part of the memory block each field takes.
To describe the type of scalar data, there are several built-in scalar types in NumPy for various precision of integers, floating-point numbers, etc. An item extracted from an array, e.g., by indexing, will be a Python object whose type is the scalar type associated with the data type of the array.
Note that the scalar types are not dtype objects, even though they can be used in place of one whenever a data type specification is needed in NumPy.
Structured data types are formed by creating a data type whose field contain other data types. Each field has a name by which it can be accessed . The parent data type should be of sufficient size to contain all its fields; the parent is nearly always based on the void type which allows an arbitrary item size. Structured data types may also contain nested structured sub-array data types in their fields.
Finally, a data type can describe items that are themselves arrays of items of another data type. These sub-arrays must, however, be of a fixed size.
If an array is created using a data-type describing a sub-array, the dimensions of the sub-array are appended to the shape of the array when the array is created. Sub-arrays in a field of a structured type behave differently, see Field access .
Sub-arrays always have a C-contiguous memory layout.
A simple data type containing a 32-bit big-endian integer: (see Specifying and constructing data types for details on construction)
>>> dt = np.dtype('>i4') >>> dt.byteorder '>' >>> dt.itemsize 4 >>> dt.name 'int32' >>> dt.type is np.int32 True
The corresponding array scalar type is int32 .
A structured data type containing a 16-character string (in field ‘name’) and a sub-array of two 64-bit floating-point number (in field ‘grades’):
>>> dt = np.dtype([('name', np.unicode_, 16), ('grades', np.float64, (2,))]) >>> dt['name'] dtype('
Items of an array of this data type are wrapped in an array scalar type that also has two fields:
>>> x = np.array([(‘Sarah’, (8.0, 7.0)), (‘John’, (6.0, 7.0))], dtype=dt) >>> x[1] (‘John’, [6., 7.]) >>> x[1][‘grades’] array([6., 7.]) >>> type(x[1]) >>> type(x[1][‘grades’])
Specifying and constructing data types#
Whenever a data-type is required in a NumPy function or method, either a dtype object or something that can be converted to one can be supplied. Such conversions are done by the dtype constructor:
Create a data type object.
What can be converted to a data-type object is described below:
The 24 built-in array scalar type objects all convert to an associated data-type object. This is true for their sub-classes as well.
Note that not all data-type information can be supplied with a type-object: for example, flexible data-types have a default itemsize of 0, and require an explicitly given size to be useful.
>>> dt = np.dtype(np.int32) # 32-bit integer >>> dt = np.dtype(np.complex128) # 128-bit complex floating-point number
The generic hierarchical type objects convert to corresponding type objects according to the associations:
Deprecated since version 1.19: This conversion of generic scalar types is deprecated. This is because it can be unexpected in a context such as arr.astype(dtype=np.floating) , which casts an array of float32 to an array of float64 , even though float32 is a subdtype of np.floating .
Several python types are equivalent to a corresponding array scalar when used to generate a dtype object:
Note that str corresponds to UCS4 encoded unicode strings, while string is an alias to bytes_ . The name np.unicode_ is also available as an alias to np.str_ , see Note on string types .
>>> dt = np.dtype(float) # Python-compatible floating-point number >>> dt = np.dtype(int) # Python-compatible integer >>> dt = np.dtype(object) # Python object
All other types map to object_ for convenience. Code should expect that such types may map to a specific (new) dtype in the future.
Any type object with a dtype attribute: The attribute will be accessed and used directly. The attribute must return something that is convertible into a dtype object.
Each built-in data-type has a character code (the updated Numeric typecodes), that uniquely identifies it.
>>> dt = np.dtype('b') # byte, native byte order >>> dt = np.dtype('>H') # big-endian unsigned short >>> dt = np.dtype(') # little-endian single-precision float >>> dt = np.dtype('d') # double-precision floating-point number
The first character specifies the kind of data and the remaining characters specify the number of bytes per item, except for Unicode, where it is interpreted as the number of characters. The item size must correspond to an existing type, or an error will be raised. The supported kinds are
Data type objects ( dtype )#
A data type object (an instance of numpy.dtype class) describes how the bytes in the fixed-size block of memory corresponding to an array item should be interpreted. It describes the following aspects of the data:
- Type of the data (integer, float, Python object, etc.)
- Size of the data (how many bytes is in e.g. the integer)
- Byte order of the data ( little-endian or big-endian )
- If the data type is structured data type , an aggregate of other data types, (e.g., describing an array item consisting of an integer and a float),
- what are the names of the “ fields ” of the structure, by which they can be accessed ,
- what is the data-type of each field , and
- which part of the memory block each field takes.
To describe the type of scalar data, there are several built-in scalar types in NumPy for various precision of integers, floating-point numbers, etc. An item extracted from an array, e.g., by indexing, will be a Python object whose type is the scalar type associated with the data type of the array.
Note that the scalar types are not dtype objects, even though they can be used in place of one whenever a data type specification is needed in NumPy.
Structured data types are formed by creating a data type whose field contain other data types. Each field has a name by which it can be accessed . The parent data type should be of sufficient size to contain all its fields; the parent is nearly always based on the void type which allows an arbitrary item size. Structured data types may also contain nested structured sub-array data types in their fields.
Finally, a data type can describe items that are themselves arrays of items of another data type. These sub-arrays must, however, be of a fixed size.
If an array is created using a data-type describing a sub-array, the dimensions of the sub-array are appended to the shape of the array when the array is created. Sub-arrays in a field of a structured type behave differently, see Field access .
Sub-arrays always have a C-contiguous memory layout.
A simple data type containing a 32-bit big-endian integer: (see Specifying and constructing data types for details on construction)
>>> dt = np.dtype('>i4') >>> dt.byteorder '>' >>> dt.itemsize 4 >>> dt.name 'int32' >>> dt.type is np.int32 True
The corresponding array scalar type is int32 .
A structured data type containing a 16-character string (in field ‘name’) and a sub-array of two 64-bit floating-point number (in field ‘grades’):
>>> dt = np.dtype([('name', np.unicode_, 16), ('grades', np.float64, (2,))]) >>> dt['name'] dtype('
Items of an array of this data type are wrapped in an array scalar type that also has two fields:
>>> x = np.array([(‘Sarah’, (8.0, 7.0)), (‘John’, (6.0, 7.0))], dtype=dt) >>> x[1] (‘John’, [6., 7.]) >>> x[1][‘grades’] array([6., 7.]) >>> type(x[1]) >>> type(x[1][‘grades’])
Specifying and constructing data types#
Whenever a data-type is required in a NumPy function or method, either a dtype object or something that can be converted to one can be supplied. Such conversions are done by the dtype constructor:
Create a data type object.
What can be converted to a data-type object is described below:
The 24 built-in array scalar type objects all convert to an associated data-type object. This is true for their sub-classes as well.
Note that not all data-type information can be supplied with a type-object: for example, flexible data-types have a default itemsize of 0, and require an explicitly given size to be useful.
>>> dt = np.dtype(np.int32) # 32-bit integer >>> dt = np.dtype(np.complex128) # 128-bit complex floating-point number
The generic hierarchical type objects convert to corresponding type objects according to the associations:
Deprecated since version 1.19: This conversion of generic scalar types is deprecated. This is because it can be unexpected in a context such as arr.astype(dtype=np.floating) , which casts an array of float32 to an array of float64 , even though float32 is a subdtype of np.floating .
Several python types are equivalent to a corresponding array scalar when used to generate a dtype object:
Note that str corresponds to UCS4 encoded unicode strings, while string is an alias to bytes_ . The name np.unicode_ is also available as an alias to np.str_ , see Note on string types .
>>> dt = np.dtype(float) # Python-compatible floating-point number >>> dt = np.dtype(int) # Python-compatible integer >>> dt = np.dtype(object) # Python object
All other types map to object_ for convenience. Code should expect that such types may map to a specific (new) dtype in the future.
Any type object with a dtype attribute: The attribute will be accessed and used directly. The attribute must return something that is convertible into a dtype object.
Each built-in data-type has a character code (the updated Numeric typecodes), that uniquely identifies it.
>>> dt = np.dtype('b') # byte, native byte order >>> dt = np.dtype('>H') # big-endian unsigned short >>> dt = np.dtype(') # little-endian single-precision float >>> dt = np.dtype('d') # double-precision floating-point number
The first character specifies the kind of data and the remaining characters specify the number of bytes per item, except for Unicode, where it is interpreted as the number of characters. The item size must correspond to an existing type, or an error will be raised. The supported kinds are